在 python-docx 裡有兩個東西都叫 Document,但它們角色不同:
- from docx import Document
這個 Document 通常是「入口函式(factory function)」:
用來 建立空白文件 或 讀取 docx。 - from docx.document import Document
這個 Document 才是「真正的類別(class/type)」:
用來做 isinstance() 判斷、type hint。
因此才會出現常見錯誤:把函式拿去當 isinstance() 的第二參數。
最推薦的寫法:用別名把角色分清楚
from docx import Document as load_doc
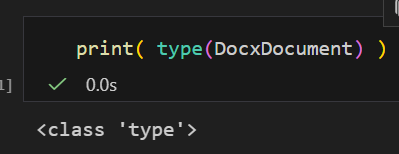
from docx.document import Document as DocxDocument
# 讀/建文件:用 load_doc
doc = load_doc()
# 判斷型別:用 DocxDocument
print(type(doc))
print(isinstance(doc, DocxDocument)) # True可以在 Jupyter 直接驗證(會印出函式 vs 類別)
from docx import Document
from docx.document import Document as DocxDocument
print("Document =", Document)
print("type(Document) =", type(Document))
doc = Document()
print("type(doc) =", type(doc))
print("isinstance(doc, DocxDocument) =", isinstance(doc, DocxDocument))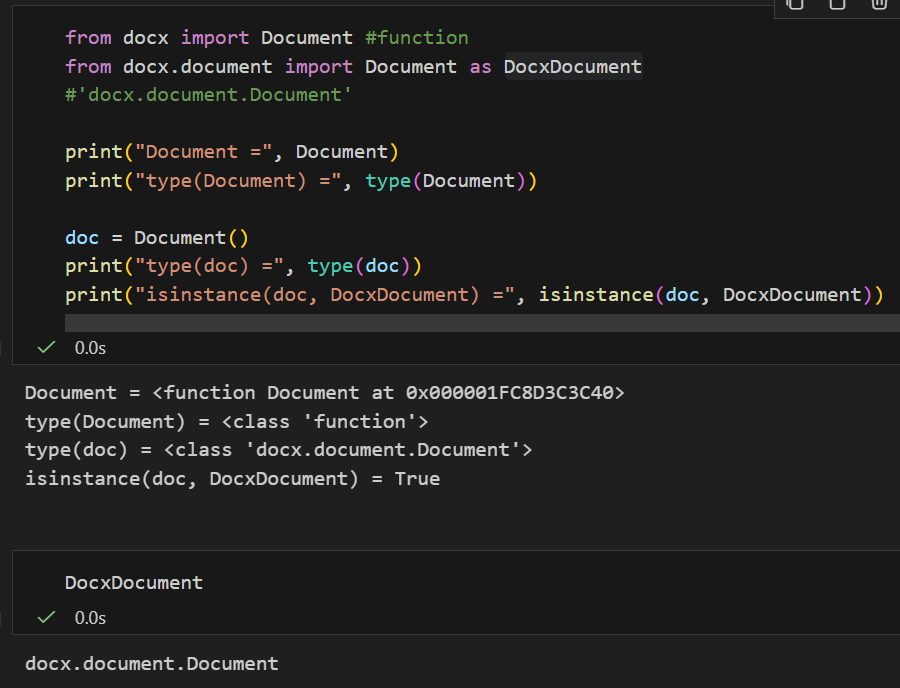
推薦hahow線上學習python: https://igrape.net/30afN

 as c:")

")
 #一次取得dirname , basename 可以取代os.path.dirname() + os.path.basename() ;分離主/副檔名: os.path.splitext() #split ext ; os.path.join( folder, fname) #將folder, fname合併為完整的路徑")
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/12/20221206184635_4.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)")
 計算c字元在s字串中出現了幾次,字串跟list都可以.count()")

 ; os.makedirs() ; 有何差別?")
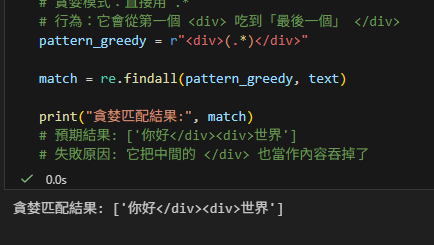

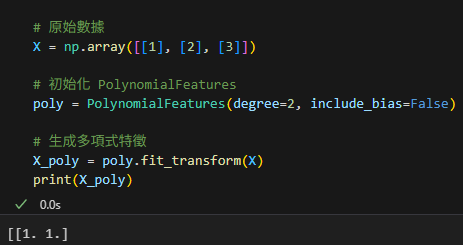

近期留言