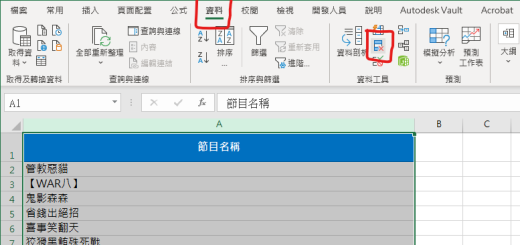
!pip install opencc-python-reimplemented #安裝套件
code:
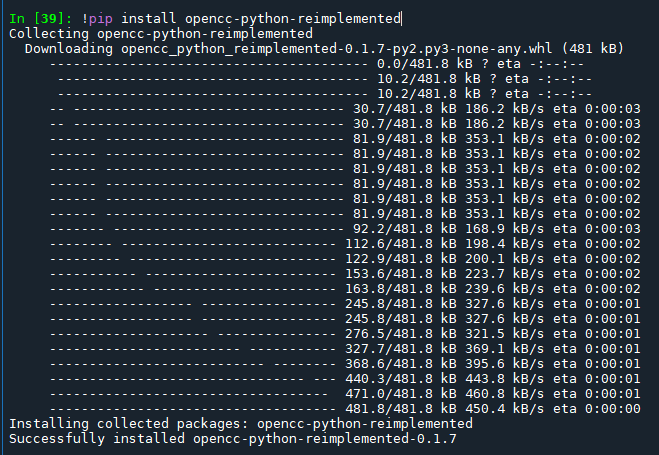
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 18 21:29:41 2023
@author: SavingKing
"""
from opencc import OpenCC
text1="我去过清华大学和交通大学,打印机、光盘、内存。"
text2="我去過清華大學和交通大學,印表機、光碟、記憶體。"
openCC = OpenCC('s2t') #opencc.opencc.OpenCC
# 啟動OpenCC 並設定為簡轉繁
line = openCC.convert(text1) #str
print(" "+text1)
# 轉換
# 輸出「...交通大学打印机光盘内存」
print("s2t :"+line)
# 輸出「...交通大學打印機光盤內存」
line =openCC.set_conversion('s2twp')
#NoneType #"line =" "多餘的"
line = openCC.convert(text1)
# 設定為簡轉台灣繁體用字
# 轉換
# 輸出「...交通大學印表機光碟記憶體」
print("s2twp:"+line)
line =openCC.set_conversion('t2s')
##NoneType #"line =" "多餘的"
line = openCC.convert( text2 )
# 設定為繁轉簡
print(" "+text2)
print("t2s :"+line)
# 轉換
# 輸出「...交交通大學印表機光碟記憶體」
line =openCC.set_conversion('tw2sp')
line = openCC.convert(text2)
# 輸出「...交通大学印表机光碟记忆体」
# 設定為繁轉簡用字
print("tw2sp:"+line)
# 轉換
# 輸出「...交通大学打印机光盘内存」
輸出結果:
推薦hahow線上學習python: https://igrape.net/30afN
code:
from opencc import OpenCC # 匯入 OpenCC 函式庫
text1="我去过清华大学和交通大学,打印机、光盘、内存。"
text2="我去過清華大學和交通大學,印表機、光碟、記憶體。"
openCC = OpenCC('s2t') # 啟動 OpenCC 並設定為簡轉繁
line = openCC.convert(text1) # 轉換
print(" "+text1) # 輸出「...交通大学打印机光盘内存」
print("s2t :"+line) # 輸出「...交通大學打印機光盤內存」
openCC.set_conversion('s2twp') # 設定為簡轉台灣繁體用字
line = openCC.convert(text1) # 轉換
print("s2twp:"+line) # 輸出「...交通大學印表機光碟記憶體」
print("\n")
openCC.set_conversion('t2s') # 設定為繁轉簡
line = openCC.convert(text2) # 轉換
print(" "+text2) # 輸出「...交交通大學印表機光碟記憶體」
print("t2s :"+line) # 輸出「...交通大学印表机光碟记忆体」
openCC.set_conversion('tw2sp') # 設定為繁轉簡用字
line = openCC.convert(text2) # 轉換
print("tw2sp:"+line) # 輸出「...交通大学打印机光盘内存」輸出結果:
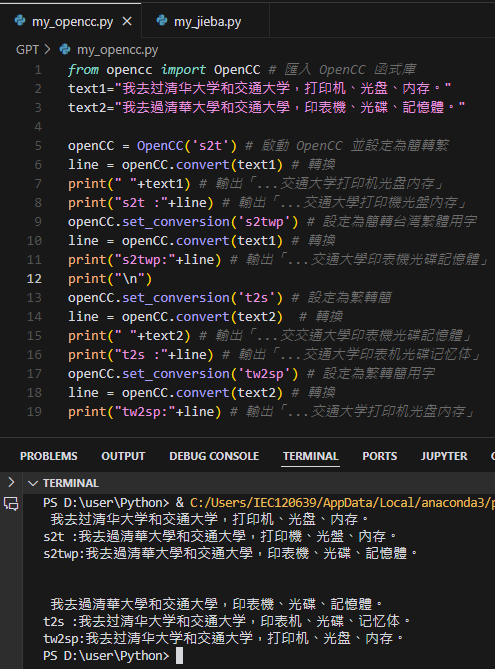
• 我去过清华大学和交通大学,打印机、光盘、内存。
•s2t :我去過清華大學和交通大學,打印機、光盤、內存。
(單純的簡轉繁)
•s2twp:我去過清華大學和交通大學,印表機、光碟、記憶體。
(Simplified Chinese to Traditional Chinese with Taiwan Phrases
不僅簡轉繁,用語也變了)
• 我去過清華大學和交通大學,印表機、光碟、記憶體。
•t2s :我去过清华大学和交通大学,印表机、光碟、记忆体。
(單純的繁轉簡)
•tw2sp:我去过清华大学和交通大学,打印机、光盘、内存。
(Taiwan Traditional to Simplified with Simplified Phrase
不僅繁轉簡,用語也變了)
推薦hahow線上學習python: https://igrape.net/30afN

![Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子?](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2024/02/20240208093926_0.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子?")



 ; qn(‘w:tbl’) ; qn(‘w:sectPr’)")
![Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/04/20260430085117_0_0beced.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]")
 vs iterrows() ; for row in df.itertuples ( index=False, name=None)")


近期留言