import numpy as np
ads = [
[“TV”, 200],
[“BroadCast”, 100],
[“Paper”, 50],
[“NetWork”, 300]
]
adsAry = np.array(ads)
print(“Array切片:”,adsAry[2: , 0])
print(“list切片:”,ads[2:][0])
#list中還有list,其實仍是1D,非2D,
#所以沒辦法像array一樣縱向切片
ads_dict = dict(ads)
print(ads_dict)
dic = dict(ads)
set1 = set(dic)
print(set1)
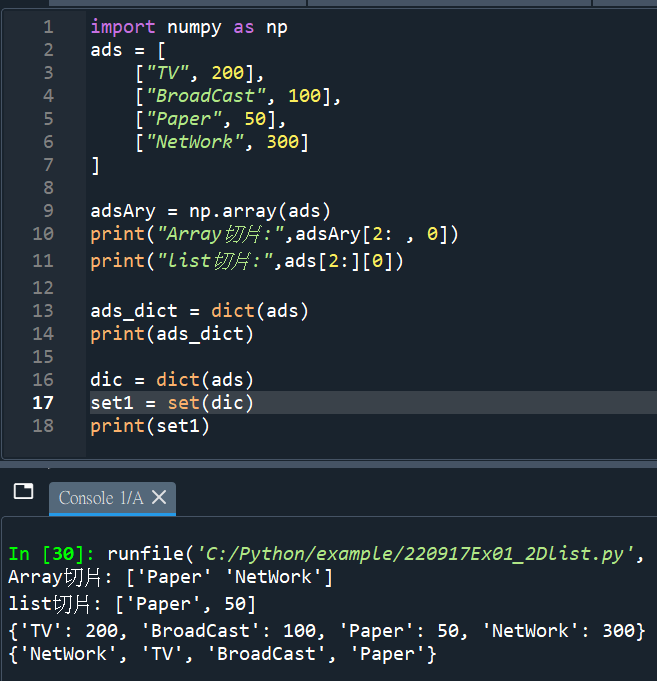
含或不含最後一列:
import numpy as np
lst2D = [
[1,2,3],
[4,5,6],
[7,8,9],
[9,8,7]
]
ary2D = np.array(lst2D)
print(“切片不含最後一列:\n”,ary2D[2:-1,:])
#-1是指最後一個元素(不含)
print(“切片含最後一列:\n”,ary2D[2:,:])
#省略第二個參數,表示(含)最後一個元素
print(“切片含最後一列:\n”,ary2D[2:4,:])
#row index只有0 1 2 3 , 4=len(ary2D)
#已經超過3,含最後一個元素
#list也可用一樣的方法
建立dict的兩種方法:

右邊的方法,
key必須符合變數的格式
(數字或數字起頭不行)
會將變數轉為str
左邊的方法
key可以用int
但建議用str
推薦hahow線上學習python: https://igrape.net/30afN

完整教學; pip install openai-whisper ; 如何購買 OpenAI API key?如何生成字幕檔?")
 傳回沿軸最小值的index,參數不能用list,可用numpy.array(),把list轉為array")
 as file: for line in file: L.append(line.split())")
 or(|) xor(^) not ; assert 預期為真的條件式, “錯誤訊息” ; 條件式為真的話,繼續往下跑,否則AssertionError: “錯誤訊息”")

![Python:如何將folder_path & file_name合併為file_path? fpath = os.path.join (folder , fname) #不需要[ ]包覆folder,fname; fpath1 = “\\”.join( [folder , fname] ) #需要[ ] 包覆folder,fname ; 反過來講,file_path如何拆分為folder_path & file_name? os.path.dirname() ; os.path.basename() ; file_name如何拆分為主檔名與副檔名os.path.splitext() #split(分裂) ext](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/07/20230717184401_87.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python:如何將folder_path & file_name合併為file_path? fpath = os.path.join (folder , fname) #不需要[ ]包覆folder,fname; fpath1 = “\\”.join( [folder , fname] ) #需要[ ] 包覆folder,fname ; 反過來講,file_path如何拆分為folder_path & file_name? os.path.dirname() ; os.path.basename() ; file_name如何拆分為主檔名與副檔名os.path.splitext() #split(分裂) ext")
 ; extend() 的差別為何? extend()配合zip()超好用")

![Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc='upper left', bbox_to_anchor=(6/10, 3/5) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230502163945_79-520x245.png)
![Python: 如何用 pandas.DataFrame.apply 讓DataFrame增加新的一欄 ; df[“mean”] = df.apply( np.mean, axis=1) ; DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230519084320_22-520x245.png)

近期留言