apply()主要用在
Python: 如何對 pandas.DataFrame 兩欄位運算後,增加到最後一欄?
pandas官網對於apply()的說明
(點此或下圖連結官網):


DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)
主要參數是func跟axis
(若func的參數為df,通常 axis=1, 但預設值是0)
參考此篇:
Python: 如何對 pandas.DataFrame 兩欄位運算後,增加到最後一欄?
就知道為何axis=1
本篇則主要說明result_type
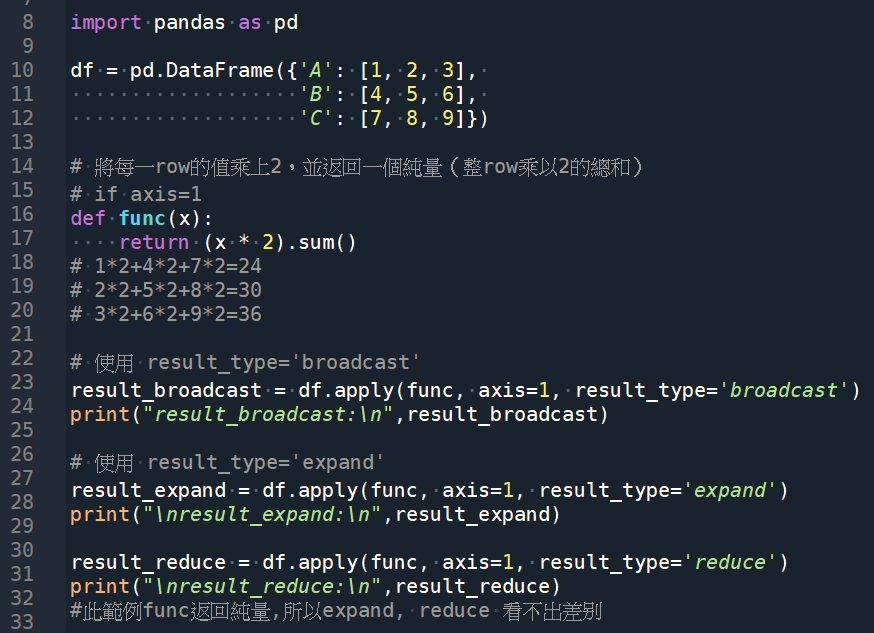
import pandas as pd
df = pd.DataFrame({‘A’: [1, 2, 3],
‘B’: [4, 5, 6],
‘C’: [7, 8, 9]})
“””df:
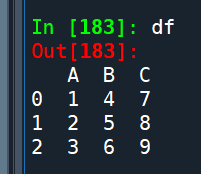 “””
“””
# 將每一row的值乘上2,並返回一個純量(整row乘以2的總和)
# if axis=1
def func(x):
return (x * 2).sum()
# 1*2+4*2+7*2=24
# 2*2+5*2+8*2=30
# 3*2+6*2+9*2=36
# 使用 result_type=’broadcast’
result_broadcast = df.apply(func, axis=1, result_type=’broadcast’)
print(“result_broadcast:\n”,result_broadcast)
# 使用 result_type=’expand’
result_expand = df.apply(func, axis=1, result_type=’expand’)
print(“\nresult_expand:\n”,result_expand)
result_reduce = df.apply(func, axis=1, result_type=’reduce’)
print(“\nresult_reduce:\n”,result_reduce)
#此範例func返回純量,所以expand, reduce 看不出差別
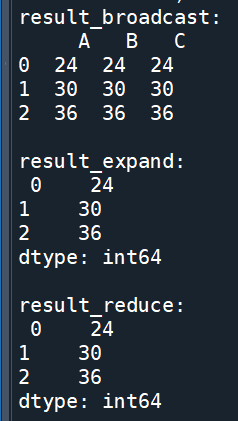
輸出結果:
推薦hahow線上學習python: https://igrape.net/30afN

")


![Excel TQC考題208: Competition,自訂格式: [<=50]0; 頁面配置>版面設定 展開>頁首/頁尾](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220411102844_81.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Excel TQC考題208: Competition,自訂格式: [<=50]0; 頁面配置>版面設定 展開>頁首/頁尾")
")
![為什麼 Python 要用 `max` 配合 `key=lambda`?從找最長文字的 Span 談起 ; #spans:list[dict] ; max(spans, key=lambda s: len(s.get(“text”, “”)))](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/06/20260602132524_0_c45d06.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "為什麼 Python 要用 `max` 配合 `key=lambda`?從找最長文字的 Span 談起 ; #spans:list[dict] ; max(spans, key=lambda s: len(s.get(“text”, “”)))")
字串與字串的對齊{:8.2f}預設靠右, {:<8.2f}靠左,{:>8.2f}靠右,{:^8.2f}置中,{:=^10s}”.format(“傳說中的分隔線”) ; print(f”{s:=<10}\") ; \"傳說中的分隔符號\".center(40, \"=\")")



近期留言