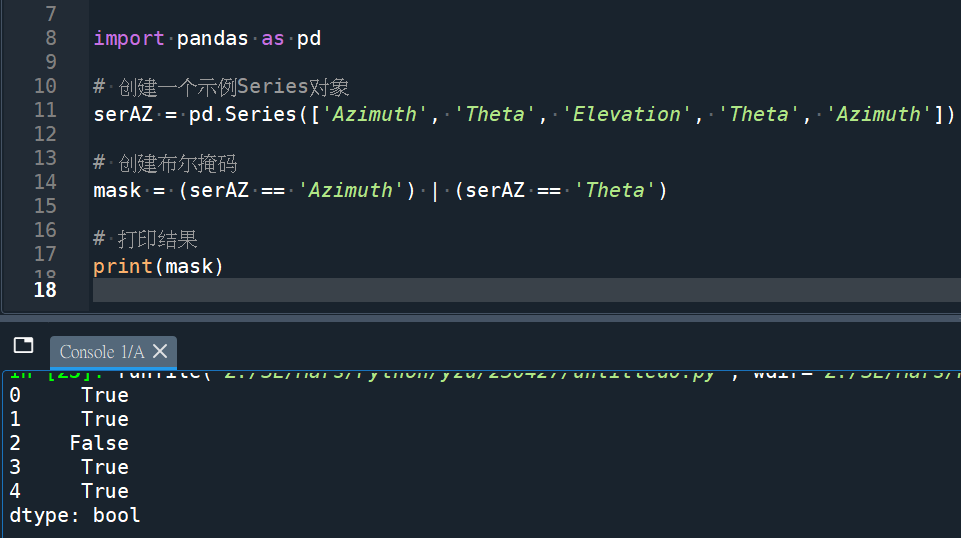
code:
import pandas as pd
# 创建一个示例Series对象
serAZ = pd.Series(['Azimuth', 'Theta', 'Elevation', 'Theta', 'Azimuth'])
# 创建布尔掩码
mask = (serAZ == 'Azimuth') | (serAZ == 'Theta')
# 打印结果
print(mask)輸出結果:
將|改為or,將觸發ValueError:
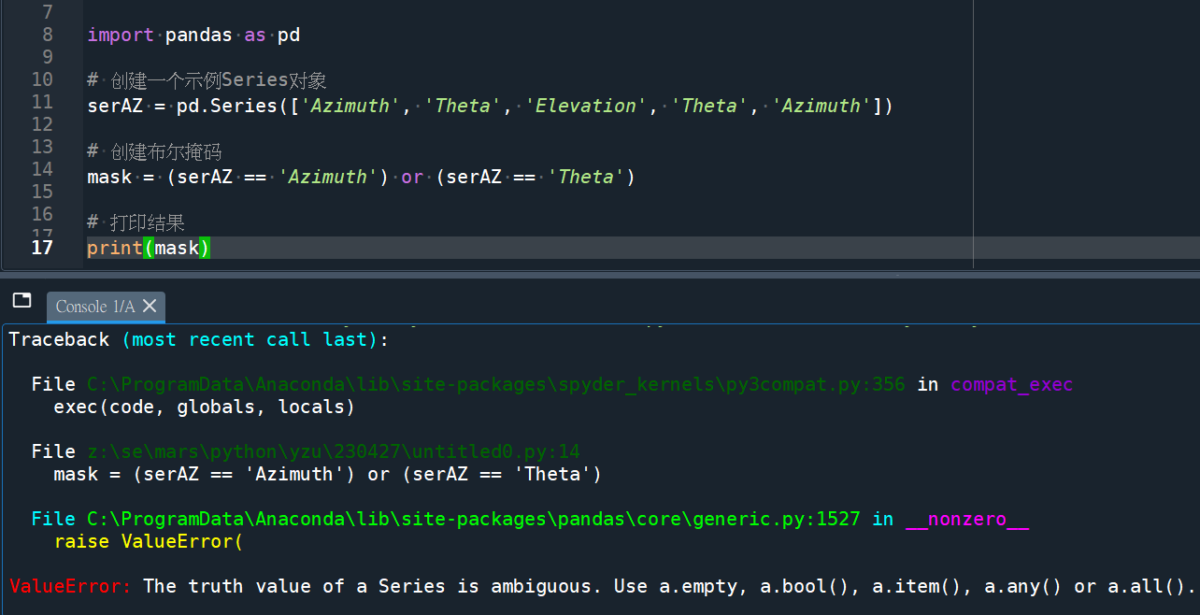
在 Python 中,用 or 時會先判斷左邊的表達式,
如果其為真則不會判斷右邊的表達式,
而直接返回左邊的結果。
而當左邊的表達式為 Pandas 的 Series 時,
該結果是一個包含多個布爾值的 Series。
這時就會引發 ValueError:
The truth value of a Series is ambiguous(模糊的) 的錯誤,
因為 Pandas 無法確定這個
包含多個布爾值的 Series 到底應該返回什麼值。
相反的,| 運算符會針對每個元素進行比較,
(類比 逐位元運算)
然後將結果組合成一個新的布爾值 Series。
因此,當您在 Pandas 中使用邏輯運算符時,
應該使用 | 而不是 or,
並使用括號將比較表達式括起來以避免優先級問題。
推薦hahow線上學習python: https://igrape.net/30afN
 ; pix = page .get_pixmap( matrix=mat )")
, f.write(datanew)")

 駝峰切詞與特例保護教學; (?i: … ):不分大小寫的非捕獲群組")
")


 ; json.dumps() 差異為何?")
![Python TQC 510 費氏數列,list[], f.append(n3)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220522152013_66.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC 510 費氏數列,list[], f.append(n3)")

近期留言