在Pandas中,有几种方法可以进行数据透视操作。下面是其中几种常用的方法:
pivot_table()方法:这是 Pandas 中的一个内置函数,可以根据指定的行和列索引对数据进行聚合和透视。它的语法如下:
import pandas as pd
# 创建数据框
df = pd.DataFrame({
'Category': ['A', 'B', 'A', 'B'],
'Value': [10, 20, 30, 40],
'Year': [2019, 2019, 2020, 2020]
})
# 使用 pivot_table 进行透视
pivot_df = df.pivot_table(index='Category',
columns='Year', values='Value', aggfunc='sum')
print(pivot_df)輸出結果:
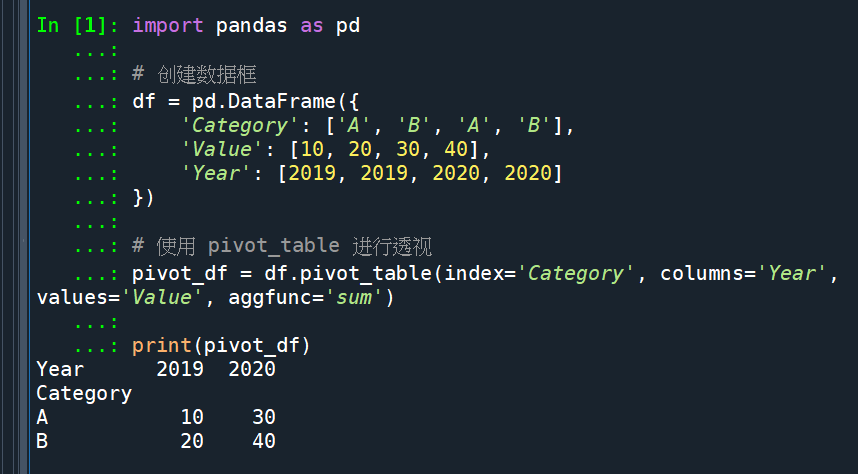
groupby() 方法:这是另一种常用的分组和聚合数据的方法。你可以使用 groupby() 方法对数据进行分组,然后使用聚合函数(例如 sum()、mean() 等)计算每个组的统计量。示例如下:
import pandas as pd
# 创建数据框
df = pd.DataFrame({
'Category': ['A', 'B', 'A', 'B'],
'Value': [10, 20, 30, 40],
'Year': [2019, 2019, 2020, 2020]
})
# 使用 groupby 进行分组和聚合
grouped_df = df.groupby(['Category', 'Year'])['Value'].sum().unstack()
print(grouped_df)
輸出結果:
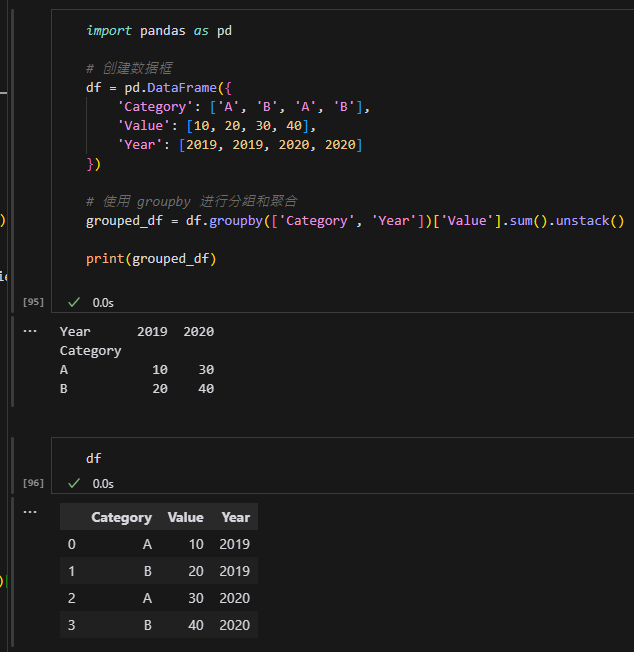
將 df.groupby([‘Category’, ‘Year’]) 物件具像化:
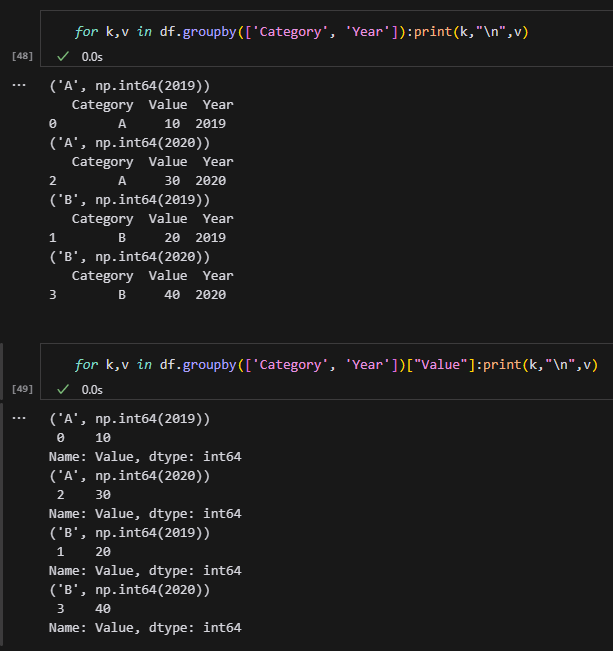
for k, v in df.groupby(['Category', 'Year']):
print(k); print(v); print(type(v)); print("\n")
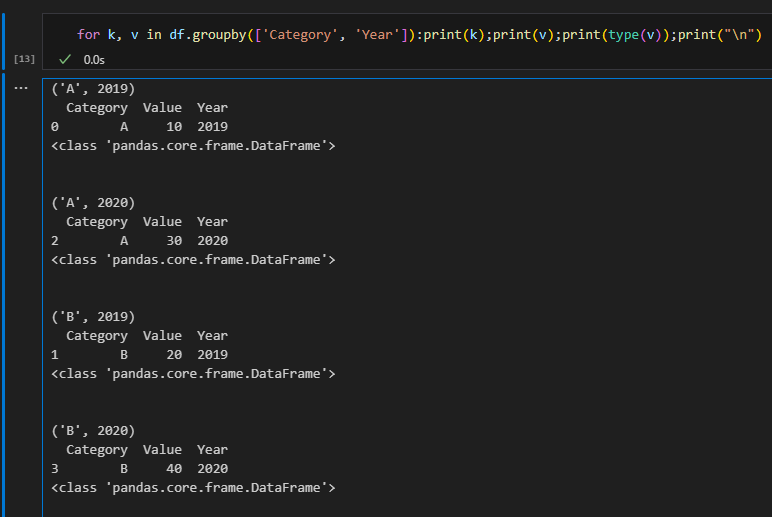
- 當使用
['Value']時,groupby只操作Value列,分組後的數據是 Series 而非 DataFrame。
© 內部實現
Pandas 的 groupby 支援類似字典的行為,但也結合了 DataFrame 的結構特性。
- 當你使用
['Value']時,groupby並不是直接像字典那樣檢索,而是將數據的範圍限制在指定的column內。 - 這背後的實現基於 Pandas 的索引機制,並非普通的鍵值對查詢。
(d) 與字典的不同
- 在字典中,鍵和值是靜態的,而在
groupby中,數據是動態計算的,且可以根據列的選擇改變結果的結構。 - 例如,
grouped是一個延遲計算的物件,只有在執行具體操作(如sum或mean)時才會生成具體的結果
unstack()
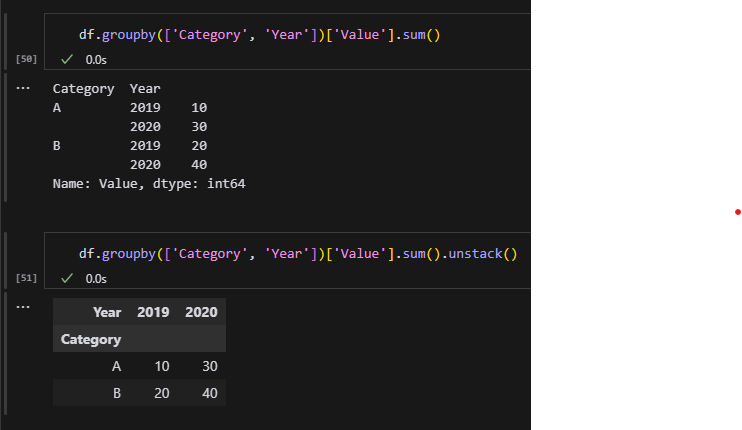
unstack():- 將多層索引(MultiIndex)中的一層(默認為內層,即
Year)轉換為列(columns)。 - 將數據從長格式(long format)轉換為寬格式(wide format)。
- 將多層索引(MultiIndex)中的一層(默認為內層,即
- 結果分析:
- 列標籤(columns):來自於
Year(即2019和2020)。 - 行標籤(index):來自於
Category(即A和B)。 - 值:分組後的總和。
- 列標籤(columns):來自於
這樣的表格形式更直觀,便於數據的比較和分析。
3. groupby 和 unstack 的結合應用
從你的程式中可以總結出一個常見的數據分析模式:
步驟:
- 分組操作 (
groupby):- 根據一個或多個鍵對數據進行分組,生成
GroupBy物件。
- 根據一個或多個鍵對數據進行分組,生成
- 聚合操作 (
sum(),mean(), 等):- 對分組後的數據執行聚合操作,生成帶有多層索引的結果。
- 結構轉換 (
unstack()):- 將多層索引的數據轉換為寬表格格式,便於進一步分析。
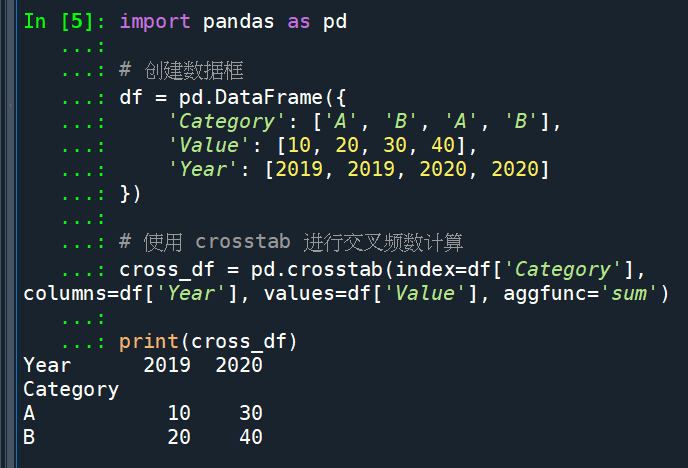
crosstab() 方法:这个方法可以用于计算两个或多个变量之间的交叉频数。它的语法如下:
import pandas as pd
# 创建数据框
df = pd.DataFrame({
'Category': ['A', 'B', 'A', 'B'],
'Value': [10, 20, 30, 40],
'Year': [2019, 2019, 2020, 2020]
})
# 使用 crosstab 进行交叉频数计算
cross_df = pd.crosstab(index=df['Category'],
columns=df['Year'], values=df['Value'],
aggfunc='sum')
print(cross_df)輸出結果:
pivot:
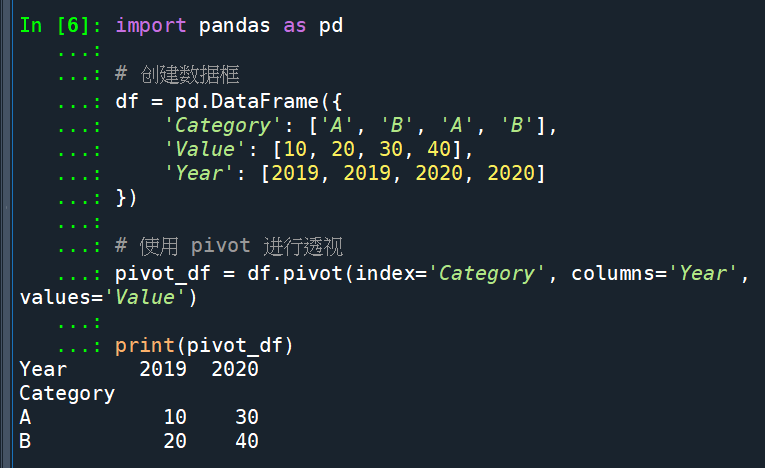
在这个代码段中,数据没有重复的索引组合,因为每个 Category 和 Year 组合只出现一次。因此,pivot() 方法能够正常执行,将唯一的组合创建为透视表。
使用pivot較為受限
1. 沒有aggfunc參數,也因此會發生狀況2
2. 数据不能有重复的索引组合,不然會觸發
ValueError: Index contains duplicate entries, cannot reshape
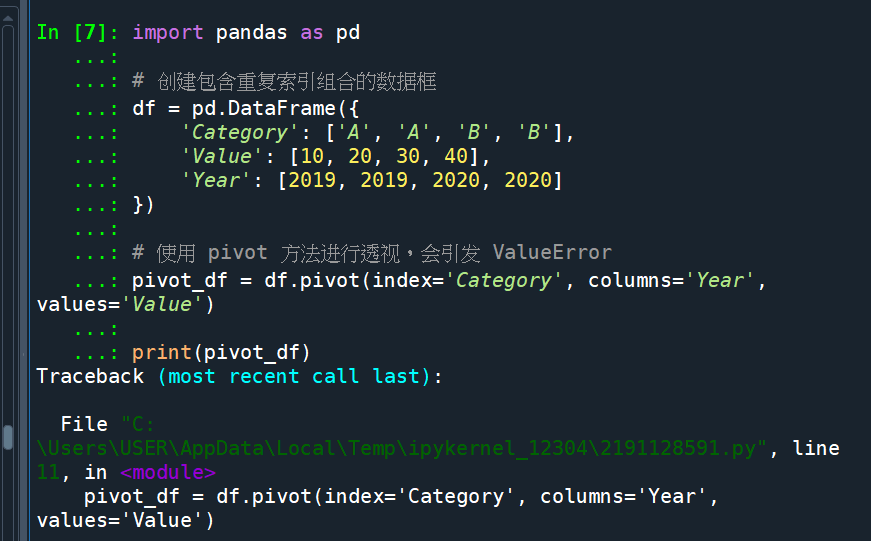
pivot() 沒有aggfunc這個參數
df.pivot?
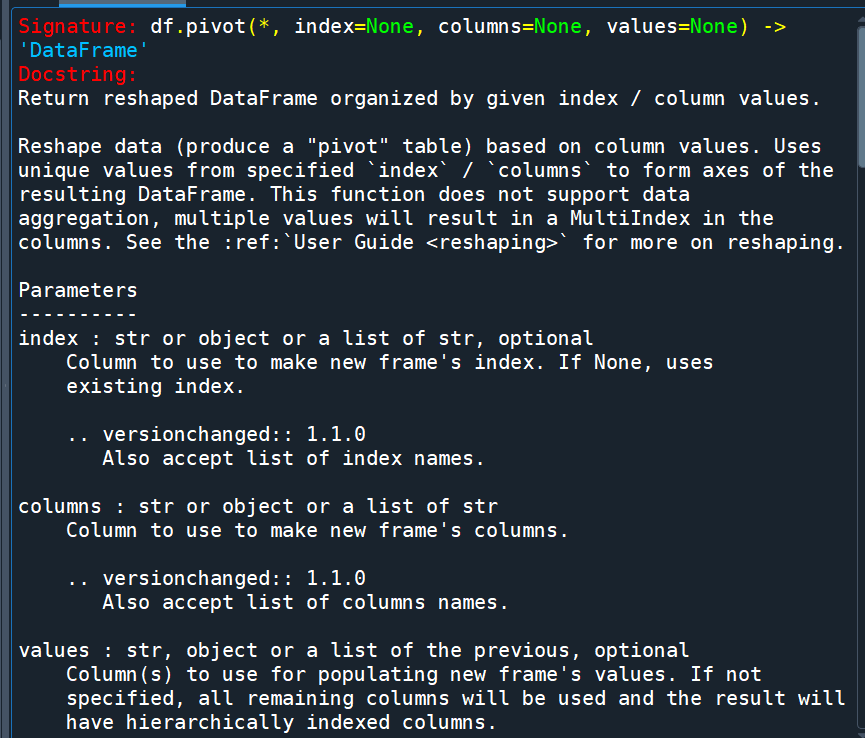
可以将 pivot_table() 看作是 groupby() 和 pivot() 的结合。
groupby() 方法用于按照指定的列对数据进行分组,然后可以使用聚合函数对每个组进行聚合操作。而 pivot() 方法用于将数据进行重塑,将指定的行和列转换为新的形式。
pivot_table() 方法结合了这两个过程,它首先对数据进行分组(类似于 groupby()),然后根据分组后的结果进行重塑(类似于 pivot()),最后可以使用聚合函数对每个组进行聚合操作。
因此,可以将 pivot_table() 看作是将 groupby() 和 pivot() 结合在一起的便捷方法,它可以在一步中完成数据的分组、重塑和聚合操作。
简单来说,pivot_table() 提供了更便捷的方式来进行数据透视和聚合操作,相比于手动使用 groupby() 和 pivot() 分别进行处理,使用 pivot_table() 可以更简洁、高效地实现相同的功能。
推薦hahow線上學習python: https://igrape.net/30afN
為什麼在使用 pivot() 時,當某一列(例如 Col3,Value)有重複值時,可能會報錯,以及為什麼需要用 pivot_table() 來處理這種情況。
1. 什麼是 pivot()?
pivot() 是 pandas 中用來將資料從「長格式」轉換成「寬格式」的方法。它的功能是將某一列的值變成新的欄位名稱,並根據其他列來重新組織資料。
例子:
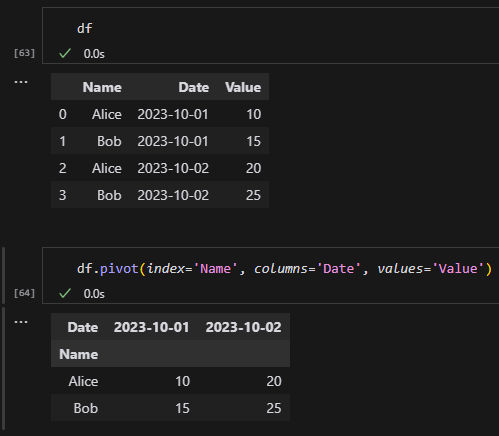
假設我們有以下資料:
| Name | Date | Value |
|---|---|---|
| Alice | 2023-10-01 | 10 |
| Bob | 2023-10-01 | 15 |
| Alice | 2023-10-02 | 20 |
| Bob | 2023-10-02 | 25 |
如果我們想用 pivot(),將 Date 作為欄位名稱,Name 作為索引,Value 作為值,可以這樣做:
df.pivot(index='Name', columns='Date', values='Value')結果會是:
2. 為什麼 pivot() 不能處理重複值?
pivot() 假設每個 (index, columns) 的組合應該對應到唯一的一個值。如果資料中有重複值,pandas 不知道該選哪一個值,因此會報錯。
例子:
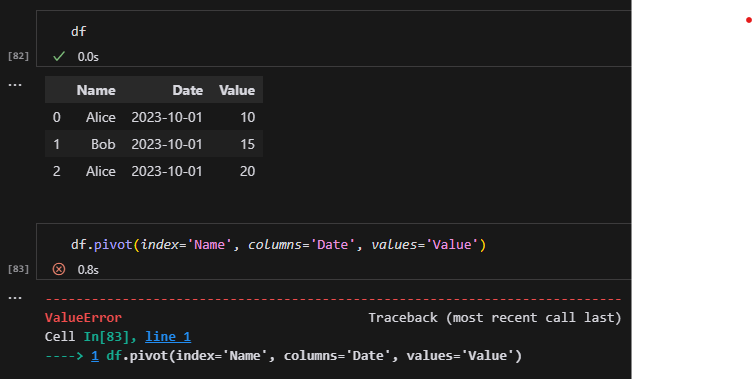
假設我們的資料變成這樣:
| Name | Date | Value |
|---|---|---|
| Alice | 2023-10-01 | 10 |
| Alice | 2023-10-01 | 15 |
| Bob | 2023-10-02 | 25 |
如果我們再次用 pivot():
df.pivot(index='Name', columns='Date', values='Value')這時候,Alice 在 2023-10-01 有兩個值(10 和 15),
pandas 不知道該填哪一個,
所以會觸發ValueError,類似這樣的訊息
ValueError: Index contains duplicate entries, cannot reshape
3. Col3 是數值還是其他類型?
Col3 不一定是數值類型。它可以是文字、日期,甚至其他類型的資料。
關鍵不在於它是不是數值,
而在於它的值是否在 (index, columns) 的組合中出現了重複。
4. 如何處理重複值?用 pivot_table()!
當資料中有重複值時,我們可以使用 pivot_table(),因為它允許我們指定聚合函數(aggfunc),來告訴 pandas 如何處理重複值。
例子:
對於以下資料:
| Name | Date | Value |
|---|---|---|
| Alice | 2023-10-01 | 10 |
| Alice | 2023-10-01 | 15 |
| Bob | 2023-10-02 | 25 |
我們可以使用 pivot_table() 並指定聚合函數,例如取平均值:
df.pivot_table(index='Name', columns='Date', values='Value', aggfunc='mean')結果會是:
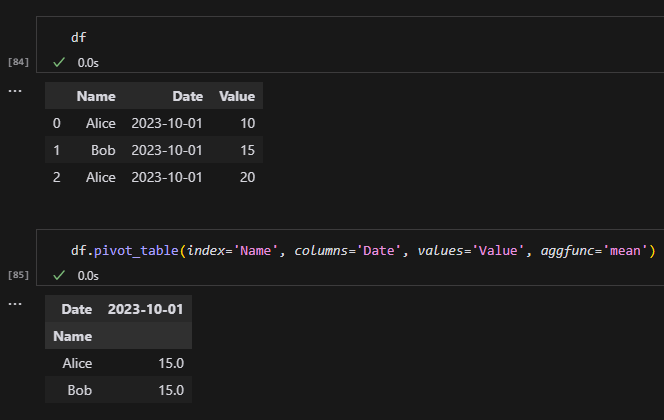
這裡,Alice 在 2023-10-01 的兩個值(10 和 15)被取了平均值((10 + 15) / 2 = 12.5)。
其他聚合函數:
sum:將重複值相加。max:取重複值的最大值。min:取重複值的最小值。list:將重複值放進一個列表中。
5. 延伸知識:什麼時候用 pivot(),什麼時候用 pivot_table()?
- 用
pivot(): 當你確定資料中每個(index, columns)的組合都只有一個值時。 - 用
pivot_table(): 當資料中可能有重複值,或者你需要對值進行聚合時。
推薦hahow線上學習python: https://igrape.net/30afN
原始資料如下:
| Col1 | Col2 | Col3 |
|---|---|---|
| A | Top | v1 |
| A | L1 | v2 |
| A | L3 | v3 |
| A | L7 | v4 |
希望轉換成這樣的格式:
| Index | Width 1 | Width 2 | Width 3 | Width 4 | Width 5 | Width 6 | Width 7 | Width 8 |
|---|---|---|---|---|---|---|---|---|
| A | v1 | v2 | v3 | v4 | NA | NA | NA | NA |
解決方法
這是一個 列轉欄 的問題,我們可以用 pandas 的 pivot 方法來完成,再手動處理欄位名稱,並補齊不足的欄位。
以下是完整的程式碼:
import pandas as pd
# 1. 建立原始資料
data = {
"Col1": ["A", "A", "A", "A"],
"Col2": ["Top", "L1", "L3", "L7"],
"Col3": ["v1", "v2", "v3", "v4"]
}
df = pd.DataFrame(data)
# 2. 新增一個序列欄位,用於排列資料
df["Col2_index"] = df.groupby("Col1").cumcount() + 1
# 3. 將資料轉換為寬表格式
pivot_df = df.pivot(index="Col1", columns="Col2_index", values="Col3")
# 4. 重命名欄位名稱為 Width 1 ~ Width 8
pivot_df.columns = [f"Width {i}" for i in pivot_df.columns]
# 5. 如果欄位數不足 8,補齊缺失欄位
for i in range(1, 9):
if f"Width {i}" not in pivot_df.columns:
pivot_df[f"Width {i}"] = pd.NA
# 6. 按照 Width 1 ~ Width 8 的順序排序欄位
pivot_df = pivot_df[[f"Width {i}" for i in range(1, 9)]]
# 7. 查看結果
print(pivot_df)輸出結果:
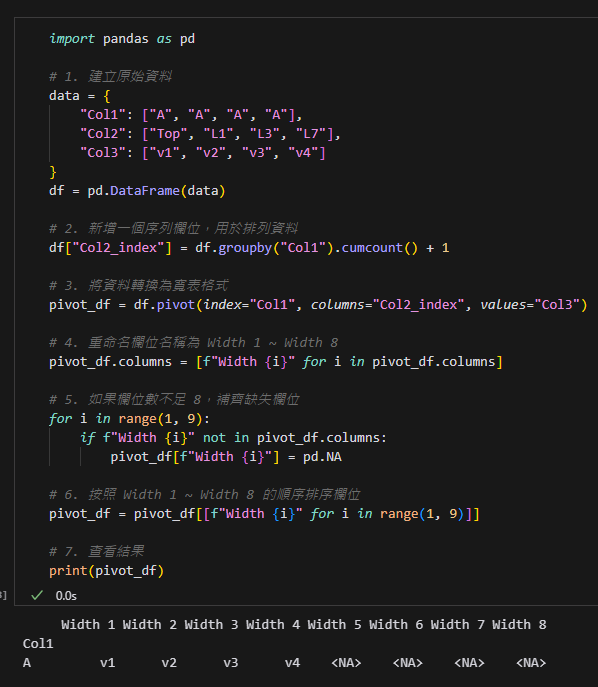
程式碼解釋
步驟 1:建立原始資料
我們用一個字典模擬你的原始資料,然後用 pd.DataFrame 轉換成 DataFrame。
步驟 2:新增序列欄位
df.groupby("Col1").cumcount() + 1:為每個Col1的組別新增一個序列編號,從 1 開始。- 這樣可以確保每個值在轉換時有唯一的編號,方便後續的欄位排列。
結果會是:
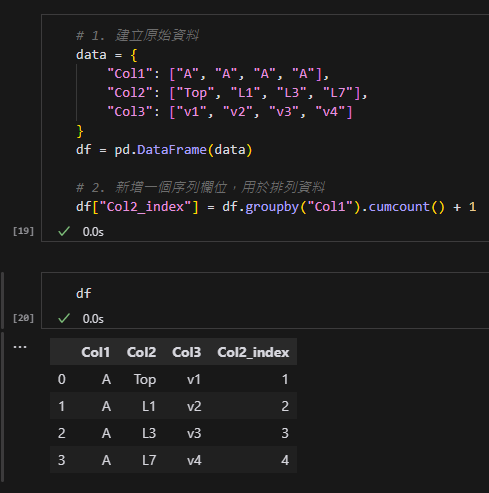
步驟 3:轉換為寬表格式
- 使用
pivot方法:index="Col1":將Col1作為索引。columns="Col2_index":將Col2_index的值變成欄位名稱。values="Col3":填入對應的Col3值。
結果會是:
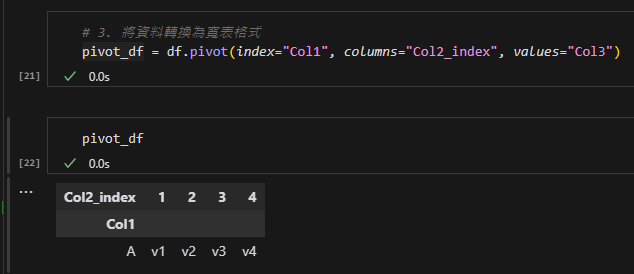
步驟 4:重命名欄位名稱
- 使用列表生成式將欄位名稱改為
Width 1到Width 8。
步驟 5:補齊缺失欄位
- 如果欄位數不足 8,手動補齊缺失的欄位,並填入
NA。
步驟 6:排序欄位
- 確保欄位按照
Width 1到Width 8的順序排列。
結果輸出
執行上述程式碼後,結果如下:
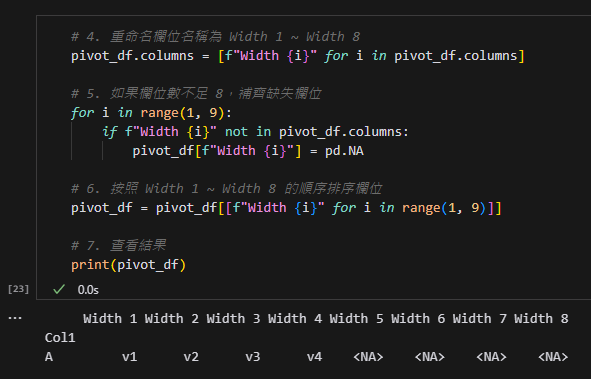
df.groupby("Col1").cumcount() + 1 的作用,並用生活化的例子幫助你理解。
1. 它是什麼?
df.groupby("Col1").cumcount() 是 pandas 中的一個方法,用來計算每個分組內的行數(從 0 開始計算)。加上 + 1,是為了讓計數從 1 開始,而不是從 0 開始。
2. 為什麼要用它?
在我們的問題中,我們需要為每個 Col1 的分組,給每一行的 Col2 值分配一個序號,這樣才能在後續的寬表轉換中,正確地將資料對應到 Width 1 ~ Width 8 的欄位。
3. 舉個例子
假設我們有一個資料表如下:
| Col1 | Col2 | Col3 |
|---|---|---|
| A | Top | v1 |
| A | L1 | v2 |
| A | L3 | v3 |
| B | L7 | v4 |
| B | L8 | v5 |
我們希望給每個 Col1 的分組,依序編號。這時候可以使用 df.groupby("Col1").cumcount()。
4. 運作過程
Step 1: 分組
將資料按照 Col1 分成兩組:
- 組 A:Col1Col2Col3ATopv1AL1v2AL3v3
- 組 B:Col1Col2Col3BL7v4BL8v5
Step 2: 計算每組內的行數
cumcount() 會為每個分組內的行數進行計算,從 0 開始編號:
- 組 A:Col1Col2Col3cumcount()ATopv10AL1v21AL3v32
- 組 B:Col1Col2Col3cumcount()BL7v40BL8v51
Step 3: 加 1
為了讓編號從 1 開始,而不是從 0 開始,我們在 cumcount() 的結果上加 1:
- 組 A:Col1Col2Col3cumcount() + 1ATopv11AL1v22AL3v33
- 組 B:Col1Col2Col3cumcount() + 1BL7v41BL8v52
結果
最後,我們會得到一個新的欄位,記錄每個分組內的行數(從 1 開始):
| Col1 | Col2 | Col3 | Col2_index |
|---|---|---|---|
| A | Top | v1 | 1 |
| A | L1 | v2 | 2 |
| A | L3 | v3 | 3 |
| B | L7 | v4 | 1 |
| B | L8 | v5 | 2 |
5. 生活化舉例
假設你是班級老師,班上有兩個班級:A 班和 B 班。每個班級的學生名單如下:
- A 班:小明、小華、小美
- B 班:小強、小芳
現在你想給每個班級的學生編號,讓他們的學號從 1 開始。你可以這樣做:
- 先按照班級分組(A 班、B 班)。
- 然後從 1 開始,依序給每個學生編號。
結果會是:
- A 班:
- 小明:1
- 小華:2
- 小美:3
- B 班:
- 小強:1
- 小芳:2
這就像我們用 groupby("Col1").cumcount() + 1 為每個分組內的資料編號一樣。
1. cum 是什麼意思?
在程式設計中,cum 是 cumulative 的縮寫,意思是「累積的」。這個詞在數學和資料處理中很常見,通常用來表示某些東西是隨著時間或順序逐步累加或計算的。
2. 在 cumcount() 中,cum 的意思
在 cumcount() 中,cum 表示「累積計數」。也就是說,它會隨著每一行的出現,逐步累積計算每個分組內的行數。
count:表示計數。cum:表示這個計數是累積進行的。
所以,cumcount() 的意思就是「在每個分組內,逐行累積計算行數」。
3. 生活化舉例
假設你在玩一個遊戲,規則是每次你完成一個任務,就會得到 1 分。這時候,你的分數是「累積的」,因為每次完成任務後,你的分數會在前一次的基礎上累加。
例如:
- 第一次完成任務:分數是 1。
- 第二次完成任務:分數是 2(1 + 1)。
- 第三次完成任務:分數是 3(2 + 1)。
這就是「累積」的概念。
4. cum 在其他方法中的應用
除了 cumcount(),pandas 還有很多其他帶有 cum 的方法,這些方法都和「累積」有關。例如:
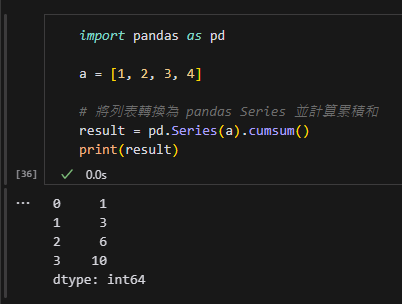
(1) cumsum()
- 功能:計算累積總和。
- 例子:假設你有一列數字
[1, 2, 3, 4],cumsum()的結果是[1, 3, 6, 10],因為每個數字都會累加到前面的總和中。
(2) cumprod()
- 功能:計算累積乘積。
- 例子:假設你有一列數字
[1, 2, 3, 4],cumprod()的結果是[1, 2, 6, 24],因為每個數字都會乘以前面的乘積。
(3) cummax()
- 功能:計算累積最大值。
- 例子:假設你有一列數字
[1, 3, 2, 5],cummax()的結果是[1, 3, 3, 5],因為每一步都會記錄到目前為止的最大值。
(4) cummin()
- 功能:計算累積最小值。
- 例子:假設你有一列數字
[4, 2, 3, 1],cummin()的結果是[4, 2, 2, 1],因為每一步都會記錄到目前為止的最小值。
推薦hahow線上學習python: https://igrape.net/30afN

 #全數字?、isalpha() #全字母?、isalnum() #全字母或數字?、islower() #全小寫? 和 isupper() #全大寫?")
與.cget()的差別為何? #configuration ; entry_widget.get() ; label_widget.cget(“text”) ; label_widget = tk.Label( window, text = “Hello, World!”)")

 ) ; for idx, sea in enumerate (seasons, start=1): print(idx,sea)")
")



![Python: 如何求整個 pandas.DataFrame 中的最大值? pandas.DataFrame .max().max() ; 如何求最大值的index, columns? numpy.where(condition, [x, y, ]/) ; condition為一 bool_mask - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/04/20230418154049_50-520x245.png)

近期留言