參考前篇: 如何串接Meta API ?
list 要從生成的json與jieba斷詞套件取得
以及: 全文件詞頻(term frequency,簡稱TF)計算
code:
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 15 06:30:23 2024
@author: SavingKing
"""
import os
import json
import jieba
folder = r"D:\Python code\240107_爬蟲"
fname = "my_lis_msg_backup.json"
fpath = os.path.join(folder,fname)
#'D:\\Python code\\240107_爬蟲\\my_lis_msg.json'
with open(fpath,"r",encoding="UTF-8") as f:
dic = json.load(f)
k0 = list(dic.keys())[0]
lis = dic[k0]
strr = "\n".join(lis)
lis_jieba = jieba.lcut(strr)
leng = len( lis_jieba )
dic_term_freq = {}
for term in lis_jieba:
if term in dic_term_freq:
dic_term_freq[term] += 1/leng
else:
dic_term_freq[term] = 1/leng
print(dic_term_freq)輸出結果:
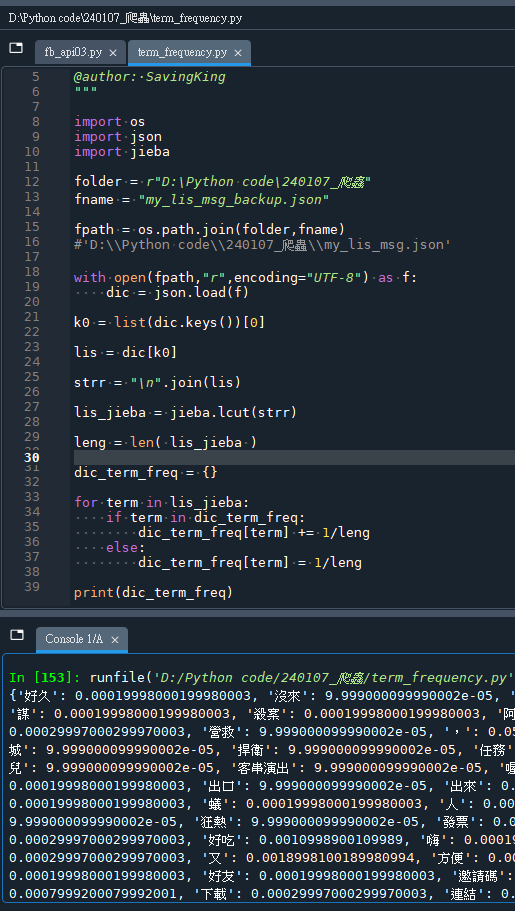
推薦hahow線上學習python: https://igrape.net/30afN
出現最多的是那些詞?
詞頻多少?
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 15 06:30:23 2024
@author: SavingKing
"""
import os
import json
import jieba
folder = r"D:\Python code\240107_爬蟲"
fname = "my_lis_msg_backup.json"
fpath = os.path.join(folder,fname)
#'D:\\Python code\\240107_爬蟲\\my_lis_msg.json'
with open(fpath,"r",encoding="UTF-8") as f:
dic = json.load(f)
k0 = list(dic.keys())[0]
lis = dic[k0]
strr = "\n".join(lis)
lis_jieba = jieba.lcut(strr)
while "\n" in lis_jieba:
lis_jieba.remove("\n")
while ',' in lis_jieba:
lis_jieba.remove(',')
while '。' in lis_jieba:
lis_jieba.remove('。')
leng = len( lis_jieba )
dic_term_freq = {}
for term in lis_jieba:
if term in dic_term_freq:
dic_term_freq[term] += 1/leng
else:
dic_term_freq[term] = 1/leng
print(dic_term_freq)
#出現最多的是那些詞? 詞頻多少?
max_count = max(dic_term_freq.values())
lis_max_count=[]
for k in dic_term_freq:
if dic_term_freq[k] == max_count:
lis_max_count.append(k)
print("max_count:",max_count)
print("lis_max_count:",lis_max_count)輸出結果:
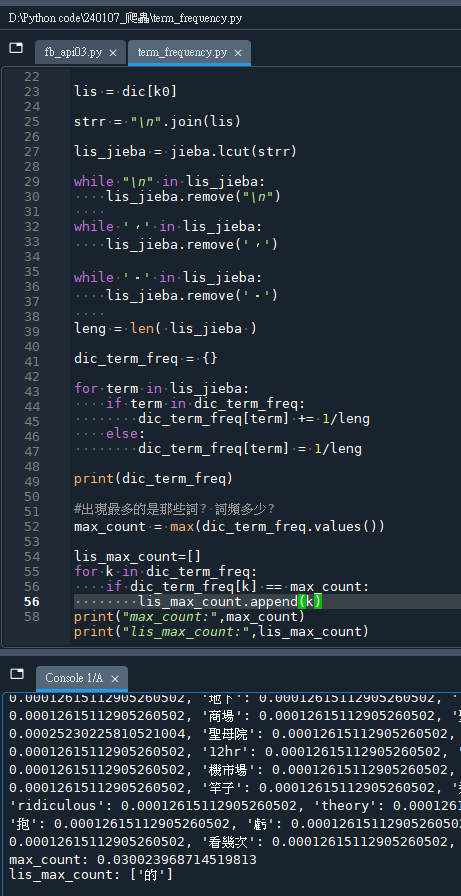
詞頻最高的是”\n”
去掉”\n”後
變成逗點
去掉逗點後
變成句點
需要使用IDF(Inverse Document Frequency)
濾掉詞頻高
但是卻不重要的詞
簡單點的話,
則可以挑選長度>=2的詞
推薦hahow線上學習python: https://igrape.net/30afN
使用list.count(str)
取代以下語法得到的dic_TF
for term in lis_jieba:
if term in dic_term_freq:
dic_term_freq[term] += 1/leng
else:
dic_term_freq[term] = 1/lenglist.count(str)
code:
# -*- coding: utf-8 -*-
"""
Created on Sun Jan 21 13:09:21 2024
@author: SavingKing
"""
import os
import json
import jieba
dirname = r"D:\Python code\240107_爬蟲"
basename= "my_lis_msg_backup.json"
json_path = os.path.join(dirname,basename)
with open(json_path,"r",encoding="UTF-8") as f:
dic = json.load(f)
lis = dic['my lis_msg']
lis2D=[]
for ele in lis:
lis2D.append(jieba.lcut(ele))
lis2D_flatten = []
for ele in lis2D:
lis2D_flatten.extend(ele)
#只要長度大於2的詞
lis2D_flatten_2 = []
for ele in lis2D_flatten:
if len(ele) >=2:
lis2D_flatten_2.append(ele)
dic_TF ={}
for word in set(lis2D_flatten_2):
tf = lis2D_flatten_2.count(word)
dic_TF.update({word:tf})
lis_sort = sorted(dic_TF.items(),
key=lambda tup:tup[1],
reverse=True )
for ele in lis_sort:
if ele[1]>7:
print(ele[0],ele[1])輸出結果
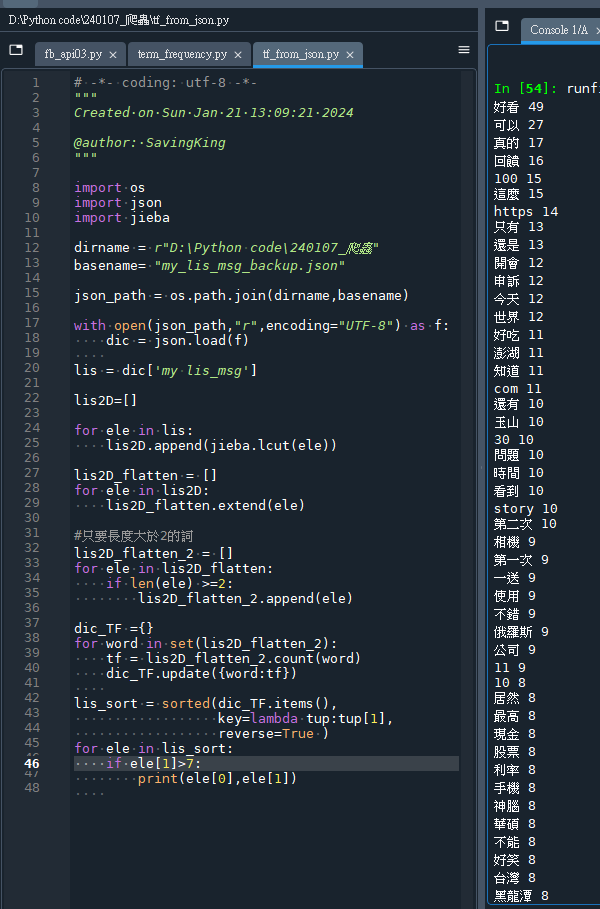
推薦hahow線上學習python: https://igrape.net/30afN
, set.add(n)")
 與 re.split() 的用法與比較")
, chr(), list(str)會把字串的每一個字母拆分進入list中,string跟list都可以使用index定位,沒有非要將string轉為list, for i in str: i 也可以依序代入str的每一個chr")
 ; X_poly = poly.fit_transform(X)")

")
 API? MIME (Multipurpose Internet Mail Extensions)")

![Python: 如何使用 os.environ[“PATH”] 設定環境變數?與 sys.path.append() 差別為何?](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2024/09/20240905135312_0_890fa1.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何使用 os.environ[“PATH”] 設定環境變數?與 sys.path.append() 差別為何?")
![Word短篇文件編輯,TQC考題110:重點摘要與評量, [(*)] 萬用字元,格式>醒目提示*2次=非醒目提示 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/03/20220322172253_75-520x245.png)

近期留言