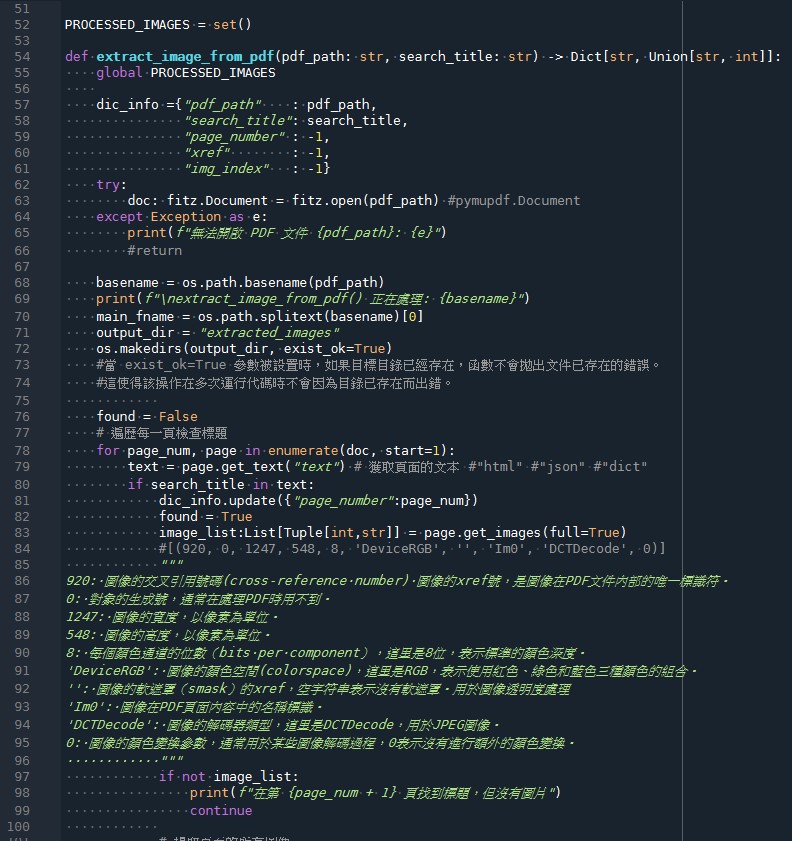
簡化code:
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 5 19:07:21 2024
@author: SavingKing
"""
import os
import glob
import fitz # PyMuPDF
dirname = r"D:\user\Python\test_plan\Schematic diagram_CAPALA\brief"
basename = "*.pdf"
path = os.path.join(dirname, basename)
pdf_paths = glob.glob(path)
search_titles = ["MOBO BLOCK DIAGRAM", "FAN BOARD BLOCK DIAGRAM"]
def extract_image_from_pdf(pdf_path, search_title):
try:
doc = fitz.open(pdf_path)
except Exception as e:
print(f"無法開啟 PDF 文件 {pdf_path}: {e}")
return
output_dir = "extracted_images"
os.makedirs(output_dir, exist_ok=True)
for page in doc:
if search_title in page.get_text("text"):
images = page.get_images(full=True)
for img in images:
xref = img[0]
img_info = doc.extract_image(xref)
#:Dict[str,bytes|str|int]
""" 使用 Python 3.10 或更新版本 ,
Union[bytes, str, int] 可寫為 bytes|str|int
base_image.keys()
Out[59]: dict_keys(['ext', 'smask', 'width', 'height', 'colorspace', 'bpc', 'xres', 'yres', 'cs-name', 'image'])
"""
image_filename = f"{output_dir}/{search_title}_{page.number + 1}_{os.path.splitext(os.path.basename(pdf_path))[0]}_{xref}.{img_info['ext']}"
with open(image_filename, "wb") as img_file:
img_file.write(img_info["image"])
print(f"已儲存圖片: {image_filename}")
doc.close()
for title in search_titles:
for path in pdf_paths:
extract_image_from_pdf(path, title)核心code:
導入必要的模組:使用 os, glob, 和 fitz(PyMuPDF)模組。 設定搜尋路徑和檔案:指定存放PDF的目錄,以及使用 glob 來尋找所有符合條件的PDF文件。 定義搜尋標題:建立一個標題列表,這些標題是我們想在PDF文件中尋找的目標。 定義函數 extract_image_from_pdf:
- 首先嘗試打開PDF文件。
- 建立圖片存放目錄。
- 遍歷每一頁,檢查是否包含指定的標題。
- 如果找到,則提取該頁的所有圖片。
- 將提取的圖片存儲到指定的路徑。
執行圖片提取:對每個PDF路徑和每個搜尋標題執行 extract_image_from_pdf 函數。
推薦hahow線上學習python: https://igrape.net/30afN
images:List[tuple] = page.get_images(full=True)
#img: Tuple[int, int, int, int, int, str, str, str, str, int]
#img: (920, 0, 1247, 548, 8, ‘DeviceRGB’, ”, ‘Im0’, ‘DCTDecode’, 0)
920: 圖像的交叉引用號碼(cross-reference number) 圖像的xref號,是圖像在PDF文件內部的唯一標識符。
0: 對象的生成號,通常在處理PDF時用不到。
1247: 圖像的寬度,以像素為單位。
548: 圖像的高度,以像素為單位。
8: 每個顏色通道的位數(bits per component),這里是8位,表示標準的顏色深度。
‘DeviceRGB’: 圖像的顏色空間(colorspace),這里是RGB,表示使用紅色、綠色和藍色三種顏色的組合。
”: 圖像的軟遮罩(smask)的xref,空字符串表示沒有軟遮罩。用於圖像透明度處理
‘Im0’: 圖像在PDF頁面內容中的名稱標識。
‘DCTDecode’: 圖像的解碼器類型,這里是DCTDecode,用於JPEG圖像。
0: 圖像的顏色變換參數,通常用於某些圖像解碼過程,0表示沒有進行額外的顏色變換。
PyMuPDF (fitz) 圖片提取詳細介紹
- 提取圖片信息
get_images(full=True) 方法用於從PDF頁面中檢索所有圖像的詳細信息。這個方法返回一個包含圖像信息的列表。每個圖像信息是一個包含多個字段的元組,主要包含以下重要字段:
xref: 圖像在PDF文件中的引用編號,這是一個唯一標識符,用於從PDF中提取具體的圖像數據。
width: 圖像的寬度(像素)。
height: 圖像的高度(像素)。
colorspace: 圖像的顏色空間。
bpc: 圖像每個顏色通道的位數。
當調用 full=True 時,get_images 返回關於圖像的更詳細信息,這對於進一步處理非常有用。
- 從PDF提取具體圖像
要從PDF中提取具體的圖像,我們使用 doc.extract_image(xref) 方法,這里的 xref 是從 get_images() 方法獲取的圖像引用編號。extract_image 方法返回一個字典,包含實際的圖像數據及其屬性,主要字段如下:
“image”: 包含圖像文件數據的字節字符串。
“ext”: 圖像的文件擴展名,如 ‘jpg’, ‘png’ 等。
“colorspace”: 圖像的顏色空間。
“smask”: 如果存在,這是圖像的透明通道。
保存圖像到文件系統
一旦我們有了圖像的字節數據和文件擴展名,我們就可以將圖像數據寫入到文件中。這可以通過簡單地打開一個文件並寫入數據來完成:
with open(image_filename, "wb") as img_file:
img_file.write(img_info["image"])這里,image_filename 是根據圖像的頁面號碼、標題、PDF文件名以及圖像的引用編號動態生成的,確保每個文件名都是唯一的,並且反映了圖像的來源和屬性。
完整的圖像提取和保存流程
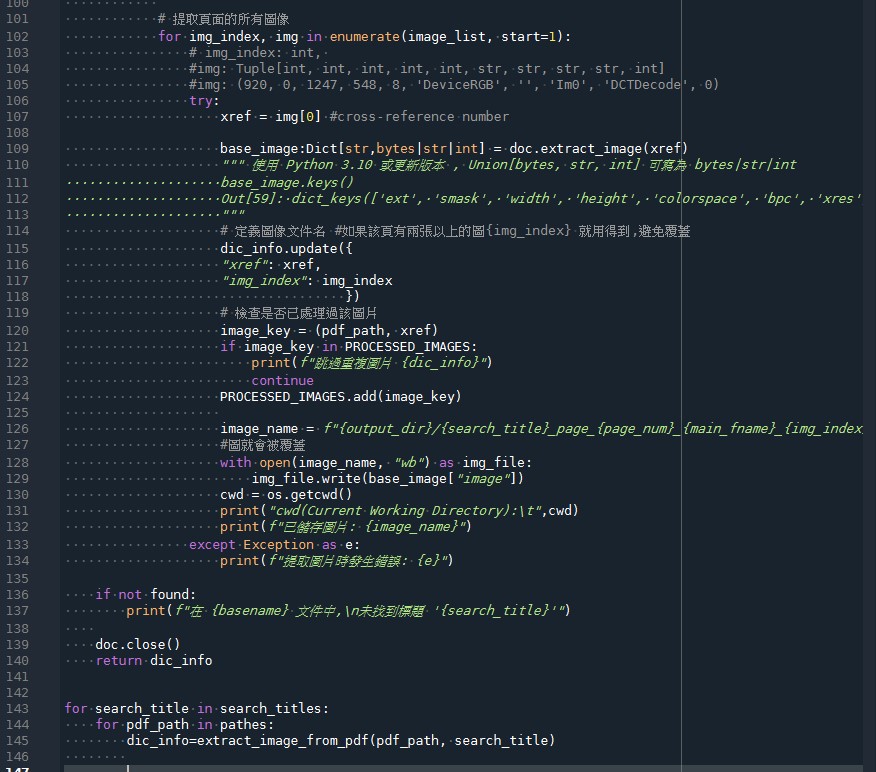
結合上述解釋,下面是一個完整的流程,展示了如何在頁面中查找圖像,提取圖像,並將其保存到文件系統中:
for page in doc:
if search_title in page.get_text("text"):
images = page.get_images(full=True)
for img in images:
xref = img[0] # 圖像的引用編號
img_info = doc.extract_image(xref) # 提取圖像信息
image_filename = f"{output_dir}/{search_title}_{page.number + 1}_{os.path.splitext(os.path.basename(pdf_path))[0]}_{xref}.{img_info['ext']}"
with open(image_filename, "wb") as img_file:
img_file.write(img_info["image"]) # 保存圖像到文件
print(f"已儲存圖片: {image_filename}")這個過程確保了從PDF中準確地提取和保存圖像,同時記錄了圖像的來源信息,使其易於追蹤和管理。
推薦hahow線上學習python: https://igrape.net/30afN

![Python: 如何將pandas.DataFrame從寬資料轉為長資料? df_melt = pd.melt(df, id_vars=[‘name’, ‘gender’], var_name=’time’, value_name=’score’) ; seaborn繪圖](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230302152215_95.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何將pandas.DataFrame從寬資料轉為長資料? df_melt = pd.melt(df, id_vars=[‘name’, ‘gender’], var_name=’time’, value_name=’score’) ; seaborn繪圖")
如何設定sep參數才能讀取分隔子同時有, ” ” (空白)的csv檔? df = pd.read_csv(‘test.txt’, sep = ‘\s*,\s*|\s+’, engine=’python’)")
 #封裝 CT_P (Complex Type Paragraph)為 Paragraph 物件")
, isdigit()")
 #Method Resolution Order")
的參數axis=0 / 1 vs index / columns ; 如何drop DataFrame的rows / columns ?")

 ; Visual Studio Code(VScode)為什麼會出現錯誤 module ‘csv’ has no attribute ‘reader’ ?")

近期留言