程式碼:
a = 1
lsta = list(a)
print(lsta,type(lsta),len(lsta))
輸出:
Traceback (most recent call last):
File “C:\Python\Radar_20221005\untitled1.py”, line 3, in <module>
lsta = list(a)
TypeError: ‘int’ object is not iterable
int無法取list()
如果取array()呢?
程式碼:
import numpy as np
a = 1
arya = np.array(a)
print(arya, type(arya), len(arya))
輸出:
Traceback (most recent call last):
File “C:\Python\Radar_20221005\untitled1.py”, line 7, in <module>
print(arya,type(arya),len(arya))
TypeError: len() of unsized object
int可以取array(),
只是長度0 (不要誤會長度1)
所以取len()時錯誤
empty list: []長度也是0
去掉len()
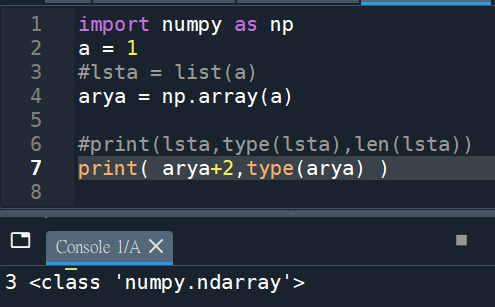
3(1+2)的左右邊沒有[ ] 包覆
type為ndarray (0-dimensional)
用法同int
numpy官網:

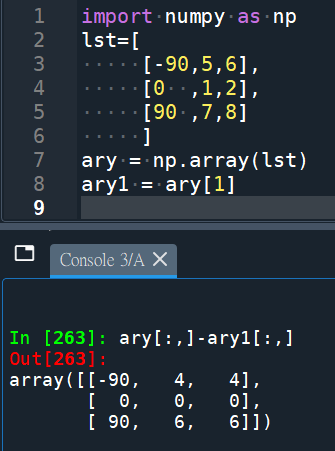
2D array的運算:
推薦hahow線上學習python: https://igrape.net/30afN


)")
,但.5GHZ的.不split()? parts = filename.rsplit(“.”, 1) ; 使用正則表示法parts = re.split(r”\.(?!\d)”, filename) ; os.path.splitext(filename)")
")

 教學; Path .read_text( encoding = “utf-8-sig”) ; `Ctrl+Shift+P` => `Preferences: Open User Settings (JSON)` => “files.encoding”: “utf8”")
![Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/04/20260430085117_0_0beced.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]")


近期留言