先看以下兩個逗點分隔檔:
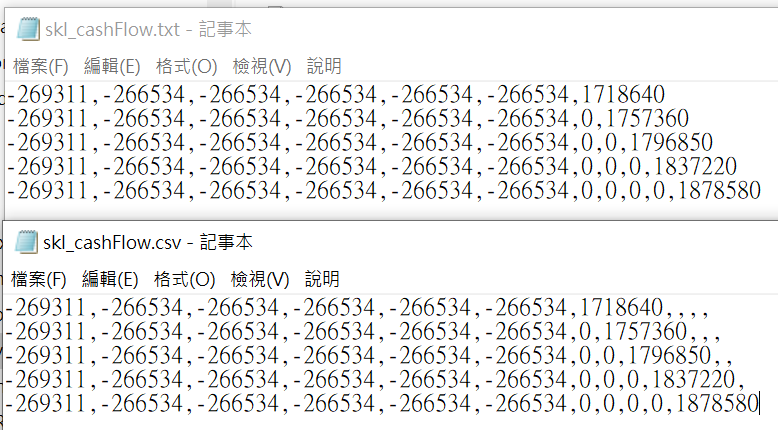
txt檔為記事本自行寫入
csv檔為Libre Office開啟後再儲存
發現csv檔(Libre)會自動補逗點跟空值
將所有列都捕到長度跟最長列一致
pandas.read_csv() vs
csv.reader()有何差別?
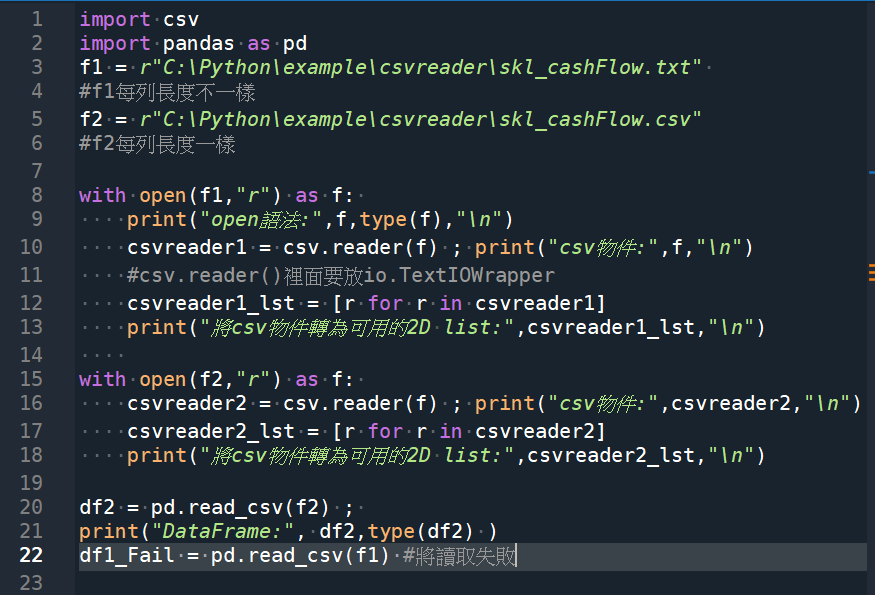
csv.reader()輸出結果:
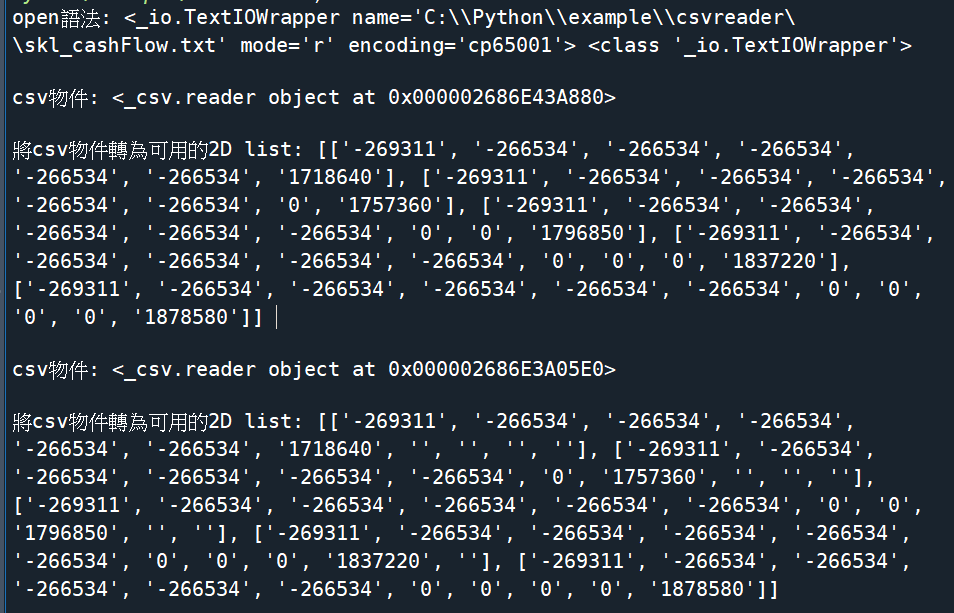
csv.reader()兩個檔案都能正常讀取
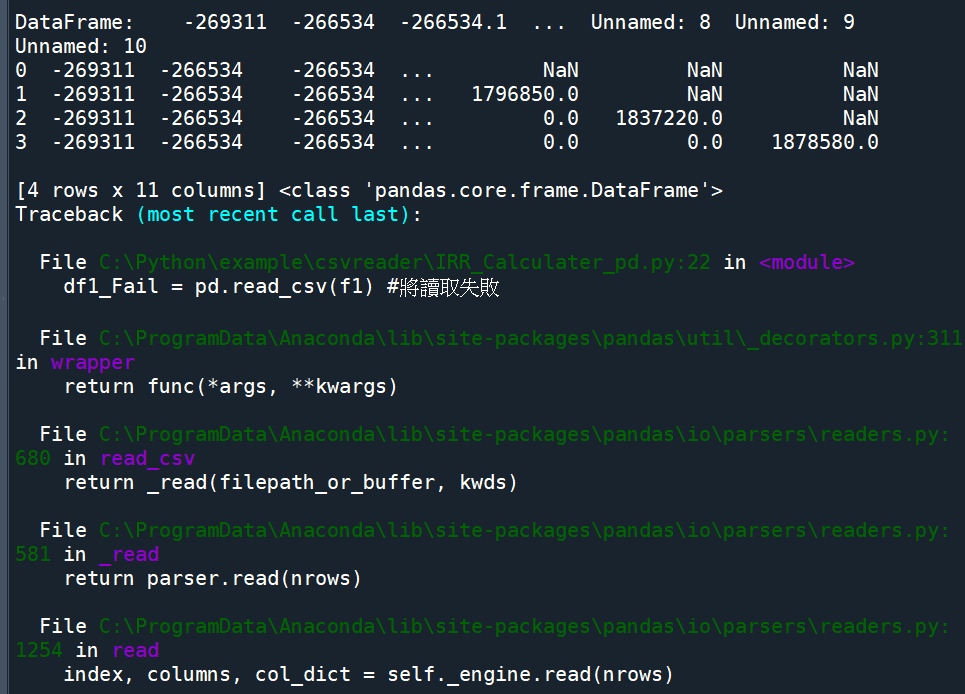
pandas.read_csv()輸出結果:
csv.reader()裡面要放io.TextIOWrapper
前面要用with open(“路徑\檔名.副檔名”, “r”) as f
產生的f即為io.TextIOWrapper
不要在csv.reader()中誤放
“路徑\檔名.副檔名”
會無法讀取檔案內容
將錯誤的csv物件轉為list時
list會如下:
[[‘C’], [‘:’], [‘\\’], [‘P’], [‘y’], [‘t’], [‘h’], [‘o’], [‘n’], [‘\\’], [‘e’], [‘x’], [‘a’], [‘m’], [‘p’], [‘l’], [‘e’], [‘\\’], [‘c’], [‘s’], [‘v’], [‘r’], [‘e’], [‘a’], [‘d’], [‘e’], [‘r’], [‘\\’], [‘s’], [‘k’], [‘l’], [‘_’], [‘c’], [‘a’], [‘s’], [‘h’], [‘F’], [‘l’], [‘o’], [‘w’], [‘.’], [‘t’], [‘x’], [‘t’]]
pandas.read_csv()
裡面放的就確實是”路徑\檔名.副檔名”
前面無需with open() as f : 的語法
無法讀取每列長度不同的逗點分隔檔
出現pandas._libs.parsers.raise_parser_error
ParserError:Error tokenizing data. C error: Expected 8 fields in line 3, saw 9
pandas以直行(欄)為單位
DataFrame又是多個Series共用相同index
造成此問題
每列代表不同年期現金流
長度不一樣實屬正常
Libre Office自動補逗點跟空值
反而會造成numpy_financial.irr()
運算錯誤
最好可以加移除空元素的語法
避免使用者誤用Libre Office
寫逗點分隔檔
您將輸入n年度末解約金?n=?
待使用者輸入下一筆資料或-9999離開
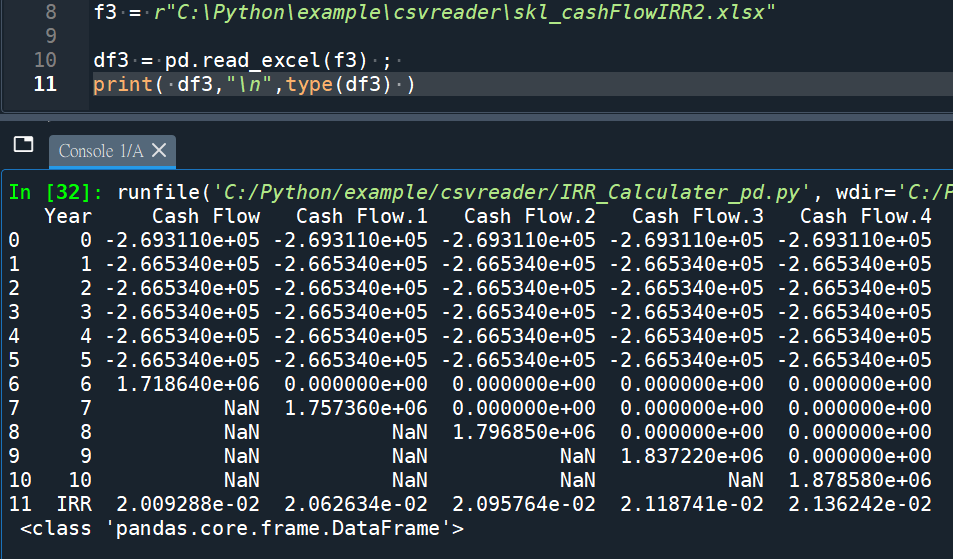
pandas讀取Excel檔(.xlsx)
import pandas as pd
f3 = r”C:\Python\example\csvreader\skl_cashFlowIRR2.xlsx”
df3 = pd.read_excel(f3) ;
print( df3,type(df3) )
#type為DataFrame
推薦hahow線上學習python: https://igrape.net/30afN
 一次求得計數(count), 均值(mean), 標準差(std), max, min, 中位數, 1/4位數, 3/4位數")
、ravel()與reshape(-1)的完整指南 #flatten(): 總是建立副本")
 ]*>.*?底下插入一個圖檔.*?</w:p>’, flags = re.DOTALL) ; new_xml, n = pattern.subn(”, xml, count=1)' title='Python正則替換:全面掌握 re.sub 與 re.subn 的差異與實戰 #substitute(替換); . 預設匹配「除\n以外的任意單一字元」; pattern = re.compile(r'<w:p[^>]*>.*?底下插入一個圖檔.*?</w:p>’, flags = re.DOTALL) ; new_xml, n = pattern.subn(”, xml, count=1)' loading='lazy' width=350 height=233 />
]*>.*?底下插入一個圖檔.*?</w:p>’, flags = re.DOTALL) ; new_xml, n = pattern.subn(”, xml, count=1)' title='Python正則替換:全面掌握 re.sub 與 re.subn 的差異與實戰 #substitute(替換); . 預設匹配「除\n以外的任意單一字元」; pattern = re.compile(r'<w:p[^>]*>.*?底下插入一個圖檔.*?</w:p>’, flags = re.DOTALL) ; new_xml, n = pattern.subn(”, xml, count=1)' loading='lazy' width=350 height=233 />

 )))")
 與 .get() 的使用指南; dict.pop() 支援第二個參數#key不存在的話,返回第二個參數, list.pop() 不支援第二個參數")
非貪婪模式(.*?) or (.+?),取出以下字串所有被雙引號包圍的部分?response: addr=”0000:01:00.0″ vid=”0x144d” did=”0xa826″ svid=”0x144d” sid=”0xab4c” speed=”16.0GT/s” width=”x4″ max_width=”x4″ expected_width=”x4″ expected_speed=”16.0GT/s” devpath=”/phys/SB_CAB0/DOWNLINK/U2_15:device:nvme:nvme”")


![Python: pandas.Series如何只保留str,去除重複值?#isinstance(x:Any, str) -> bool #.drop_duplicates() #Series.apply( function )逐元素應用function運算 #DataFrame.apply( function )逐Series應用function運算 .drop_duplicates() 跟.unique()有何差別? df.drop_duplicates() 等效於 df[~df.duplicated()] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/11/20241123194900_0_5218de-520x245.png)

近期留言