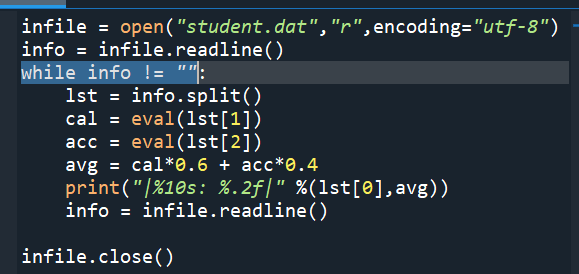
#Python綜合範例13 while info != “” 便一直readline(),Page 9-39
infile = open(“student.dat”,”r”,encoding=”utf-8″)
info = infile.readline()
while info != “”:
lst = info.split()
cal = eval(lst[1])
acc = eval(lst[2])
avg = cal*0.6 + acc*0.4
print(“|%10s: %.2f|” %(lst[0],avg))
info = infile.readline()
infile.close()
“””
.dat檔內容如:
Peter 11 22
Mary 33 44
John 55 66
“””
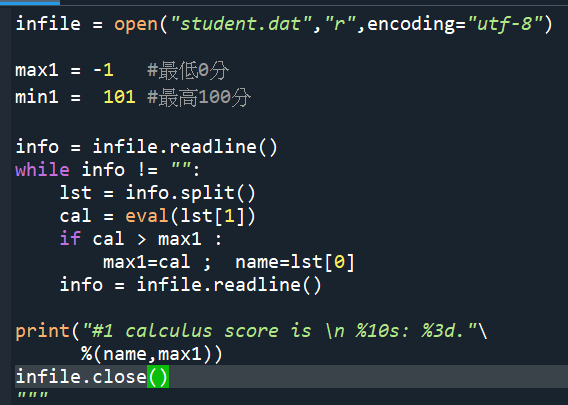
#綜合範例14,微積分最高分
![別把中文洗掉:Python `isalnum()` vs `[^A-Za-z0-9]` 含/不含 CJK中日韓](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/05/20260525082752_0_4776cd.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "別把中文洗掉:Python `isalnum()` vs `[^A-Za-z0-9]` 含/不含 CJK中日韓")
![「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260114094100_0_424ead.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇")
 的 maxsplit 速懂教學(含常見陷阱與實用對比);如何分割標題號 與 標題文字? “3.1.2 Test Strategy”.split(maxsplit=1) #注意中間無底線: 非max_split")
,函數自己呼叫自己,遞迴(Recursive) , dict的value是dict ,巢狀dict,可使用tuple當key,但不可使用list當key")

 > Ctrl + shift +F9 取消所有超連結;參考資料>插入索引>自動標記,隱藏標記後,參考資料>插入索引")
#只接受2D數據 ; from sklearn.preprocessing import StandardScaler ; 儲存/載入 scaler or model: joblib.dump() / joblib.load()")
")
 ; 十六進位hexadecimal(前綴0x) ;前綴可將二,八,十六進位數字轉為十進位 ; 十進位數字轉為二,八,十六進位: bin(number) ; oct(number) ; hex(number)")


近期留言