csv檔請參考前篇:
用 is np.nan 做判斷式
本篇改用isna()重做
DataFrame.drop(labels=None, *, axis=0,
index=None, columns=None,
level=None, inplace=False, errors=’raise’)
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/12/20221206184635_4.png)
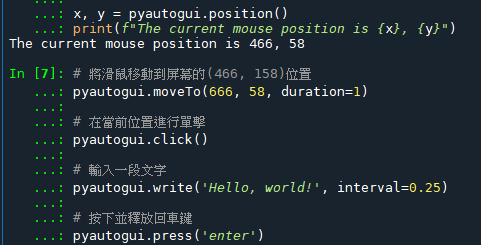
fpath = r”C:\antenna_AMS\21046\emt2csv\01\01test.csv”
import pandas as pd
df_raw = pd.read_csv(fpath,header=None)
boolLst= list( pd.isna( df_raw[0] ) )
print(boolLst)
boolLst1 =pd.isna( df_raw[0] ).tolist()
print(boolLst1) #5,8列同效
#df_raw[0]只要一個[],若使用[[]],
#外觀一樣但型態會變成DataFrame
#tolist()會失敗,list()也會變成[0]
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/12/20221206190216_50.png)
#df_raw[0]: 14列,第4,9列為NaN
nanIdx = []
for i in range(len(boolLst)):
if boolLst[i] == True: nanIdx.append(i)
print(“NaN index:”,nanIdx)
df_drop0 = df_raw.drop(nanIdx,axis=0)
#df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)
#reset_index(drop=True) ,
#可以重置index,並將原index刪除
print(df_drop0)
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/12/20221206185348_86.png)
輸出結果:
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/12/20221206185455_72.png)
推薦hahow線上學習python: https://igrape.net/30afN
 ; 十六進位hexadecimal(前綴0x) ;前綴可將二,八,十六進位數字轉為十進位 ; 十進位數字轉為二,八,十六進位: bin(number) ; oct(number) ; hex(number)")

 ; df.set_index() 將兩欄的df,其中一欄設為index後,其型態是單欄的DataFrame還是Series?")

 排序,參數key = lambda 匿名函式 ;物件導向 def __repr__(self): #原形畢露; def __str__(self): #給人閱讀")

![Python: pandas.DataFrame()處理雙維度資料,dict跟2D list轉為DataFrame有何差別?如何用index及columns屬性客製化index跟欄位名稱?df.index = [“一”,”二”,”三”,”四”] ; df.columns = 使用.head(n) ; .tail(m) ;取首n列,尾m列; .at[index,欄位名稱] 取單一資料 ; .iat[index,欄位順序] 取單一資料 ; .loc[index,欄位名稱] 取資料 ; .iloc[index,欄位順序];df.iloc[ [0,1],[0,2]])取資料 ; df.iloc[ 0:3,0:2]切片](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221111093547_79.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame()處理雙維度資料,dict跟2D list轉為DataFrame有何差別?如何用index及columns屬性客製化index跟欄位名稱?df.index = [“一”,”二”,”三”,”四”] ; df.columns = 使用.head(n) ; .tail(m) ;取首n列,尾m列; .at[index,欄位名稱] 取單一資料 ; .iat[index,欄位順序] 取單一資料 ; .loc[index,欄位名稱] 取資料 ; .iloc[index,欄位順序];df.iloc[ [0,1],[0,2]])取資料 ; df.iloc[ 0:3,0:2]切片")
,計算元大人壽美滿人生(F1) IRR,免費下載IRR計算機")
, chr(), list(str)會把字串的每一個字母拆分進入list中,string跟list都可以使用index定位,沒有非要將string轉為list, for i in str: i 也可以依序代入str的每一個chr")
![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select('標籤名[屬性名1="屬性值1"][屬性名2="屬性值2"]') ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/03/20250330190318_0_925655-520x245.jpg)

近期留言