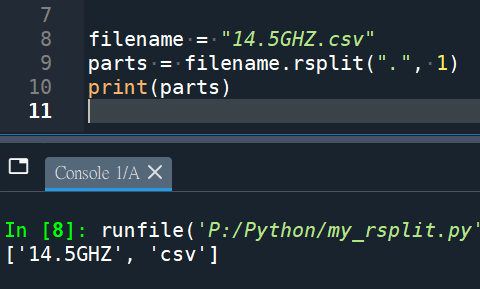
filename = "14.5GHZ.csv"
parts = filename.rsplit(".", 1)
print(parts)使用Python的rsplit()方法,并设置maxsplit参数为1,这样它只会从右侧拆分一次。这样可以确保小数点不被作为拆分点。
輸出結果:
使用正則表示法
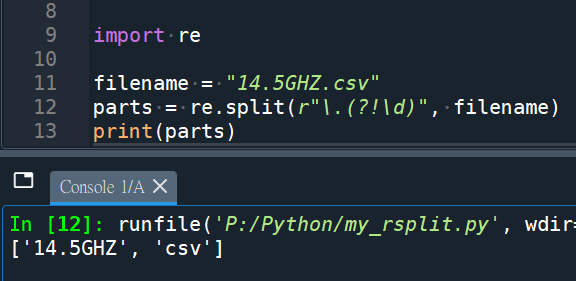
import re
filename = "14.5GHZ.csv"
parts = re.split(r"\.(?!\d)", filename)
print(parts)輸出結果:
使用正则表达式模式\.(?!\d)进行拆分,该模式匹配一个点(.)后面不跟随数字的情况。这样,文件名 “14.5GHZ.csv” 就被拆分为两部分:[‘14.5GHZ’, ‘csv’]。正则表达式模式中的(?!\d)是一个负向前瞻断言,表示后面不应该跟随数字。
使用正则表达式进行拆分可以提供更灵活的拆分规则,以适应各种情况。但需要注意正则表达式的编写和匹配规则,确保满足您的拆分需求。
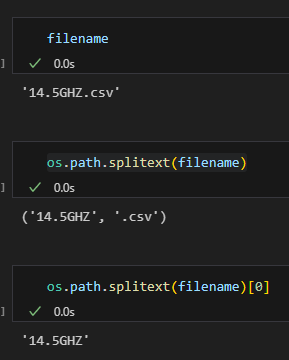
使用os模組:
os.path.splitext(filename)輸出:
推薦hahow線上學習python: https://igrape.net/30afN
 完全解析; from docx.oxml import OxmlElement ; from docx.oxml.ns import qn")
 客戶端:Azure、OpenAI 與 Poe 整合指南")

![Python: pandas.DataFrame的串接 pandas.concat() #concatenate 連接, 如何重新排列columns 順序? df[[“甲”, “乙”, “丙”]] ; df.reindex( columns = [“甲”, “乙”, “丙”] )](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20241120092030_0_98dff3.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame的串接 pandas.concat() #concatenate 連接, 如何重新排列columns 順序? df[[“甲”, “乙”, “丙”]] ; df.reindex( columns = [“甲”, “乙”, “丙”] )")
 正向前瞻 (Positive Lookahead) ; (?!…) 負向前瞻 (Negative Lookahead) ; (?<=…) 正向回顧 (Positive Lookbehind) ; (?<!…) 負向回顧 (Negative Lookbehind) ; re.sub() ; re.split()")


 方法處理鍵不存在的情況; apple_count = my_dict .get( ‘apple’ , 0) # 如果鍵存在,返回對應的值,否則返回預設值 0")
 ; from sklearn.tree import DecisionTreeClassifier ; tree = DecisionTreeClassifier(criterion = “gini”) #criterion = “entropy” #criterion: 標準,準則")


近期留言