code:
"""
資料來源:
https://realpython.com/python-speech-recognition/
pip install sounddevice
pip install scipy
# 注意 要安裝喔!
# 先用 python 看一下版本
# 然後到這邊下載對應的檔案
# https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
pip install PyAudio‑0.2.11‑cp39‑cp39‑win_amd64.whl
"""
# https://pypi.org/project/SpeechRecognition/
import speech_recognition as sr
# import torch
r = sr.Recognizer()
# 預設辨識英文
print(sr.Microphone.list_microphone_names())
# 列出所有的麥克風
print("說一段話,並停3秒 , 就可以辨識語音,如果要結束,就說「離開」")
#source = sr.Microphone(device_index=0)
# 麥克風設定 0 內定
microphone = sr.Microphone()
# 麥克風設定 0 內定
#<speech_recognition.Microphone at 0x2a8dcc5db90>
while True:
with microphone as source:
#<speech_recognition.Microphone at 0x2a8dcc5db90>
r.adjust_for_ambient_noise(source)
# 調整麥克風的雜訊
audio = r.listen(source)
# 錄製的語音
# =========================================================
# r.adjust_for_ambient_noise(microphone)
# 調整麥克風的雜訊
# audio = r.listen(microphone)
# 錄製的語音
# ===========================================================
# File C:\Python311\Lib\site-packages\speech_recognition\__init__.py:383 in adjust_for_ambient_noise
# assert source.stream is not None, "Audio source must be entered before adjusting, see documentation for ``AudioSource``; are you using ``source`` outside of a ``with`` statement?"
#
# AssertionError: Audio source must be entered before adjusting, see documentation for ``AudioSource``; are you using ``source`` outside of a ``with`` statement?
# =============================================================================
# =============================================================================
# str1 =r.recognize_google(audio, key="GOOGLE_SPEECH_RECOGNITION_API_KEY", language="zh-TW")
# str1 = r.recognize_google(audio, language="zh-TW") # 使用Google的服務
#str1 = r.recognize_whisper(audio)
str1 = r.recognize_google(audio, language="zh-TW")
#recognize_google(audio, language="zh-TW") # 使用Google的服務
print("辨識後的文字: " +str1)
if str1 == "離開" or str1.find("離開") >=0 or str1.find("再見") >=0 or str1.find("關閉") >=0 :
break輸出結果:
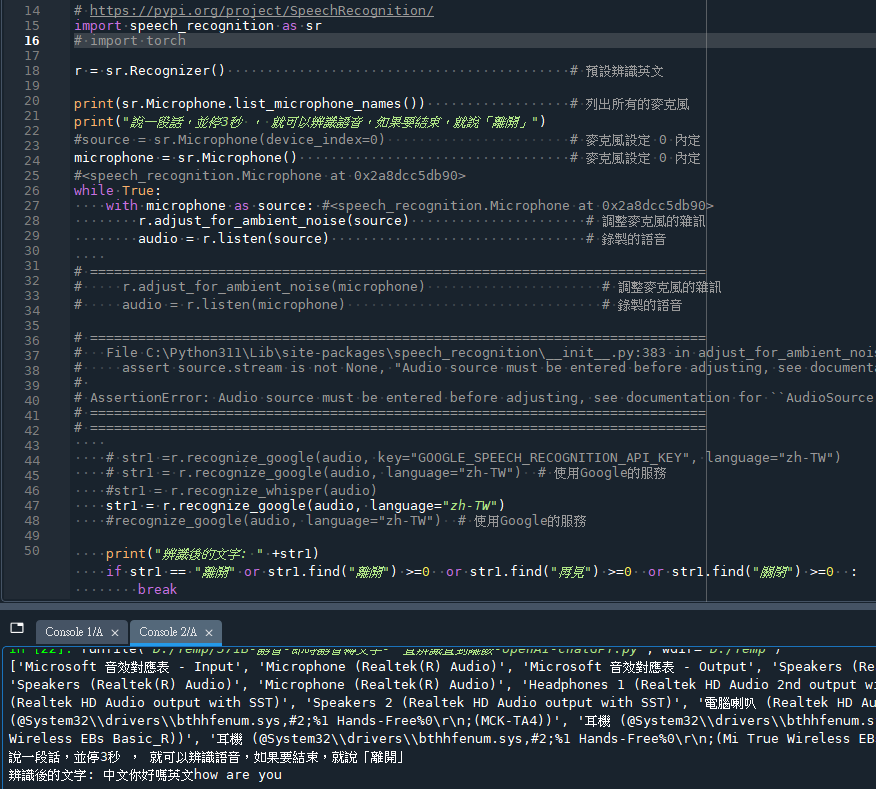
microphone , source 的type都一樣是
speech_recognition.Microphone
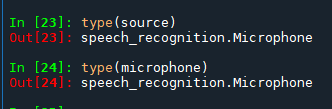
但還是需要:with microphone as source:
後面兩rows 程式碼
若直接引用microphone
會出以下錯誤:
File C:\Python311\Lib\site-packages\speech_recognition__init__.py:383 in adjust_for_ambient_noise
assert source.stream is not None, “Audio source must be entered before adjusting, see documentation for AudioSource; are you using source outside of a with statement?”
AssertionError: Audio source must be entered before adjusting, see documentation for AudioSource; are you using source outside of a with statement?
with microphone as source 这一行代码是为了设置一个上下文管理器,用来管理麦克风设备的资源,确保在使用麦克风时能够正确地打开和关闭它。这是 Python 中一种常见的做法,确保资源被妥善地释放,从而避免资源泄漏或不正常操作。
在这个上下文管理器中,microphone 是 Microphone 类的实例,它代表了麦克风设备。as source 部分表示将 microphone 对象赋给名为 source 的变量,以供后续的操作使用。
通过这个上下文管理器,你可以在 with 块内执行需要使用麦克风的操作,然后在 with 块结束时,上下文管理器会自动关闭麦克风,释放相关资源。这确保了在使用麦克风后,资源被正确释放,不会造成资源泄漏或不正常操作。
总之,with microphone as source 是一种良好的编程习惯,用于管理资源,确保它们在使用后得到适当的释放。这在文件、网络连接、数据库连接等各种资源管理中都是常见的做法。
r.adjust_for_ambient_noise(source) 是 SpeechRecognition 库中的一个方法,用于自动检测并适应环境噪音,以提高语音识别的准确性。这个方法通常在开始录音之前调用,以帮助系统更好地处理录音中的杂音和背景噪音。
具体来说,adjust_for_ambient_noise 方法会执行以下操作:
- 静默环境:在调用此方法之前,系统会检测录音设备的静默环境,以了解在没有声音的情况下的背景噪音水平。
- 适应环境噪音:然后,当
adjust_for_ambient_noise方法被调用时,它会录制一小段时间(通常为1秒)的声音,以获取环境中的噪音水平。这段时间内,用户应该保持沉默,以便系统只记录环境噪音。 - 适应完成:一旦获取了环境噪音水平,
adjust_for_ambient_noise方法将使用这个信息来调整后续的录音,以更好地识别语音内容,减少背景噪音的影响。
通常,这个方法在语音识别之前调用,以确保系统已经了解了当前环境的背景噪音,并可以更好地适应环境。这有助于提高语音识别的准确性,特别是在有噪音的环境中。
在代码示例中,r.adjust_for_ambient_noise(source) 被用于调整 source 对象的环境噪音,以准备进行后续的语音识别。这有助于提高语音识别的质量,尤其是在有噪音的情况下。
r.listen(source) 将等待用户说话,但如果连续3秒内没有检测到声音,它将自动停止录音,并将录制的声音存储在 audio 变量中。这是一个默认的行为,用来检测用户是否已经停止说话。当用户再次说话时,它将再次开始录音。这是一个用来监听语音输入的机制。
因此,如果用户连续3秒没有说话,代码将自动停止录音,并尝试识别停止录音时的声音。如果用户说 “離開” 或类似的关键词,代码将退出循环。这个机制允许用户自行决定何时开始和停止录音。
推薦hahow線上學習python: https://igrape.net/30afN

")
 #文本流輸入輸出封裝器; json.loads(str) 有何差別? 如何跳到文件的一開頭? f.seek(0,0) ; dict的key若重複,後面覆蓋前面")
.resolve().parent")
 ; df.set_index() 將兩欄的df,其中一欄設為index後,其型態是單欄的DataFrame還是Series?")
![Python如何串接OpenAI /Claude /Gemini API自動將大量維修紀錄JSON轉自然語言描述(並避免中斷資料遺失)response = client.chat.completions.create() ; reply = response.choices[0].message.content](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2025/07/20250716084059_0_c5b368.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何串接OpenAI /Claude /Gemini API自動將大量維修紀錄JSON轉自然語言描述(並避免中斷資料遺失)response = client.chat.completions.create() ; reply = response.choices[0].message.content")
讀取無欄標籤的csv檔?= pd.read_csv(“路徑\檔名.副檔名”,header=None) ; print( “{:=^40s}”.format(“傳說中的分隔線”) ) ;置中對齊,不足40字元的部分以=填滿")
 ; 如果y是2D的 pandas.DataFrame ; 如何一次加入所有欄標籤當作圖例(legend)的labels? labels= y.columns.tolist() ; ax.legend(lines, labels)")
 打造不死文檔; from docx.oxml import OxmlElement")

![Python TQC考題610 平均溫度,不要自找麻煩用2D list做,可練習2D轉1D: 一維串列.extend(二維串列[index]) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/05/20220515192908_35-520x245.png)

近期留言