在數據分析中,我們經常需要在長格式(long format)和寬格式(wide format)之間轉換數據。長格式數據每行代表一個觀測值,而寬格式數據則將相關的多個觀測值合併到同一行中。這篇教學將展示如何使用 Pandas 將長格式數據轉換為寬格式。
準備工作:創建示例數據
首先,我們創建一個簡單的長格式數據集作為示例:
import pandas as pd
import numpy as np
# 創建示例數據
data = {
'Net': ['M_CPU0A_SA_DQS', 'M_CPU0A_SA_DQS', 'M_CPU0A_SA_DQ', 'M_CPU0A_SA_DQ'],
'Rank': ['N0.C0.D0.SC0.R0', 'N0.C0.D0.SC0.R0', 'N0.C0.D0.SC0.R0', 'N0.C0.D0.SC0.R0'],
'Test': ['RxDqs-', 'RxDqs+', 'RxDqs-', 'RxDqs+'],
'Mean': [125.3, 118.7, 135.2, 127.9],
'Std Dev': [3.2, 2.9, 3.5, 3.1]
}
df = pd.DataFrame(data)
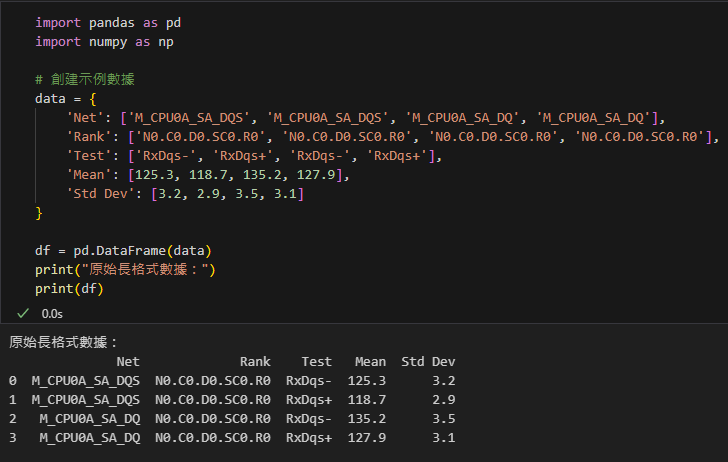
print("原始長格式數據:")
print(df)輸出:
步驟 1:檢查數據是否有重複
在轉換前,先檢查數據中是否存在重複的組合,這是一個良好的習慣:
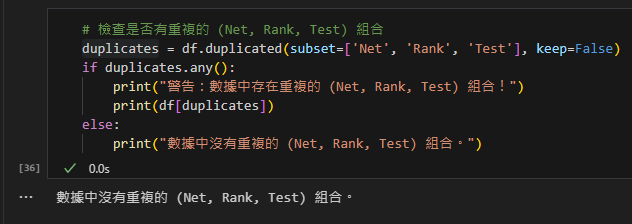
# 檢查是否有重複的 (Net, Rank, Test) 組合
duplicates = df.duplicated(subset=['Net', 'Rank', 'Test'], keep=False)
if duplicates.any():
print("警告:數據中存在重複的 (Net, Rank, Test) 組合!")
print(df[duplicates])
else:
print("數據中沒有重複的 (Net, Rank, Test) 組合。")輸出:
步驟 2:轉換為寬格式
接下來,我們將數據轉換為寬格式。
下面的代碼將為每個統計量(Mean, Std Dev)
創建一個單獨的透視表,然後將它們合併:
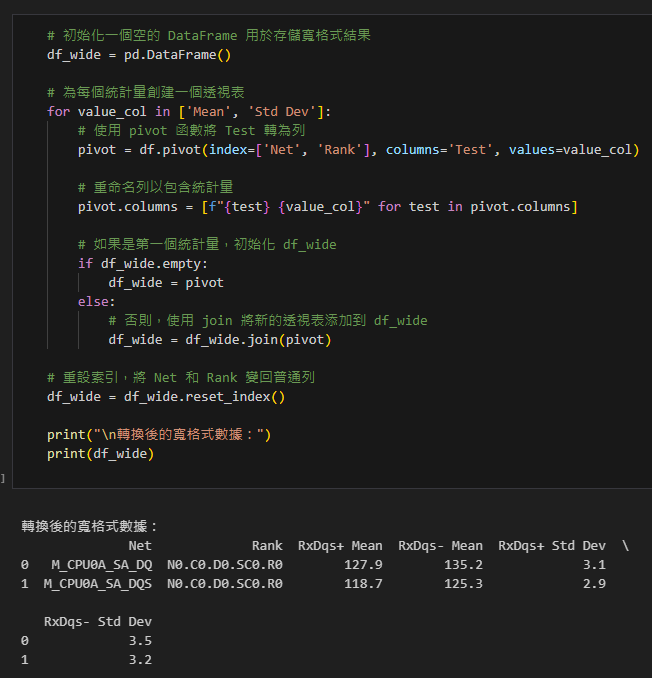
# 初始化一個空的 DataFrame 用於存儲寬格式結果
df_wide = pd.DataFrame()
# 為每個統計量創建一個透視表
for value_col in ['Mean', 'Std Dev']:
# 使用 pivot 函數將 Test 轉為列
pivot = df.pivot(index=['Net', 'Rank'], columns='Test', values=value_col)
# 重命名列以包含統計量
pivot.columns = [f"{test} {value_col}" for test in pivot.columns]
# 如果是第一個統計量,初始化 df_wide
if df_wide.empty:
df_wide = pivot
else:
# 否則,使用 join 將新的透視表添加到 df_wide
df_wide = df_wide.join(pivot)
# 重設索引,將 Net 和 Rank 變回普通列
df_wide = df_wide.reset_index()
print("\n轉換後的寬格式數據:")
print(df_wide)輸出:
深入理解代碼
讓我們更詳細地解釋代碼的每個部分:
1. 初始化空 DataFrame
df_wide = pd.DataFrame()我們首先創建一個空的 DataFrame,稍後將用它來存儲我們的寬格式數據。
2. 循環處理每個統計量
for value_col in ['Mean', 'Std Dev']:我們為每個統計量(Mean, Std Dev)創建單獨的透視表。
3. 創建透視表
pivot = df.pivot(index=['Net', 'Rank'], columns='Test', values=value_col)pivot 函數的工作方式:
index=['Net', 'Rank']:指定哪些列將成為新 DataFrame 的索引(行標識符)columns='Test':指定哪一列的值將成為新 DataFrame 的列values=value_col:指定哪一列的值將填充到新 DataFrame 中
4. 重命名列
pivot.columns = [f"{test} {value_col}" for test in pivot.columns]我們重命名列以包含統計量名稱,例如 “RxDqs- Mean” 和 “RxDqs+ Std Dev”。
5. 合併透視表
if df_wide.empty:
df_wide = pivot
else:
df_wide = df_wide.join(pivot)- 如果
df_wide是空的(第一次循環),我們直接將pivot賦值給它 - 否則,我們使用
.join()方法將新的透視表合併到df_wide中
join 方法將兩個 DataFrame 基於它們的索引合併。
在這個例子中,兩個透視表有相同的索引(Net, Rank),
所以它們可以完美地合併。
6. 重設索引
df_wide = df_wide.reset_index()最後,我們使用 reset_index()
將多級索引(Net, Rank)轉換為普通col,
使得最終結果更易於閱讀和處理。
推薦hahow線上學習python: https://igrape.net/30afN

")
、ravel()與reshape(-1)的完整指南 #flatten(): 總是建立副本")


的Button?一按就刪除掉Label + Entry + Button ; trash_icon = tk.PhotoImage( file = trash_icon_path)")
")
![Python: 如何用 pandas.DataFrame.apply 讓DataFrame增加新的一欄 ; df[“mean”] = df.apply( np.mean, axis=1) ; DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230519084320_22.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何用 pandas.DataFrame.apply 讓DataFrame增加新的一欄 ; df[“mean”] = df.apply( np.mean, axis=1) ; DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)")

![Python如何串接OpenAI /Claude /Gemini API自動將大量維修紀錄JSON轉自然語言描述(並避免中斷資料遺失)response = client.chat.completions.create() ; reply = response.choices[0].message.content - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/07/20250716084059_0_c5b368-520x245.png)

近期留言