#Python TQC考題802 字元對應
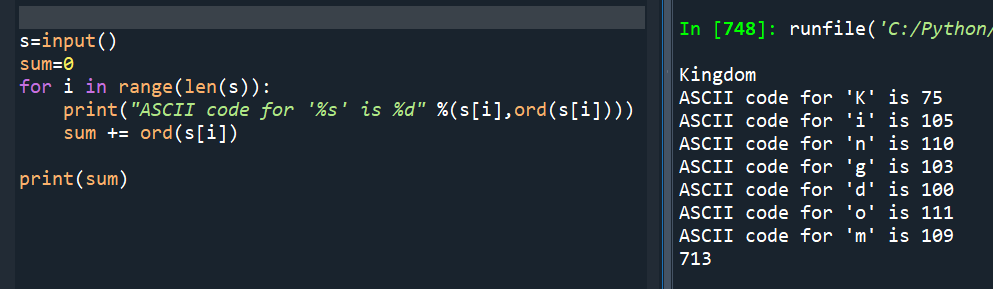
s=input()
sum=0
for i in range(len(s)):
print(“ASCII code for ‘%s’ is %d” %(s[i],ord(s[i])))
#右邊有))) 三個,也是會錯的地方
#先寫s[i],再用ord()包覆
#chr() 則是ord()的反向,把ASCII碼轉為字母
sum += ord(s[i])
print(sum)
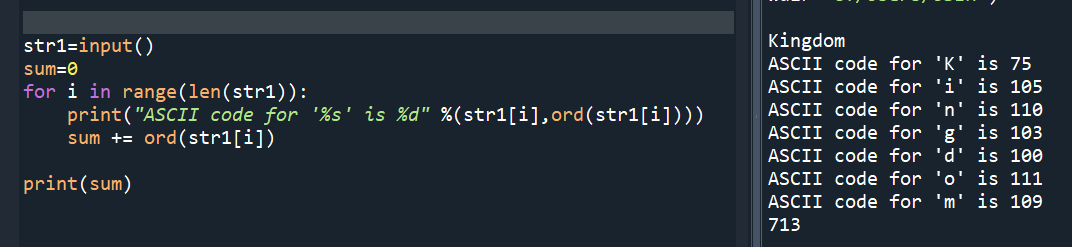
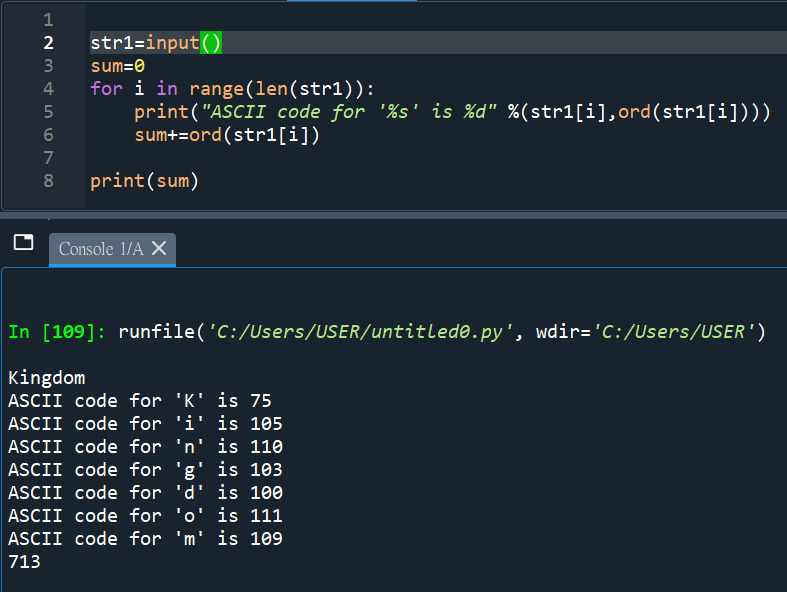
#再練習一次:
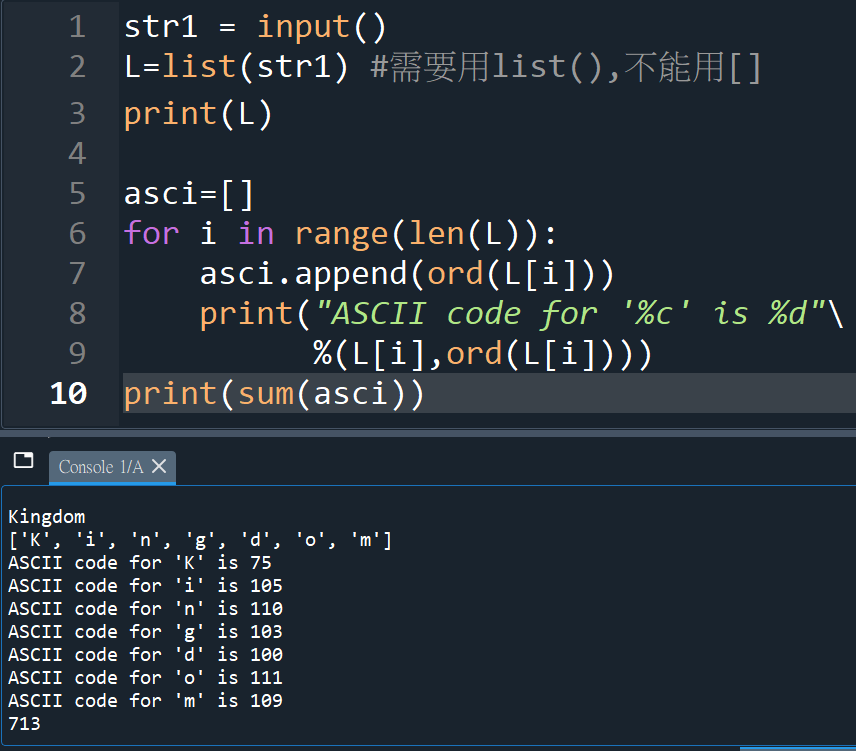
#多使用了list(str)的技巧
#不能用[ str ],要 list(str)
#字串才會每個字母拆開進入list中
“””
string跟list一樣,
都可以使用index定位
其實沒有非要做 =list(string)
就是list比string常用
直覺會這麼做
“””
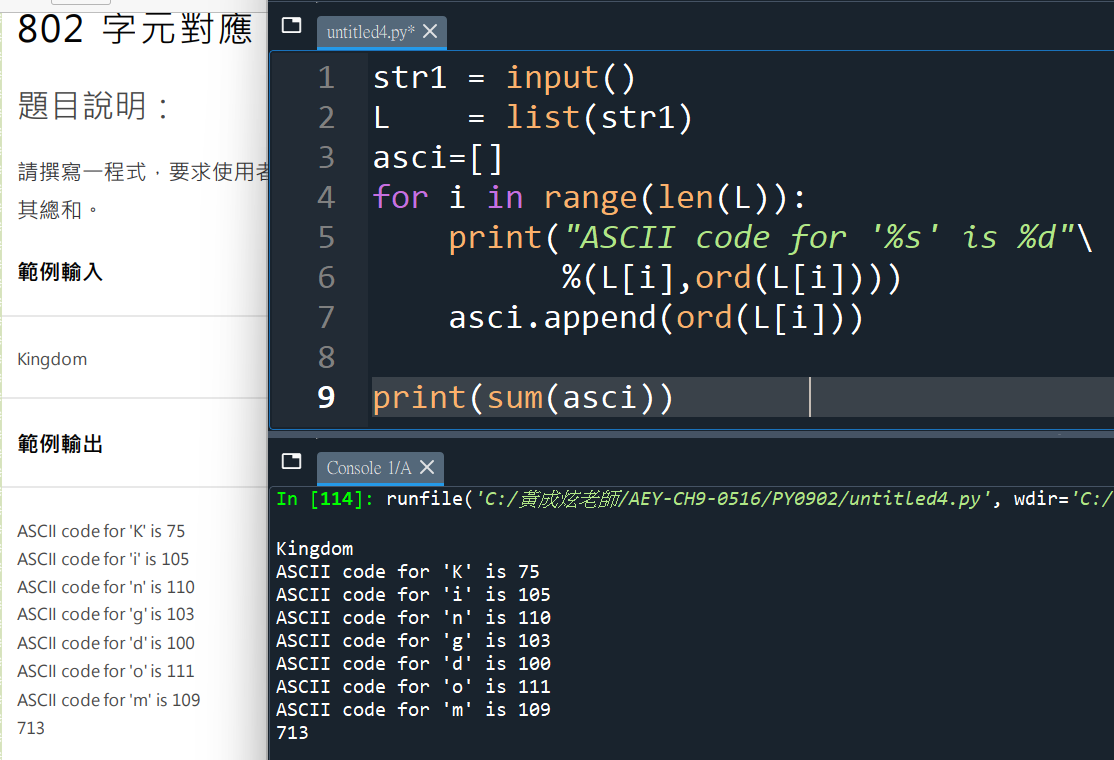
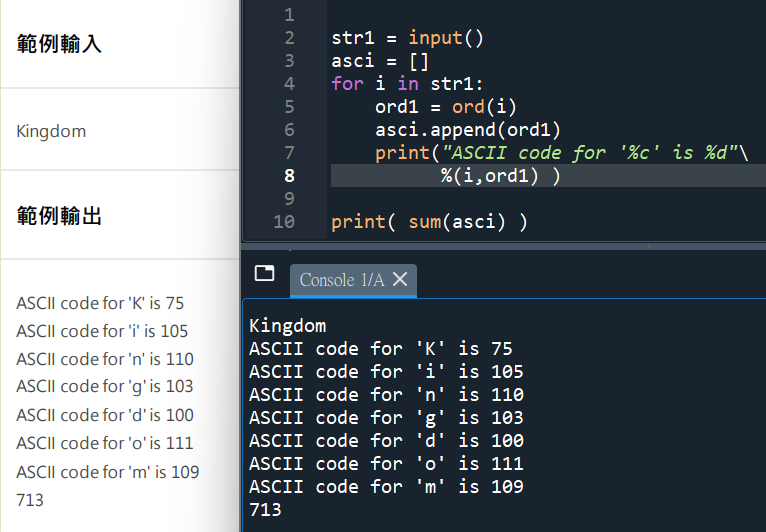
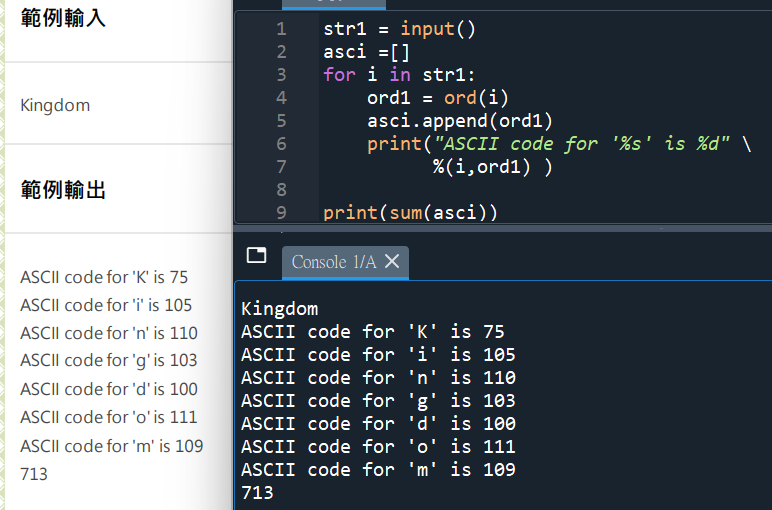
#覺得ord( str1[i] )太長的話,可以先令他等於ord1:
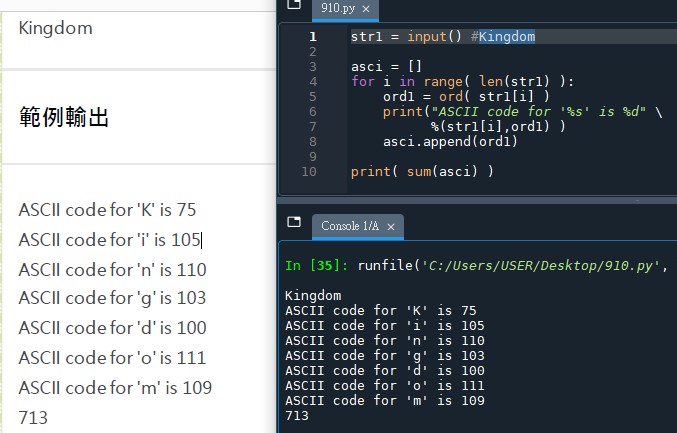
# for i in str1:
#跟list的用法一樣
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df[‘Salary’] = df[‘Salary’].map( ‘${:,.2f}’ .format)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230527091636_49.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df[‘Salary’] = df[‘Salary’].map( ‘${:,.2f}’ .format)")
 ,19歲奧運跆拳銅牌美少女羅嘉翎的國光獎金,應該一次領500萬?還是終身月領2.4萬?Excel財務函數PMT, RATE, NPER, PV, FV")
 or(|) xor(^) not")
; typing : np.ndarray")
 API? MIME (Multipurpose Internet Mail Extensions)")





近期留言