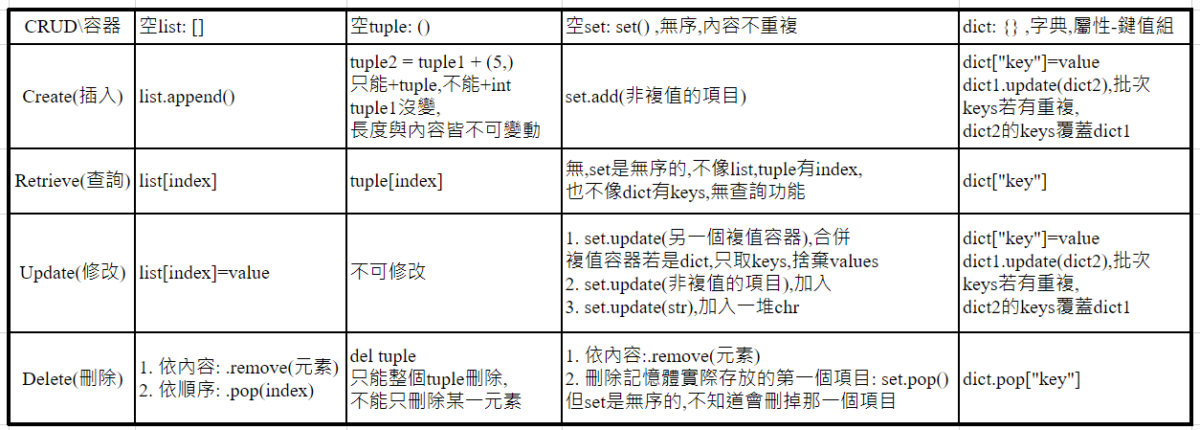
| CRUD\容器 | 空list: [] | 空tuple:() | 空set: set() ,無序,內容不重複 | dict:{} ,字典,屬性-鍵值組 |
| Create(插入) | list.append() | tuple2 = tuple1 + (5,) 只能+tuple,不能+int tuple1沒變, 長度與內容皆不可變動 |
set.add(非複值的項目) | dict[“key”]=value dict1.update(dict2),批次 keys若有重複, dict2的keys覆蓋dict1 |
| Retrieve(查詢) | list[index] | tuple[index] | 無,set是無序的,不像list,tuple有index, 也不像dict有keys,無查詢功能 |
dict[“key”] |
| Update(修改) | list[index]=value | 不可修改 | 1. set.update(另一個複值容器),合併 複值容器若是dict,只取keys,捨棄values 2. set.update(非複值的項目),加入 3. set.update(str),加入一堆chr |
dict[“key”]=value dict1.update(dict2),批次 keys若有重複, dict2的keys覆蓋dict1 |
| Delete(刪除) | 1. 依內容: .remove(元素) 2. 依順序: .pop(index) |
del tuple 只能整個tuple刪除, 不能只刪除某一元素 |
1. 依內容:.remove(元素) 2. 刪除記憶體實際存放的第一個項目: set.pop() 但set是無序的,不知道會刪掉那一個項目 |
dict.pop[“key”] |
基本容器:
函式操作:

推薦hahow線上學習python: https://igrape.net/30afN
 — 使用 groupby(“Name”).cumcount, set_index 與 unstack 將長格式轉為寬格式")


 ; median_np = numpy .nanmedian(arr)")
, x)` ; sorted(items, key=lambda x: (-len(x), x)) 與 json_repair strategy pipeline")
")
 套件繪製具有多個子圖的折線圖? sns.relplot(data=tips, x=’total_bill’, y=’tip’, hue=’sex’, col=’day’, row=’time’, facet_kws={‘margin_titles’: True}, height=3, aspect=1.2).set_axis_labels(‘Total Bill’, ‘Tip’)")
![一文搞懂Python pandas.DataFrame去重:df.drop_duplicates() 與 df[~df.duplicated()] 的等價、差異與最佳實踐](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/08/20250808202701_0_66f9bc.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "一文搞懂Python pandas.DataFrame去重:df.drop_duplicates() 與 df[~df.duplicated()] 的等價、差異與最佳實踐")
; ip addr ; hostname -I查詢ip address")



近期留言