re.compile() 是 Python 的 re 模組(正則表達式模組)中的一個函數,用於編譯正則表達式模式,生成一個正則表達式對象。這個對象可以用來進行模式匹配,並且編譯過的正則表達式可以重複使用,提高匹配效率。
使用 re.compile() 的優勢
- 提高效率:編譯過的正則表達式對象可以重複使用,避免每次匹配時都重新編譯正則表達式,從而提高性能。
- 可讀性:將正則表達式模式與使用它的代碼分開,可以提高代碼的可讀性和可維護性。
正則表達式對象的方法
編譯過的正則表達式對象提供了多種方法來進行模式匹配和查找,包括:
match():從字符串的開始位置匹配。search():在字符串中查找第一個匹配的子串。findall():查找字符串中所有匹配的子串,並返回它們的列表。finditer():查找字符串中所有匹配的子串,並返回它們的迭代器。sub():替換字符串中所有匹配的子串。
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 13 06:58:30 2024
@author: SavingKing
"""
import re
# 編譯正則表達式
pattern = re.compile(r'\d+')
#re.Pattern
text = ' 123abc456def789ghi'
#前面故意多一個空白
#.match() 不會匹配
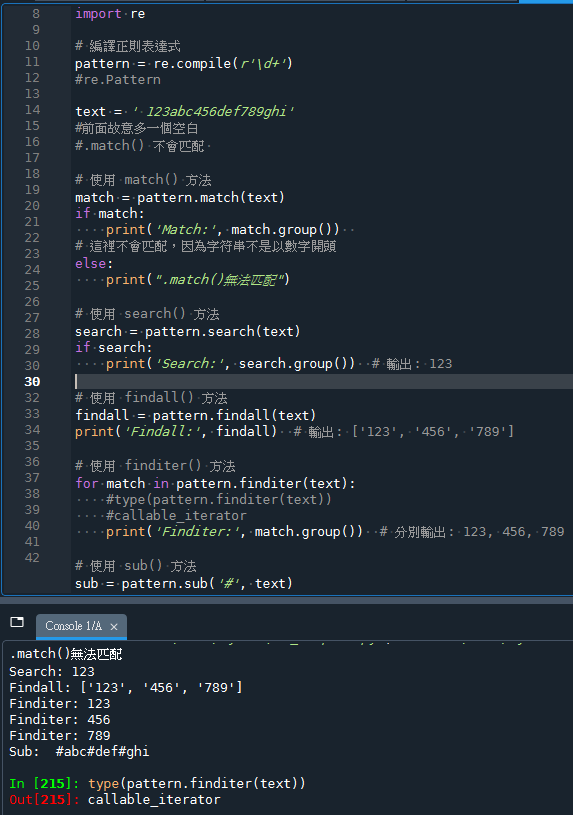
# 使用 match() 方法
match = pattern.match(text)
if match:
print('Match:', match.group())
# 這裡不會匹配,因為字符串不是以數字開頭
else:
print(".match()無法匹配")
# 使用 search() 方法
search = pattern.search(text)
if search:
print('Search:', search.group()) # 輸出: 123
# 使用 findall() 方法
findall = pattern.findall(text)
print('Findall:', findall) # 輸出: ['123', '456', '789']
# 使用 finditer() 方法
for match in pattern.finditer(text):
#type(pattern.finditer(text))
#callable_iterator
print('Finditer:', match.group()) # 分別輸出: 123, 456, 789
# 使用 sub() 方法
sub = pattern.sub('#', text)
print('Sub:', sub) # 輸出: #abc#def#ghi輸出結果:
推薦hahow線上學習python: https://igrape.net/30afN
使用re.compile()
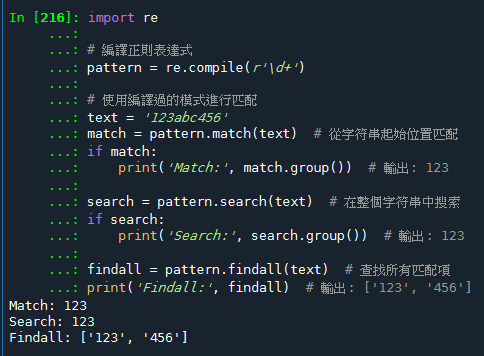
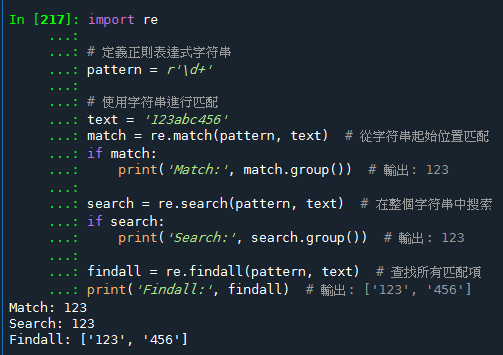
直接使用字符串:
小結
- 使用
re.compile():將正則表達式模式編譯成對象後,可以重複使用這個對象進行多次匹配操作,代碼更高效且易讀。 - 直接使用字符串:僅定義了一個正則表達式模式的字符串,每次使用時都需要通過
re模組的函數來進行匹配操作,效率較低。
總之,當需要頻繁使用同一個正則表達式模式時,使用 re.compile() 會更合適。而如果只是偶爾使用一次,可以直接使用字符串模式。
,Skip Record If")
 ; ax.xaxis.set_minor_locator(minor_locator)")

![Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220923222039_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言")


元素不會重複,strNew=str1.replace(” “,””)")
, x)` ; sorted(items, key=lambda x: (-len(x), x)) 與 json_repair strategy pipeline")
![Python如何讀取*.jsonl (JSON Lines)? 讀取為List[dict]](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/10/20231024225613_30.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何讀取*.jsonl (JSON Lines)? 讀取為List[dict]")

近期留言