- 為什麼要理解底層 XML?
python-docx 已包裝大部分常用操作(新增段落、表格、圖片),但當你要:
精準刪除一個“章節”含其內文與表格
重建自訂編號(忽略內建 numPr)
對底層元素做結構檢查(例如遺失 )
解析/重寫拆成多個 run 的標題編號 就需要進入底層 WordprocessingML(Word XML)層次操作。
- WordprocessingML 是什麼?
ML = Markup Language(標記語言),不是 Machine Learning。
.docx 是一個 Zip;文字主體在 word/document.xml。
名稱空間(Namespace)核心:http://schemas.openxmlformats.org/wordprocessingml/2006/main(常簡寫 w:)。
lxml 內部用“expanded QName”表示:{namespace}localname。因此比對 tag 需要 qn(‘w:p’) 而不是 ‘w:p’。 - 頂層結構概覽
<w:document>
<w:body>
<w:p>...</w:p>
<w:tbl>...</w:tbl>
...
<w:sectPr>...</w:sectPr>
</w:body>
</w:document>實務上在 w:body 直接子節點常見:
w:p:段落(Heading、一般文字、內含超連結、書籤等)
w:tbl:表格
w:sectPr:末尾節屬性(確保存在) 其餘像 w:sdt(內容控制)、w:altChunk(外部嵌入)、w:customXml、修訂標記,多在進階文件出現。
- 內部段落層級
w:p
├─ w:pPr(段落屬性:樣式、對齊、numPr、分節)
├─ w:bookmarkStart / w:bookmarkEnd
├─ w:r (run)
│ ├─ w:rPr(粗體、顏色…)
│ ├─ w:t(文字)
│ ├─ w:br(換行)
│ └─ w:drawing(圖片)
├─ w:hyperlink(包 run)
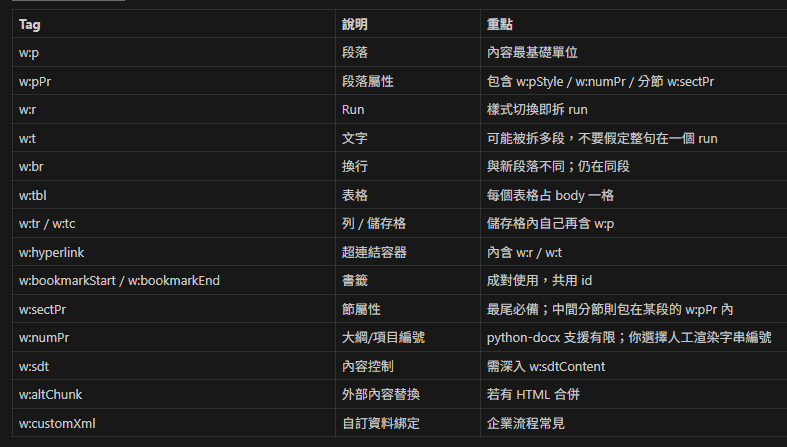
└─ ...5. 常用標籤速查
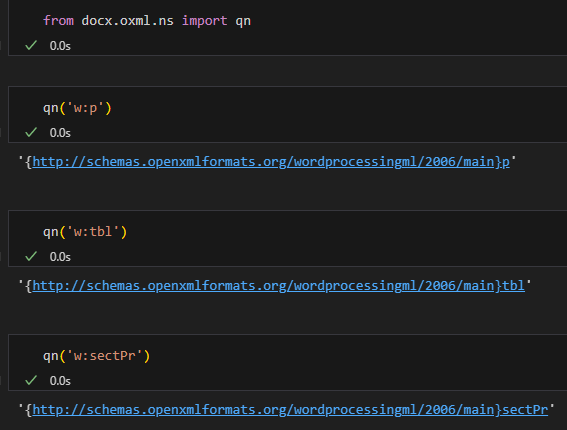
6. qn() 的用途
from docx.oxml.ns import qn
W_P = qn('w:p')
if element.tag == W_P:
...
"""
qn('w:p')
'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}p'
qn('w:tbl')
'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}tbl'
qn('w:sectPr')
'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}sectPr'
或者使用
if type(elem).__name__ == "CT_P": #CT_Tbl #CT_SectPr
也是實用的方法
"""qn(‘w:p’) 會回傳
'{http://schemas.openxmlformats.org/wordprocessingml/2006/main}p'。
比對 element.tag 時必須用 expanded QName;不要直接 'w:p'。
其他的qn:
- 解析標題編號:為什麼不用內建大綱
內建大綱(numPr)常在刪段落後殘留不連續的顯示。
策略:掃描純文字 → 切出原始 number_text → 根據出現層級重建 full_number_path → 重寫 run 前綴。
優點:行為可控、跨亂格式(多 run)的韌性高。
缺點:失去 Word 內建大綱自動更新;TOC(目錄)需手動更新或重建。 - Minimal Parser + Regex Fallback(標題解析)
策略:
Fast path:掃前綴 [0-9.],驗證不以 . 開頭 / 不以 . 結尾 / 不含 ..
無法解析 → regex fallback(允許括號、全形、破折號)
解析失敗 → 視為無編號(level=None),用結構位置重新生成 full_number_path
好處:效能高、失敗類型清晰可統計。
- 頂層安全迭代模式
from docx.oxml.ns import qn
W_P = qn('w:p'); W_TBL = qn('w:tbl'); W_SECTPR = qn('w:sectPr')
def iter_body_blocks(doc):
body = doc.element.body
for el in body:
if el.tag == W_P:
yield ('paragraph', el)
elif el.tag == W_TBL:
yield ('table', el)
elif el.tag == W_SECTPR:
yield ('sectPr', el)
else:
yield ('unknown', el) # 防禦當遇到 w:sdt 等進階類型可再展開。
- 確保文件末尾
<w:sectPr>存在
刪除章節時可能把尾端節屬性刪掉,需修復:
def ensure_trailing_sectPr(doc):
body = doc.element.body
sects = [el for el in body if el.tag.endswith('sectPr')]
if not sects:
from docx.oxml import OxmlElement
body.append(OxmlElement('w:sectPr'))
else:
last = sects[-1]
if body[-1] is not last:
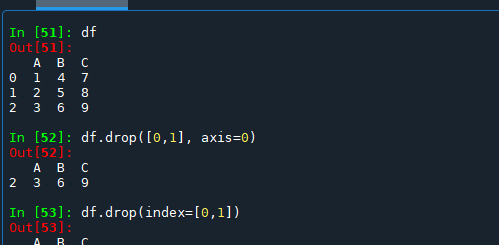
body.append(last)- 刪除章節的關鍵:使用 body index 而非 paragraphs index
doc.paragraphs 不包含表格,刪除表格時會錯位。
流程:先構建 headings(以 body enumeration index),再用 start:end 切掉範圍內元素。 - Run 分裂問題與重寫編號
Word 可能把 9.5.3\tSDC test 切成:
run0: ' '
run1: '9.'
run2: '5.3'
run3: '\t'
run4: 'SDC test'處理方法:
- 逐 run 逐字狀態機:leading_ws → digits → sep → done
- 錄下 cut_position(正文開始)
- 清空覆蓋範圍 run 內容
- 第一個 run 寫入新編號 + 分隔符 + 殘餘正文片段
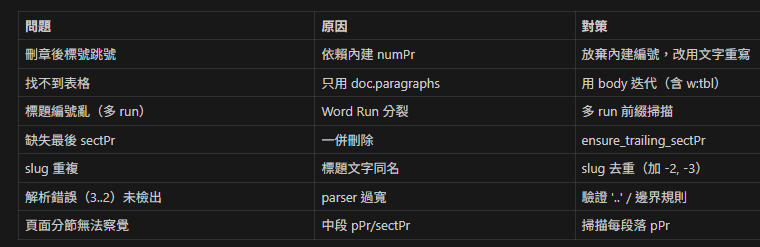
13. 常見陷阱與對策
14. 提升可追溯性(建議)
輸出 headings JSON 時加:
{
"version": 1,
"source_template": "...docx",
"renumbered": true,
"removed_titles": ["9\\tL10 Test Plan"],
"headings": [
{
"full_number_path": "7.5.1",
"number_text": "9.5.3",
"title": "SDC test",
"is_numbering_correct": false
}
]
}15. Debug 工具建議
def dump_paragraph_structure(p):
print("TEXT:", repr(p.text))
for i, r in enumerate(p.runs):
print(f" run {i}: {repr(r.text)}")
for child in r._r:
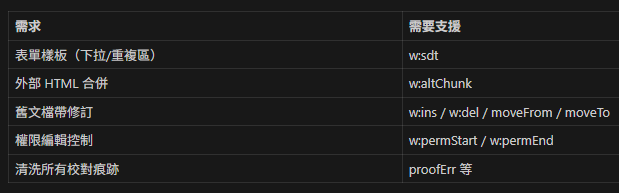
print(" tag:", child.tag.split('}')[-1])16. 何時要擴充頂層辨識
初期專案→ 可以不處理;只 log unknown 提醒。
17. 範例:快速列出 body 結構
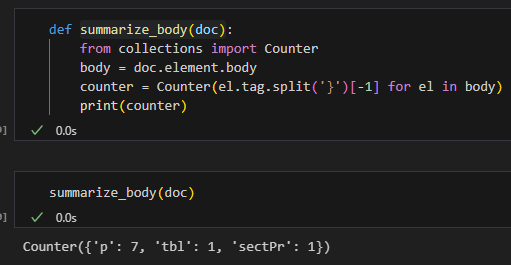
def summarize_body(doc):
from collections import Counter
body = doc.element.body
counter = Counter(el.tag.split('}')[-1] for el in body)
print(counter)輸出:
18. 一句話總結
“掌握 w:body 的 3 類核心頂層元素(段落 / 表格 / 末節屬性)、在段落內精準處理 run/超連結/書籤、使用自建編號取代內建大綱,並用防禦性解析與結構檢查確保刪改後的 .docx 可預期。”
推薦hahow線上學習python: https://igrape.net/30afN

 ; json的保留字:null, true, false(區分大小寫,全小寫), null(非”null”,非Null)自動轉譯為None, true(非”true”,非True)自動轉譯為True(bool), false(非”false”,非False)自動轉譯為False(bool);colab如何掛載雲端硬碟? from google.colab import drive ; json檔的decode與encode? json.load() ; json.loads() ; json.dump() ; json.dumps() #s代表string的意思,有s的指令,參數需使用str type")
 ; 十六進位hexadecimal(前綴0x) ;前綴可將二,八,十六進位數字轉為十進位 ; 十進位數字轉為二,八,十六進位: bin(number) ; oct(number) ; hex(number)")

")

函式切片出兩個 pandas.Series 重複的元素? ser_bool = 長的Series.isin (短的Series); numpy.bool_ ; WR75 WR42 WR28頻段為何?")
")

![Python socket連線出現[WinError 10049] 內容中所要求的位址不正確 cmd.exe: ipconfig/all ; TCP/IPv4 vs IPv6 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/10/20221028151556_42-520x245.png)

近期留言