在 Python 的正則表達式模組中,
re.Match 物件的 .group() 方法行為是固定的,
.group(0) 和 .group(1) 的作用完全不同,
它們並不相同
.group(0) #等效於.group()
表示整個正則表達式匹配到的內容。
它返回的是整個匹配字符串,
無論正則表達式中有多少捕獲組(括號 ())。
輸出類型:一個 str
.group(1)
表示第一個捕獲組(())匹配到的內容。
如果正則表達式中帶有捕獲組(即括號 ()),
.group(1) 會返回第一個捕獲組內匹配的內容。
輸出類型:一個 str
有捕獲組的正則表達式
假設你有以下字符串和正則表達式:
import re
line = "device: 1"
pattern = r"device: (\d+)" # 捕獲數字部分
device_match = re.search(pattern, line)
if device_match:
print(".group(0):", device_match.group(0)) # 整個匹配結果
print(".group(1):", device_match.group(1)) # 第一個捕獲組輸出結果:
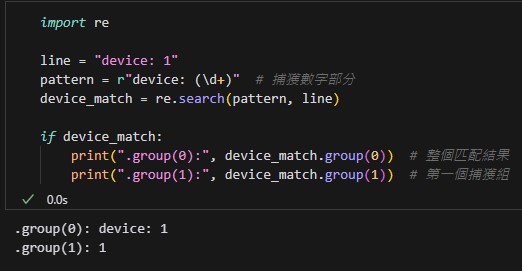
.group(0) 返回的是整個正則表達式匹配的內容 “device: 1″。
.group(1) 返回的是第一個捕獲組,即括號 () 匹配到的內容 “1”。
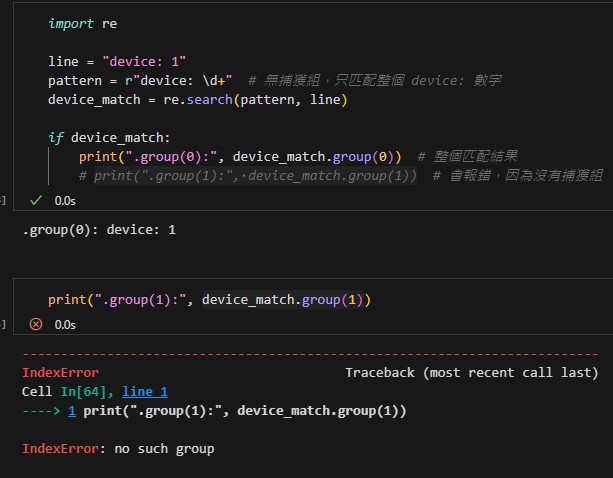
沒有捕獲組的正則表達式
如果正則表達式中沒有捕獲組,
只有 .group(0) 有效,因為 .group(1) 將導致錯誤:
捕獲組數量多的情況
如果正則表達式中有多個捕獲組,
.group(n) 可以提取對應的捕獲組內容:
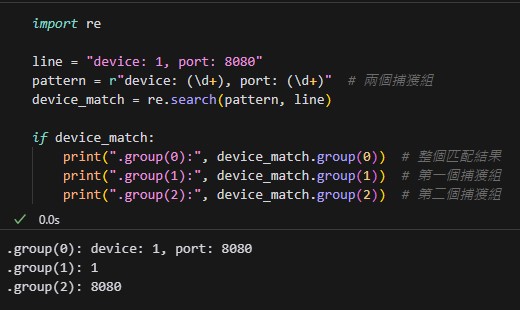
.group(0):返回整個匹配的內容。
.group(1):返回第一個捕獲組匹配的內容,即 1。
.group(2):返回第二個捕獲組匹配的內容,即 8080。
正則表達式的 re.Match 物件中,
只有 .groups() 會返回所有捕獲組的元組(tuple)
.groups()
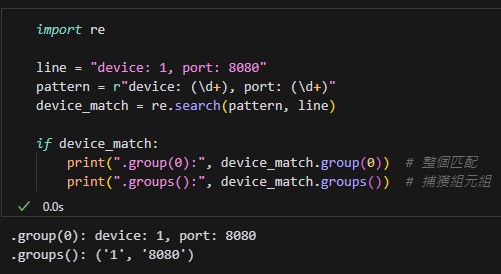
.group(0) 和 .group(1) 的區別:
.group(0):整個正則表達式的匹配結果。
.group(1):第一個捕獲組的匹配內容。
數據類型:
.group(0) 和 .group(1) 都返回 str
推薦hahow線上學習python: https://igrape.net/30afN
![Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221112184006_50.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python常用的模組內建常數; __name__ ; __file__ ; __doc__ ; __all__ ;__dict__; vars()->Dict[str,str] ; dir()->List[str]")
![Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df[‘Salary’] = df[‘Salary’].map( ‘${:,.2f}’ .format)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230527091636_49.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame 如何對某些欄做格式化字串? apply(); applymap() ; map() 的差別? df[‘Salary’] = df[‘Salary’].map( ‘${:,.2f}’ .format)")

; from bs4 import BeautifulSoup")

![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby([‘name’]) .size() .reset_index(name=’count’)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230316131103_65.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby([‘name’]) .size() .reset_index(name=’count’)")
![Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = “[\d]{4}\/[01][\d]\/[0123][\d] [\d]{6}” ; match = re .search (pattn,text) .group()](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220901154435_19.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: Regular Expression 正規表示法 正則表達式 import re ; pattn = “[\d]{4}\/[01][\d]\/[0123][\d] [\d]{6}” ; match = re .search (pattn,text) .group()")


![為什麼 Python 要用 `max` 配合 `key=lambda`?從找最長文字的 Span 談起 ; #spans:list[dict] ; max(spans, key=lambda s: len(s.get("text", ""))) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/06/20260602132524_0_c45d06-520x245.png)
![Word短篇文件編輯,TQC考題110:重點摘要與評量, [(*)] 萬用字元,格式>醒目提示*2次=非醒目提示 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/03/20220322172253_75-520x245.png)

近期留言