✅ 適用時間點:2026 年
✅ 作業系統:Windows 10 / 11
✅ Python:3.11
✅ OCR 引擎:PaddleOCR 2.7.x
✅ 目標:穩定、不踩 NumPy 2.x ABI 雷
目錄
- 為什麼一定要用虛擬環境
- 建立 Python 虛擬環境(venv)
- VS Code 切換 Interpreter(關鍵)
- Jupyter Notebook 使用正確 Interpreter
- 套件版本地雷總整理(⚠️ 重點)
- 正確安裝 PaddleOCR(不爆炸版)
- 四行指令確認環境
- 第一支 PaddleOCR 程式
- 常見錯誤與判斷方式
- 結論與最佳實務
1️⃣ 為什麼一定要用虛擬環境?
結論先講:不用 venv,PaddleOCR 幾乎一定會炸。
原因不是你操作錯,而是:
- NumPy 2.x 破壞 ABI 相容性
- PaddlePaddle 2.6.x 仍使用 NumPy 1.x 編譯
- pip 會「好心」幫你升級到最新,然後炸掉
👉 唯一正解:一個專用 venv
2️⃣ powershell建立 Python 虛擬環境(venv)
假設 Python 已安裝(python --version 能跑)
cd D:\user\Python
python -m venv venv-paddleocr啟動虛擬環境(PowerShell):
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\venv-paddleocr\Scripts\activate看到:

✅ 成功
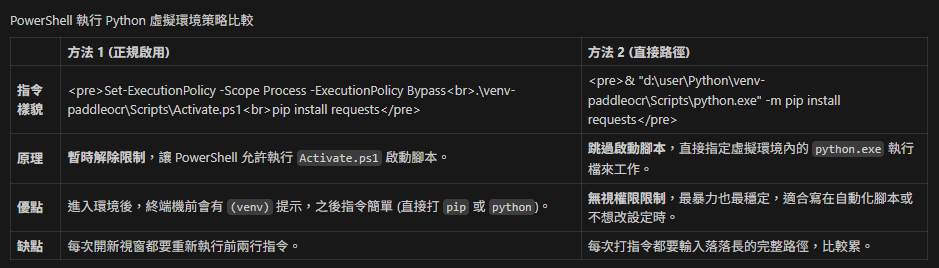
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass這條指令的意思是在當前這個 PowerShell 視窗(進程)中,暫時繞過執行策略的限制,允許執行任何腳本。
詳細分解如下:
Set-ExecutionPolicy: 這是用來設定 PowerShell 執行策略(安全規則)的指令。
-Scope Process: 指定設定的範圍僅限於「目前的執行程序」(Process)。
這意味著這個變更只對你現在開著的這個視窗有效。
一旦你關閉了這個視窗,設定就會失效,不會影響到你電腦整體的安全性設定。
-ExecutionPolicy Bypass: 將策略設定為「Bypass」(繞過)。
在這個模式下,沒有任何限制,也不會出現警告或提示。
所有的腳本(包含從網路下載未簽署的腳本)都可以直接執行。
總結:
這通常用在你需要執行某個腳本(例如安裝某些開發工具或環境),但被系統預設較嚴格的安全設定(如 Restricted)擋住時。這是一個相對安全的做法,因為它只影響當次操作,不會永久降低系統的防護等級。
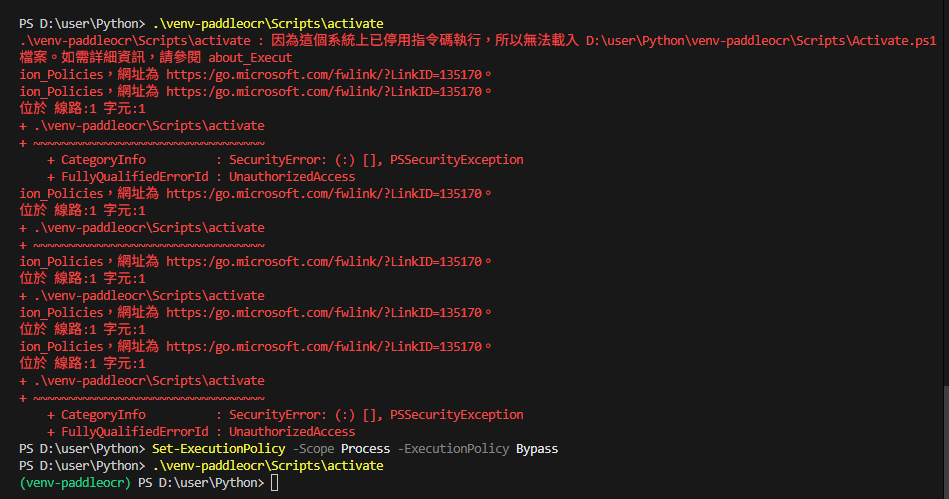
或者繞過 PowerShell 的限制,直接呼叫了虛擬環境裡的執行檔:
d:\user\Python\venv-paddleocr\Scripts\python.exe -m pip install requests
結果:顯示 Requirement already satisfied … in d:\user\python\venv-paddleocr\lib\site-packages。
這行訊息證明了 requests 已經確實安裝在 PaddleOCR 虛擬環境中了。
在 VS Code 中,只要使用「Python: Select Interpreter」或 Notebook Kernel 切換,
實際上並不會執行 activate.ps1,因此也不會受到 PowerShell ExecutionPolicy 限制。Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
僅在「手動於 PowerShell 啟用 venv」時才需要。
3️⃣ VS Code 切換 Python Interpreter(⚠️ 非常重要)
✅ 方法一(推薦)
Ctrl + Shift + P- 輸入:
Python: Select Interpreter - 選擇:
...\venv-paddleocr\Scripts\python.exe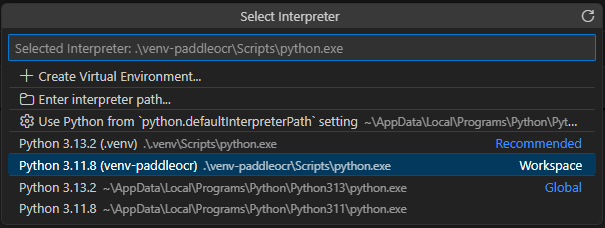
✅ 方法二(右下角)
- 點擊右下角 Python 版本
- 切換到
venv-paddleocr
📌 不切 Interpreter = 用錯 Python = 套件裝到別的地方
4️⃣ Jupyter Notebook 使用正確 Interpreter
✅ 在 venv-paddleocr 中安裝 Jupyter
pip install jupyter ipykernel✅ 把 venv 加入 kernel
python -m ipykernel install --user --name venv-paddleocr --display-name "Python (paddleocr)"✅ 在 Notebook 右上角選:
✅ 這一步沒做,Notebook 會偷用系統 Python
5️⃣ 套件版本地雷總整理(⚠️ 必看)

6️⃣ 正確安裝 PaddleOCR(不踩雷流程)
✅ Step 1:安裝 NumPy(先)
pip install numpy==1.26.4✅ Step 2:安裝 PaddlePaddle(CPU)
pip install paddlepaddle==2.6.2✅ Step 3:安裝 OpenCV(相容版)
pip install opencv-python-headless==4.6.0.66
# 這個版本的 OpenCV 不包含任何圖形使用者介面(GUI)的功能與依賴。
# 簡單來說:它沒有「頭」(螢幕/視窗),只有「身體」(運算核心)。✅ Step 4:安裝 PaddleOCR
pip install paddleocr==2.7.37️⃣ 四行指令確認環境(工程版)
python -c "import numpy; print('numpy', numpy.__version__)"
python -c "import paddle; print('paddle', paddle.__version__)"
python -c "import cv2; print('opencv', cv2.__version__)"
python -c "import paddleocr; print('paddleocr', paddleocr.__version__)"正確輸出:
numpy 1.26.4
paddle 2.6.2
opencv 4.6.0
paddleocr 2.7.3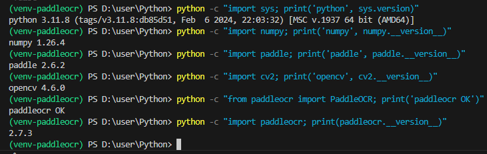
✅ 到這裡,環境 已可交付
8️⃣ 第一支 PaddleOCR 程式(英文截圖)
from paddleocr import PaddleOCR # 匯入 PaddleOCR 主要類別
# 1. 初始化 OCR 引擎
# 第一次執行時,PaddleOCR 會自動下載並快取預訓練模型 (預設存於使用者目錄下的 .paddleocr 資料夾)
# 參數說明:
# - lang="en": 指定識別語言為英文。若要識別中文或中英混合,請使用 "ch"。
# - use_angle_cls=True: 啟用「方向分類器 (Angle Classifier)」。
# 這對於文字可能被旋轉 (如 90度、倒置) 的圖片非常重要,它會自動矯正方向後再進行文字識別。
ocr = PaddleOCR(
lang="en",
use_angle_cls=True
)
# 2. 執行 OCR 識別
# 參數說明:
# - 第一個參數: 圖片路徑。建議在 Windows 下使用 r"..." (原始字串) 以避免路徑中的反斜線 '\' 被當作跳脫字元。
# - cls=True: 告訴函式這次識別要使用方向分類器 (需配合初始化時的 use_angle_cls=True)。
# 回傳值 result 是一個列表的列表 (List of Lists)。
result = ocr.ocr(r"D:\Temp\my_screenshot.png", cls=True)
# 3. 解析結果
# result[0] 代表第一張圖片的識別結果列表 (因為一次可以傳多張圖,但這裡只傳一張)。
# 迴圈會遍歷這張圖中偵測到的每一個文字區塊。
for line in result[0]:
# line 的資料結構範例:
# [
# [[286, 38], [637, 38], [637, 72], [286, 72]], <-- line[0]: 文字框的四個角落座標 (Bounding Box)
# ('Hello World', 0.996) <-- line[1]: 識別結果 Tuple (文字內容, 信心分數)
# ]
# 我們通常只關心文字和分數,所以取 line[1]
text, score = line[1]
# 格式化輸出:顯示文字內容,並將信心分數格式化為小數點後兩位
print(f"{text} ({score:.2f})")第一次執行會下載模型,正常。
9️⃣ 常見錯誤與判斷方式
❌ ABI Error(最常見)
module compiled against ABI version 0x1000009✅ 解法:NumPy 降級到 1.26.4
⚠️ angle classifier warning
WARNING: angle classifier is not initialized✅ 圖片全正 → 可忽略
✅ 有旋轉 → 加 use_angle_cls=True
🔟 結論與最佳實務
✅ 核心原則
PaddleOCR = NumPy 1.x 世界
pip 住在 NumPy 2.x 世界
👉 一定要「人為鎖版本」
✅ 建議存一個 requirements.txt
numpy==1.26.4
paddlepaddle==2.6.2
paddleocr==2.7.3
opencv-python-headless==4.6.0.66✅ 最後一句話
這不是你不會裝,是 Python 生態正在經歷 ABI 轉換期。
推薦hahow線上學習python: https://igrape.net/30afN
如果有內容直接遺漏,完全沒做OCR:
def ocr_image_bytes_by_PaddleOCR(image_bytes: bytes, tag: bool = True) -> str:
"""
使用 PaddleOCR 進行圖片文字識別 (OCR)
tag: 是否在回傳字串外層加上 <desc_by_AI model=PaddleOCR> 標籤
預設值: True, 識別出來的文字會加上標籤(插入docx中,方便後續辨識來源)
"""
try:
# 初始化 PaddleOCR,設定語言為中英文
# 說明: PaddleOCR 的 'ch' 模型預設支援「中英文數字混排」。
# 因此,面對「可能是中文、可能是英文、或是中英混雜」的情境,設為 'ch' 即可同時涵蓋,無需切換。
ocr = PaddleOCR(use_angle_cls=True, lang='ch', show_log=False,
# 如果是正式文件,不需要翻轉圖片的話
# use_angle_cls=False
#避免「文字被倒過來讀了」 (180度翻轉)。
#update 倒過來看真的很像 anepdn (u->n, p->d, d->p...)。
# --- 关键调整区域 ---
det_db_thresh=0.1, # 【核心】降低二值化阈值,对暗色文字更敏感
det_db_box_thresh=0.3, # 【核心】降低框置信度,保留信心不足的检测框
det_db_unclip_ratio=2.0, # 扩大检测框,防止长字符串首尾被切
# --- 识别相关 (可选) ---
use_space_char=True # 代码中空格很重要,确保保留
)
# 執行 OCR
result = ocr.ocr(image_bytes, cls=True)
# 提取識別結果
texts = []
# 改正: PaddleOCR 回傳為列表的列表 [ [line1, line2...], ... ]。
# 針對單張圖片應取 result[0]。且若無文字被識別,result[0] 可能為 None,需做檢查。
# 安全性檢查 (Safety Check):
# 1. 檢查 result 是否存在且不為空列表 (避免 IndexError)
# 2. 檢查 result[0] 是否存在 (避免 TypeError: 'NoneType' object...)
# 利用 Python 的短路特性 (Short-circuit),若前者為 False 則不會執行後者,防止崩潰。
if result and result[0]:
for line in result[0]:
# line 結構詳解 (Example):
# [
# [[305, 204], [483, 204], [483, 222], [305, 222]], # 0. 座標框 (Bounding Box): 四個角落座標
# ("Hello World", 0.966) # 1. (文字內容, 置信度): Tuple
# ]
texts.append(line[1][0])
# 合併所有識別出的文字並回傳
# 使用 '\n' 換行符號連接每一行文字,保留原始圖片的直行結構。
# 特別是針對程式碼或 JSON 格式,換行能避免所有內容擠成一行,便於閱讀與後續解析。
final_text = '\n'.join(texts)
if tag:
return f"<desc_by_AI model=PaddleOCR>{final_text}</desc_by_AI>\n"
#寫入 Word 時 (tag=True):保留標籤,方便人類閱讀或後續腳本辨識來源。
else:
return final_text
# 給 AI 當作參考 Prompt 時 (tag=False):僅傳遞純文字內容,
# 避免 AI 被 XML 標籤混淆,或是減少 Prompt Token 的消耗
except Exception as e:
print(f"[PaddleOCR Error] {e}")
return f"[PaddleOCR_FAILED: {str(e)}]",Skip Record If")
")

 函數; from docx.oxml.ns import qn #qualified name ; qn(‘w:p’) ; qn(‘w:tbl’)")
; dict(key)提取dict內的元素; importlib.reload(); np.zeros(); np.array()")
 計算c字元在s字串中出現了幾次,字串跟list都可以.count()")
 教學:sys._getframe(1) vs inspect.currentframe().f_back # inspect.currentframe() 先拿到自己,再 .f_back 到 caller;等價於 sys._getframe(1)")
 ) ) ; listbox = tk.Listbox (root, listvariable = menu)")
,插入>快速組件>功能變數>StyleRef")


近期留言