chardet 的英文字縮寫是
“charset(字符集) detection”,
意思是編碼偵測。
chardet 是 Python 的一個套件,
可以自動判斷文字檔案的編碼方式,
通常用在處理 CSV、JSON、XML 等純文字檔案時,
可以先使用 chardet 套件來判斷檔案的編碼,
再使用正確的編碼方式進行讀取,
避免因編碼不同而導致的資料解析錯誤。
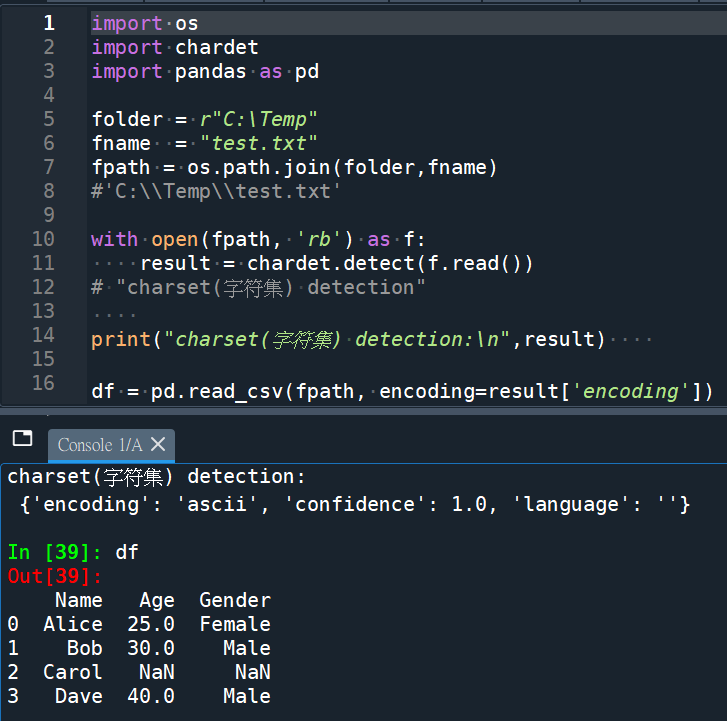
import os
import chardet
import pandas as pd
folder = r"C:\Temp"
fname = "test.txt"
fpath = os.path.join(folder,fname)
#'C:\\Temp\\test.txt'
with open(fpath, 'rb') as f:
result = chardet.detect(f.read())
# "charset(字符集) detection"
“””注意要使用rb模式開檔,
不然會出現TypeError
File C:\ProgramData\Anaconda\lib\site-packages\chardet\__init__.py:36 in detect
raise TypeError(‘Expected object of type bytes or bytearray, got: ‘
TypeError: Expected object of type bytes or bytearray, got: <class ‘str’>
“””
print("charset(字符集) detection:\n",result)
df = pd.read_csv(fpath, encoding=result['encoding'])
推薦hahow線上學習python: https://igrape.net/30afN
 方法說明,計算唯一值的數量,與 len( pandas.Series.unique() ) 同效果")
與tuple(只能用index拜訪元素)有何差異?namedtuple vs dict")
![Python struct.pack() 將整數轉換為bytes ; while list: str1=list[0] ; 中間內容; list=[1:] #切片 ,遍歷list中的每一個元素,跟for i in list 類似 ; timeit() #計時](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/10/20221012095050_42.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python struct.pack() 將整數轉換為bytes ; while list: str1=list[0] ; 中間內容; list=[1:] #切片 ,遍歷list中的每一個元素,跟for i in list 類似 ; timeit() #計時")
如何一次讀出所有keys, values, items? dic.keys() ; set(dic) 無序; dic.values() ; dic.items()")



 增加新的一欄? model = tensorflow.keras.models.Sequential() #均一化資料")
![Python: 如何判斷字符串內容是否為數字(整數或浮點數)? isinstance( eval( entry.get() ), (float, int) ) ; str.isdigit() #不包括小數點和負號 ; try~ except ValueError~ ; 正則表示法 regular expression ; pattern = ‘^[-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?$’](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230512152430_3.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何判斷字符串內容是否為數字(整數或浮點數)? isinstance( eval( entry.get() ), (float, int) ) ; str.isdigit() #不包括小數點和負號 ; try~ except ValueError~ ; 正則表示法 regular expression ; pattern = ‘^[-+]?[0-9]*\.?[0-9]+([eE][-+]?[0-9]+)?$’")

近期留言