from sklearn.model_selection import train_test_split
xtrain,xtest,ytrain,ytest =\
train_test_split(x,y,test_size=0.3,
random_state=42,shuffle=True)

樣品分割:

參考解答:

import pandas as pd
import sys
fpath = r”C:\Python\P107\BostonHousing.csv”
dataset = pd.read_csv(fpath)
#.shape = (506, 14)
headerList = dataset.columns.tolist()
cols = dataset.columns.size
# dataset.columns.size = 14
x = dataset.drop(headerList[-1],axis=1).values
y = dataset[headerList[-1]].values
“””
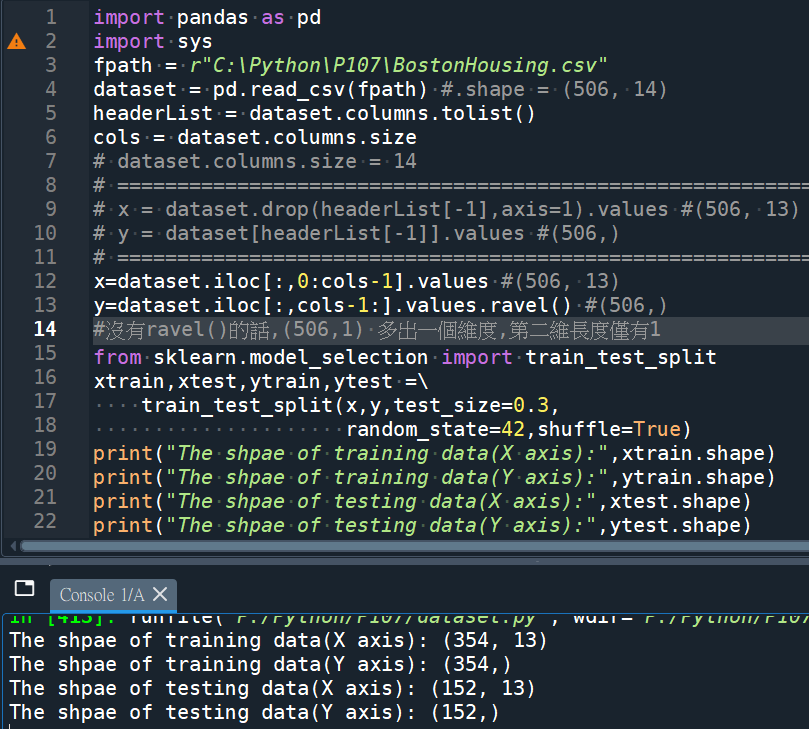
#x=dataset.iloc[:,0:cols-1].values
#y=dataset.iloc[:,cols-1:].values
#用iloc切片的y 資料非常像,
#但變成2D,第二維長度僅有1
#y=dataset.iloc[:,cols-1:].values.ravel()
#用ravel() 把2D降維成1D
y剛好在最後一欄比較好切片
若沒在最後一欄,
原本的drop比較好用
“””
from sklearn.model_selection import train_test_split
xtrain,xtest,ytrain,ytest =\
train_test_split(x,y,test_size=0.3,
random_state=42,shuffle=True)
print(“The shpae of training data(X axis):”,xtrain.shape)
print(“The shpae of training data(Y axis):”,ytrain.shape)
print(“The shpae of testing data(X axis):”,xtest.shape)
print(“The shpae of testing data(Y axis):”,ytest.shape)
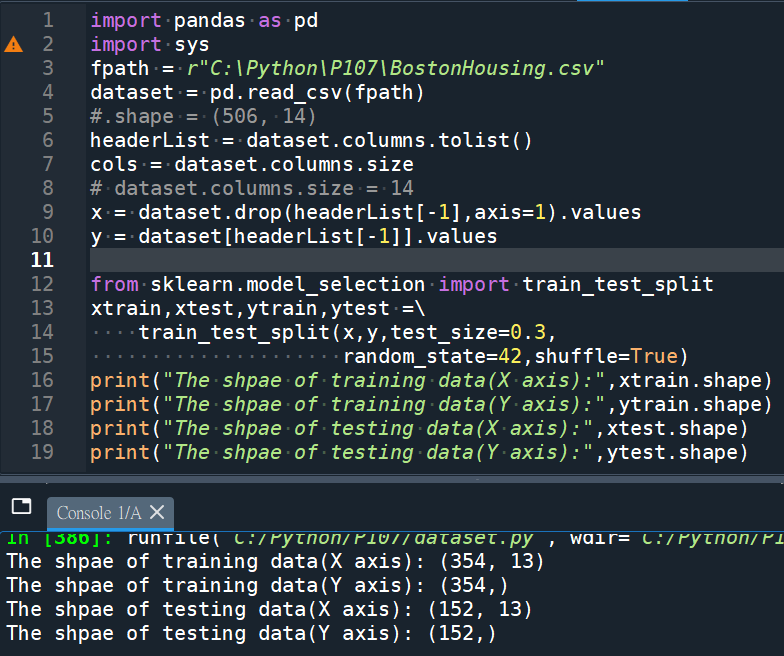
506*0.3 = 152 (test_size=0.3)
506-152 = 354
改用iloc做切片
.ravel() 將2D降維成1D
實測random_state跟shuffle參數:
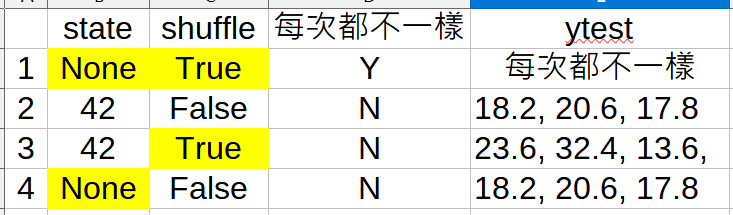
若真的需要都次取的都不一樣
random_state = None
shuffle = True
其他組合每次都會
取出一樣的samples
每次都一樣,
會比較容易debug
或判斷模型的優劣
random_state設了一樣的種子
shuffle = True也無效
每次都會取出一樣的資料
第四個組合
random_state = None
shuffle = False
沒種子,沒洗牌
為什麼每次都一樣?
from官網:

在 train_test_split 函數中,random_state 和 shuffle 參數看似相似但實際功能不同。
shuffle 參數
shuffle 是一個布爾值參數,控制是否要在分割前對數據進行隨機打亂:
- 類型:True/False
- 默認值:True
- 作用:決定是否打亂原始數據順序
- 何時設為 False:處理時間序列數據時,希望保持數據的時間順序
random_state 參數
random_state 控制如何進行隨機打亂:
- 類型:整數、None 或 RandomState 實例
- 默認值:None
- 作用:設定隨機種子,控制數據的打亂方式
- 意義:確保實驗可重複性和結果穩定性
兩者關係
-
當 shuffle=True 時,random_state 發揮作用:
- random_state=42(或任何固定值):每次運行結果相同
- random_state=None:每次運行結果不同
-
當 shuffle=False 時,random_state 不起作用,因為不需要打亂數據
實例對比
在需要結果可重複的情況下,應固定 random_state 的值。
推薦hahow線上學習python: https://igrape.net/30afN
波士頓地區房價:



boston (整齊版):
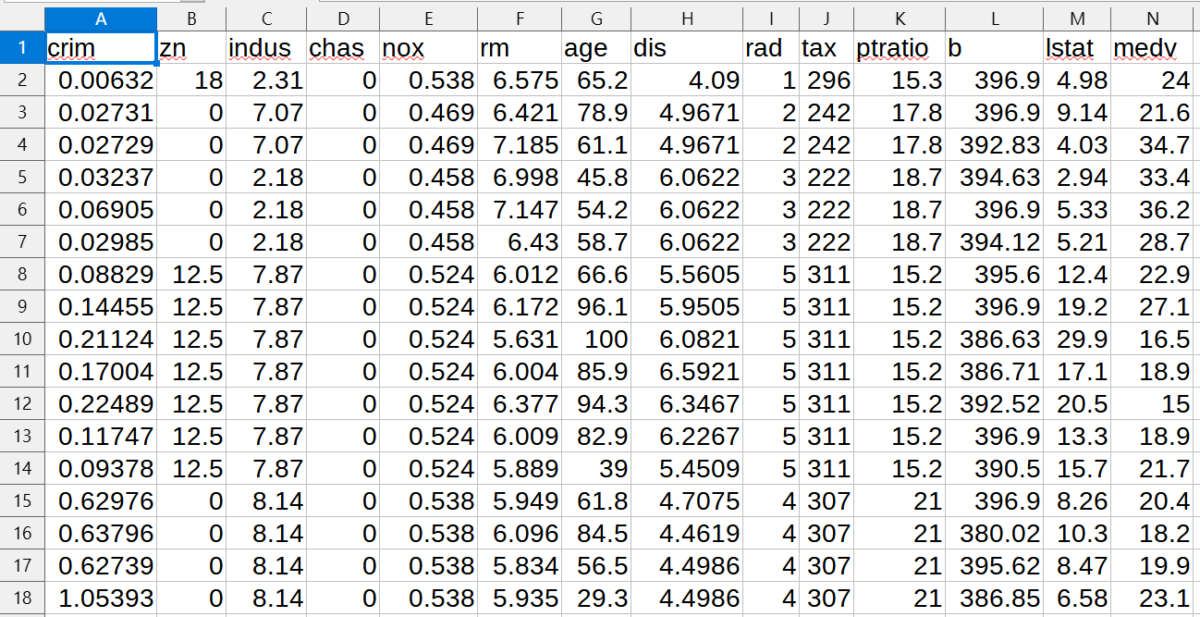
boston(排版較亂): http://lib.stat.cmu.edu/datasets/boston
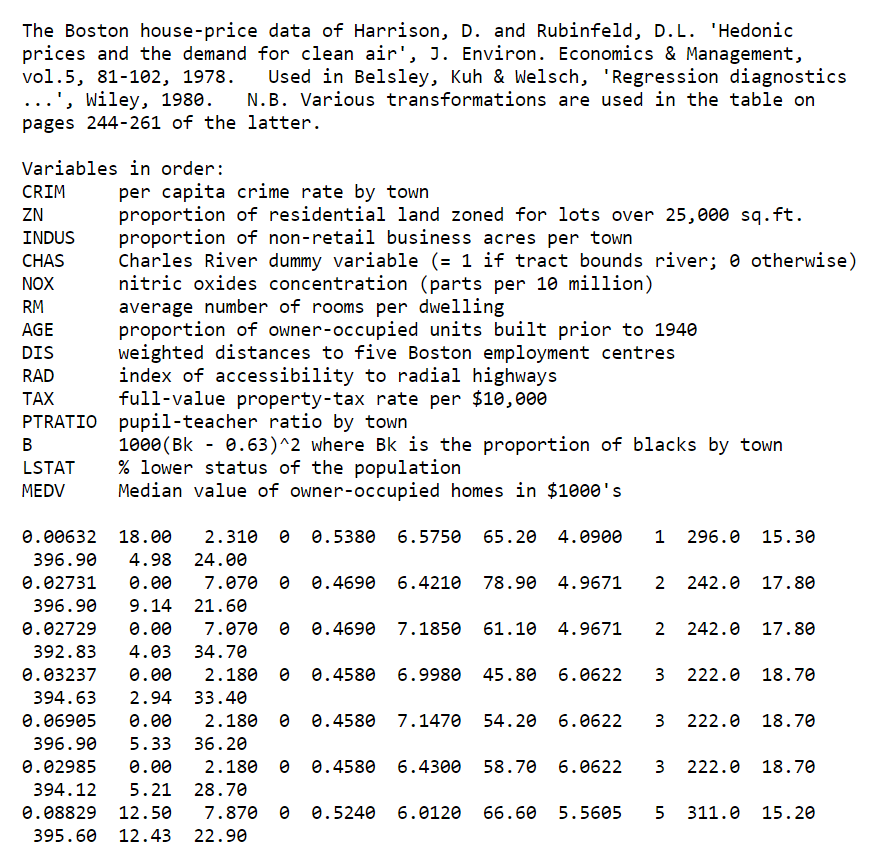
要如以下才能拼接回資料
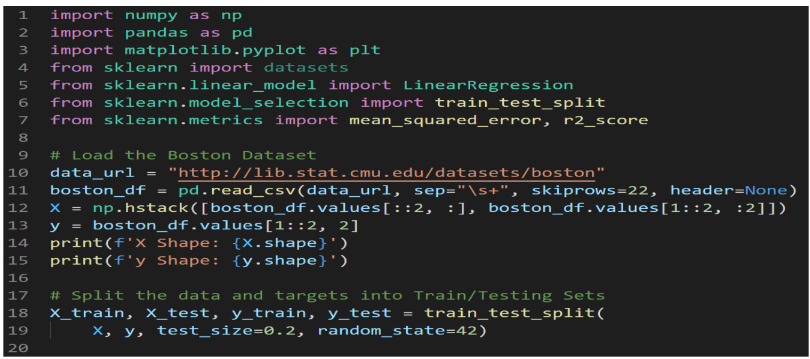
import pandas as pd
import numpy as np
url = r”http://lib.stat.cmu.edu/datasets/boston”
dfBoston = pd.read_csv(url,sep= “\s+” ,skiprows=22,header=None)
#正則表示法, 一個以上的空白或Tab
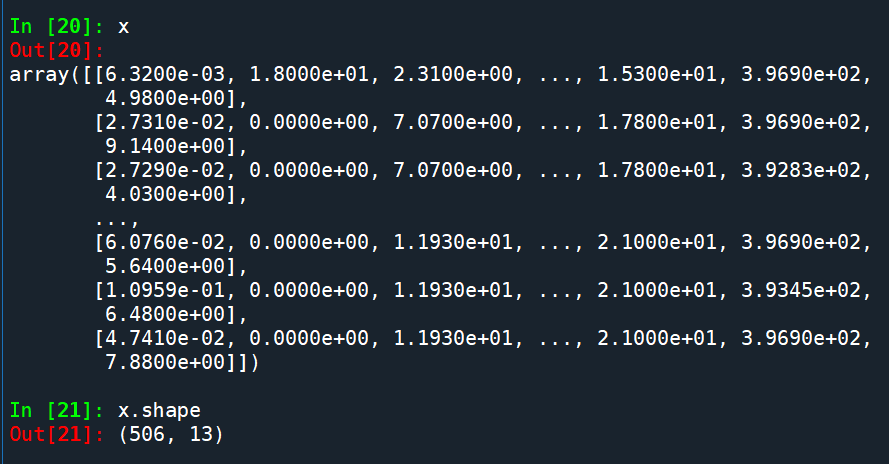
x=np.hstack( [ dfBoston.values[::2,:],dfBoston.values[1::2,:2] ] )
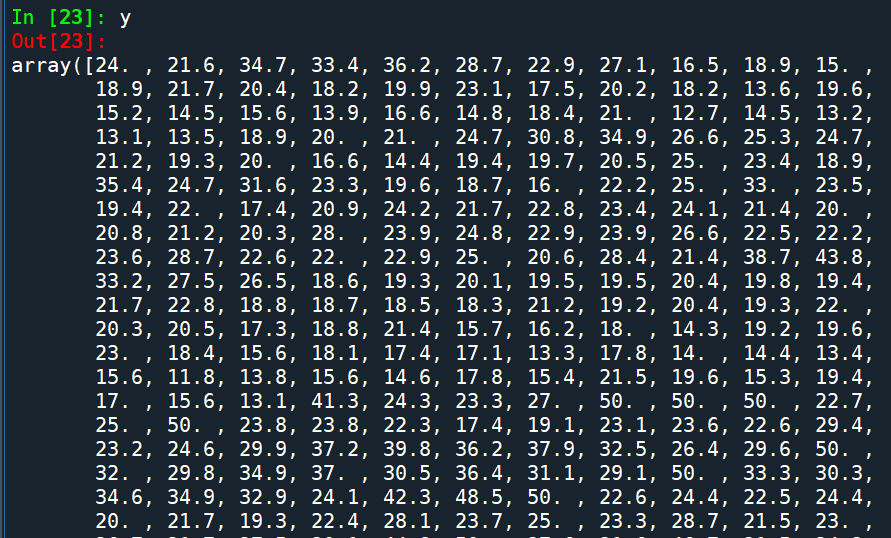
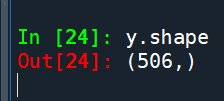
y=dfBoston.values[1::2,2]
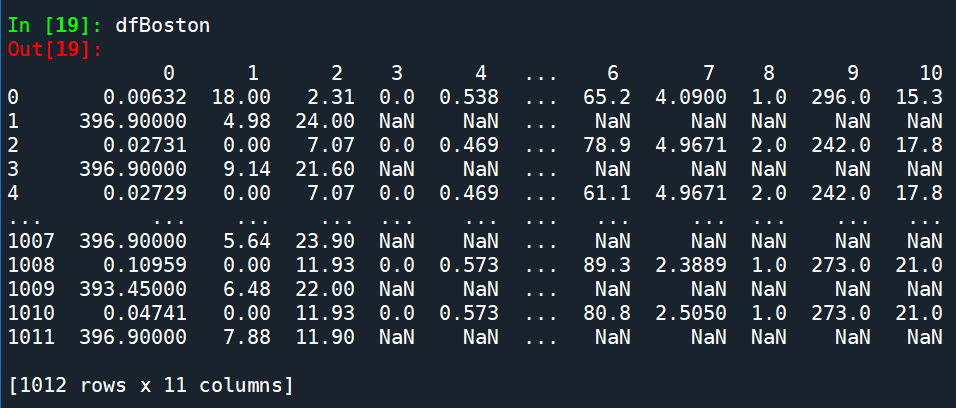
x:
部分y:
y.shape
推薦hahow線上學習python: https://igrape.net/30afN
 ; root = etree.fromstring(xml_str.encode(“utf-8″), parser=parser) #(根節點); print(etree.tostring(root, encoding=”unicode”, pretty_print=True)) #encoding=”unicode”輸出str ; “utf-8″輸出bytes,漂亮顯示")
/100: .0f})”) ; lambda匿名函数 ; 前綴 f “{變數or運算式: .0f}” 格式化字串")
,函數自己呼叫自己,遞迴(Recursive) , dict的value是dict ,巢狀dict,可使用tuple當key,但不可使用list當key")
 or(|) xor(^) not ; assert 預期為真的條件式, “錯誤訊息” ; 條件式為真的話,繼續往下跑,否則AssertionError: “錯誤訊息”")
,計算新光人壽美添109 IRR,免費下載IRR計算機")

 或 ary1 @ ary2 或 numpy.dot (ary1, ary2)")
![使用 Python 檢驗字符串格式:掌握正則表達式(Regular Expression)的起始^與終止$符號, pattern = r’^GATR[0-9]{4}$’](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2024/07/20240712093637_0.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "使用 Python 檢驗字符串格式:掌握正則表達式(Regular Expression)的起始^與終止$符號, pattern = r’^GATR[0-9]{4}$’")
位置? ax.legend( bbox_to_anchor = (1, 1), borderaxespad=0)")
![Python: matplotlib繪圖,如何限定座標軸範圍? plt.axis([xmin, xmax, ymin, ymax]) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/02/20230208101745_93-520x245.jpg)

近期留言