當你使用 dict 的 .get() 方法時,它會返回指定鍵的值。
如果該鍵不存在於字典中,則返回指定的預設值。
這在處理不存在的鍵時很有用,以避免引發 KeyError 錯誤。
以下是一個示範如何使用 .get() 方法的例子:
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 29 19:55:11 2023
@author: SavingKing
"""
# 定義一個字典
my_dict = {
'apple': 3,
'banana': 5,
'orange': 2
}
# 使用 .get() 方法取得鍵對應的值
apple_count = my_dict.get('apple', 0)
# 如果鍵存在,返回對應的值,否則返回預設值 0
pear_count = my_dict.get('pear', 0)
# 'pear' 鍵不存在,返回預設值 0
print("Apple count:", apple_count)
# 輸出: Apple count: 3
print("Pear count:", pear_count)
# 輸出: Pear count: 0輸出結果:
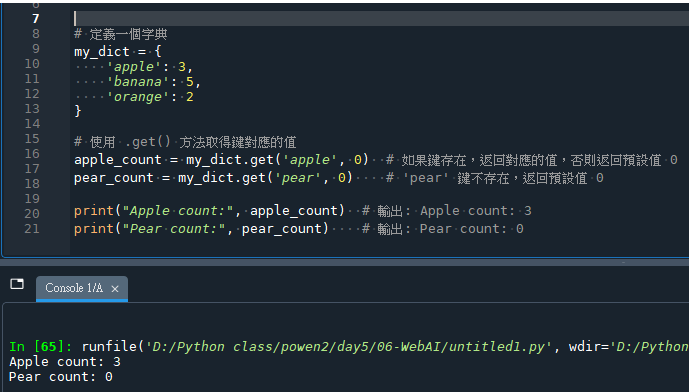
在這個例子中,當我們使用 .get() 方法來查找 ‘apple’ 鍵時,
它返回了該鍵對應的值 3。同樣地,當我們查找 ‘pear’ 鍵時,
由於該鍵不存在於字典中,.get() 方法返回了我們指定的預設值 0。
推薦hahow線上學習python: https://igrape.net/30afN


 增加新的一欄? model = tensorflow.keras.models.Sequential() #均一化資料")

 -> list ,回傳該路徑中有那些檔案,目錄; fpath = os.path.join(folder, “*.csv” ) ; glob.glob(fpath) #通配符匹配(globbing),抓取目錄下的指定檔案名稱")
 駝峰切詞與特例保護教學; (?i: … ):不分大小寫的非捕獲群組")
,計算香港保單富衛人壽(FWD)盈聚優裕(UFE1)IRR,免費下載IRR計算機")



![Python如何串接OpenAI /Claude /Gemini API自動將大量維修紀錄JSON轉自然語言描述(並避免中斷資料遺失)response = client.chat.completions.create() ; reply = response.choices[0].message.content - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2025/07/20250716084059_0_c5b368-520x245.png)

近期留言