在處理檔案命名、資料清洗或字串拼接時,我們常會遇到一個棘手問題:「有些欄位可能是空的,有些可能是 None,怎麼把它們乾淨地接在一起?」
如果寫一堆 if x is not None:,程式碼會變得又臭又長。今天我們透過一個真實的自動化文件命名案例,來學習 Python 中最強大的過濾神器:filter()。
1. 真實場景:為技術文件自動產生檔名
假設我們正在寫一個腳本,將技術規格書的章節匯出成獨立的 Word 檔。我們希望檔名包含「章節編號」和「完整標題路徑」,例如:2.2--iecfbt-spec__硬件软件需求__opentest-server需求.docx
我們的程式邏輯如下:
# 模擬從文件解析出來的兩個變數
path_part = '2.2' # 章節編號前綴
title_part = 'iecfbt-spec__硬件软件需求__opentest-server需求' # 標題鏈
# 我們希望用 '--' 將它們連起來
# 但如果 path_part 是空字串呢?如果 title_part 是 None 呢?傳統寫法(不推薦)
如果不使用 filter,為了避免出現 --title 或 prefix-- 這種醜陋的檔名,你可能得這樣寫:
parts = []
if path_part:
parts.append(path_part)
if title_part:
parts.append(title_part)
fname_base = '--'.join(parts)這雖然能用,但太囉嗦了。
2. 優雅解法:filter(None, iterable)
Python 的 filter 函數配合 None 參數,是處理這種「空值過濾」的絕佳語法糖。
# 一行搞定
fname_base = '--'.join(filter(None, [path_part, title_part]))這是什麼黑魔法?
filter(function, iterable) 的運作原理是:將列表中的每個元素丟進函數檢查,只保留回傳 True 的元素。
當你傳入 None 作為第一個參數時,Python 會執行預設行為:過濾掉所有「真值測試 (Truth Value Testing)」為 False 的元素。
在 Python 中,以下都會被視為 False 並被踢除:
None- 空字串
"" - 空列表
[] - 數字
0
實戰演練:各種情境測試
讓我們看看 filter 如何完美處理你的檔名生成邏輯:
情境 A:標準狀況(兩者都有值)
path_part = '2.2'
title_part = 'iecfbt-spec__硬件软件需求__opentest-server需求'
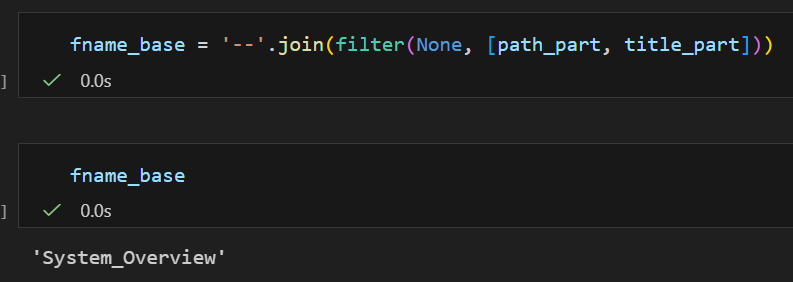
# 一行搞定
fname_base = '--'.join(filter(None, [path_part, title_part]))
# filter(None, [...]) -> 保留 ['2.2', 'iecfbt-spec...']
# join 結果:
# "2.2--iecfbt-spec__硬件软件需求__opentest-server需求"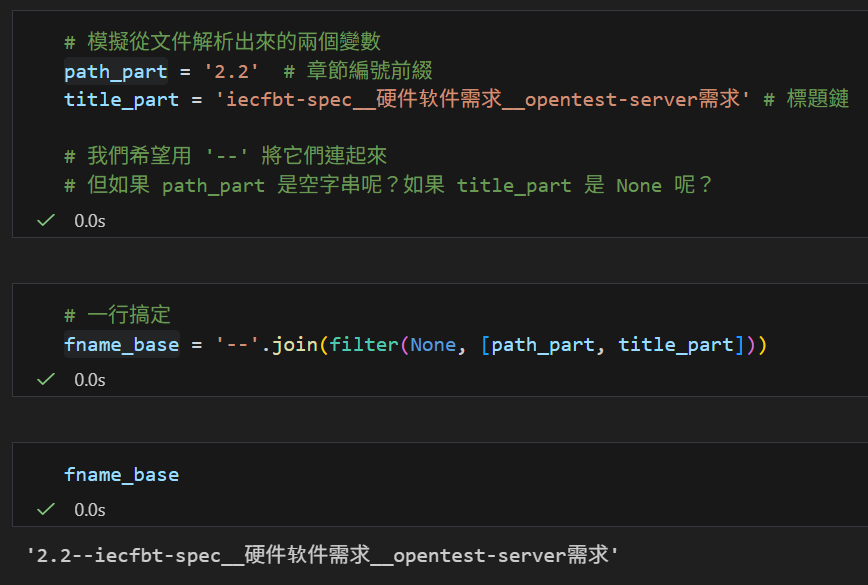
✅ 完美連接。
情境 B:沒有章節編號(path_part 為空)
有些文件首頁沒有編號,path_part 可能是空字串。
# %%
path_part = ''
title_part = 'System_Overview'
# filter(None, ['', 'System_Overview']) -> 空字串被踢掉,只剩 ['System_Overview']
# join 結果:
# "System_Overview"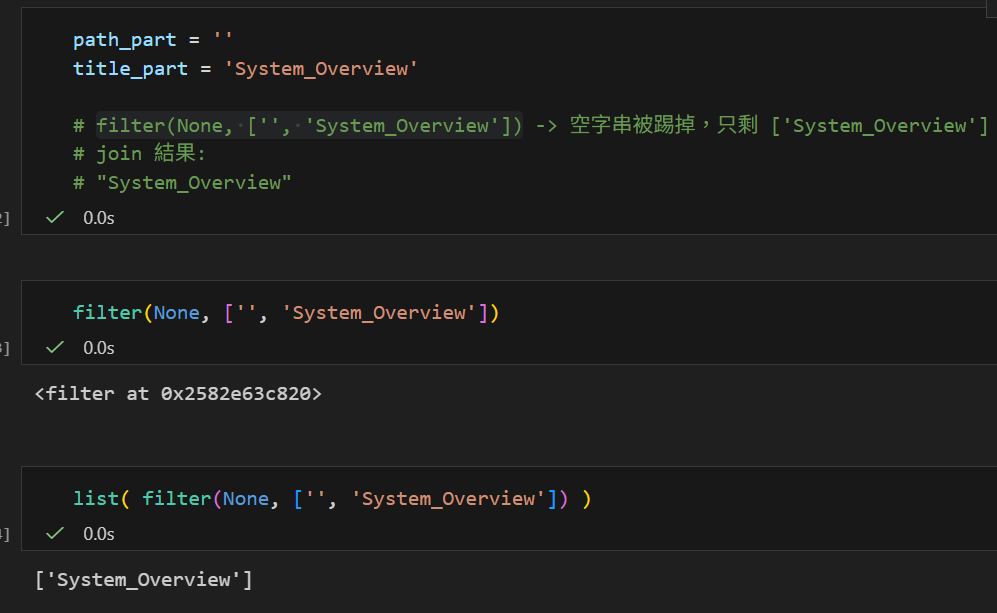
✅ 沒有多餘的 -- 在前面。
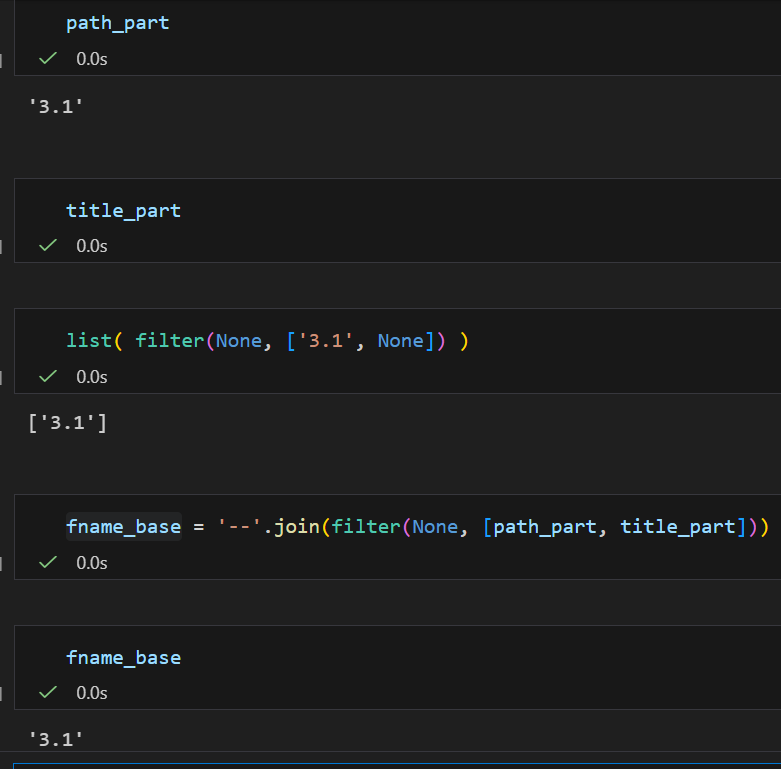
情境 C:程式出錯導致標題遺失(title_part 為 None)
path_part = '3.1'
title_part = None
# filter(None, ['3.1', None]) -> None 被踢掉,只剩 ['3.1']
# join 結果:
# "3.1"✅ 程式不會崩潰,也不會出現 3.1--。
3. 進階應用:在 List Comprehension 中使用
有一段處理 chain_titles 的邏輯:
chain_titles = []
for cp in chain_parts:
cleaned = ... # 一連串清理動作
# 這裡用了一個 or 技巧,如果清理完是空的,就給個預設值
chain_titles.append(_sanitize_filename(cleaned) or f't_{idx_h:03d}')如果我們想要更激進一點,直接丟棄那些清理後變為空字串的標題,而不是給預設值,我們可以結合 filter:
raw_titles = ["1. Introduction", " ", "2. Hardware"]
# 1. 先清理
cleaned_titles = [re.sub(r"^\d+\.\s*", "", t).strip() for t in raw_titles]
# 此時 cleaned_titles 可能是 ['Introduction', '', 'Hardware']
# 2. 再過濾
final_titles = list(filter(None, cleaned_titles))
# 結果: ['Introduction', 'Hardware']總結
在 Python 中,只要看到**「我需要把幾個字串接起來,但有些可能是空的」**這種需求,請立刻想到:
separator.join(filter(None, [item1, item2, item3]))這不僅讓你的 fname_base 生成邏輯更簡潔,也讓程式碼更具備 Pythonic(Python 風格)的優雅與強健性。
推薦hahow線上學習python: https://igrape.net/30afN
filter 比較像是一個「守門員」或「篩子」,而不是一個「無限迴圈的清潔工」。
為什麼 filter 通常更有效率。
1. filter 是什麼?(守門員機制)
filter 只會掃描列表一次。它不會回頭,也不會重複檢查。
想像有一條輸送帶(你的 List),上面有很多箱子。filter 就像站在輸送帶中間的守門員。
- 機制:箱子一個接一個過來,守門員看一眼。
- 如果是空的(
None,"",[]),守門員把它踢掉。 - 如果有東西,守門員讓它通過。
- 如果是空的(
- 次數:每個箱子只被檢查一次。
- 結果:產生一個新的、乾淨的隊伍。
Python 程式碼範例:
raw_list = ["A", "", None, "B", [], "C"]
# filter(None, list) 是 Python 的捷徑,專門過濾掉「判定為 False」的東西
clean_list = list(filter(None, raw_list))
print(clean_list)
# 結果: ['A', 'B', 'C']已經理解了 filter 的「守門員」概念,那麼列表推導式其實就是把「守門員」和「輸送帶」寫在同一行的語法糖。它通常比 filter 更直觀,也更符合 Python 的哲學(Readability counts)。
讓我們來拆解這個優雅的語法:
1. 語法拆解
clean_list = [x for x in raw_list if x]這行程式碼可以拆解成三個部分來看,請試著用口語唸出來:
for x in raw_list(輸送帶):- 把
raw_list裡面的東西,一個一個拿出來,暫時叫做x。
- 把
if x(守門員/過濾條件):- 只有當
x是「真」(True) 的時候,才允許通過。 - 註:在 Python 裡,空字串
""、空列表[]、數字0、None都會被視為「假」(False)。
- 只有當
x(最前面的 x,結果):- 通過守門員的
x,要變成什麼樣子?這裡我們只是原封不動地把它放進新列表。
- 通過守門員的
翻譯成中文就是:
「請給我一個新列表,裡面的元素是
x,這些x來自raw_list,而且前提是x必須有內容。」
2. 進階:它比 filter 強在哪裡?
filter 只能決定「要」或「不要」,但列表推導式可以同時做 「過濾」 和 「加工」。
情境 A:單純過濾 (和 filter 一樣)
假設我們要把空值去掉。
- filter 寫法:
data = ["Apple", "", "Banana", None]
result = list(filter(None, data))
# ['Apple', 'Banana']列表推導式:
result = [x for x in data if x]
# ['Apple', 'Banana']- (平手,都很簡潔)
情境 B:過濾 + 加工 (列表推導式勝出)
假設我們要把空值去掉,而且把留下來的字串全部轉成小寫。
- filter 寫法 (需要配合
map,變得很複雜):
data = ["Apple", "", "Banana", None]
# 先過濾,再轉小寫,讀起來很累
result = list(map(lambda x: x.lower(), filter(None, data)))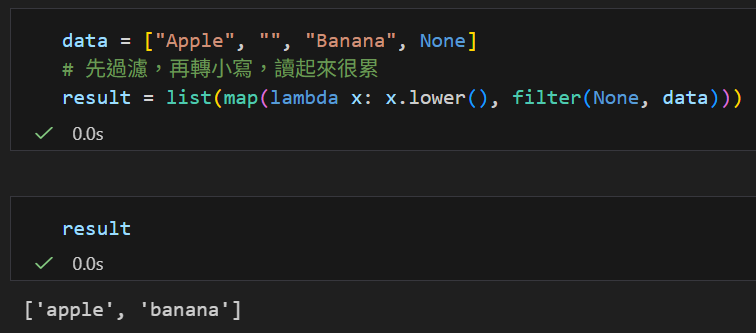
列表推導式 (非常直覺):
# 注意最前面的 x 變成了 x.lower()
result = [x.lower() for x in data if x]
# ['apple', 'banana']3. 陷阱提示:if x 到底過濾了什麼?
你剛才提到 [[], "", None],使用 if x 會把這些全部殺掉。這通常是好事,但有時候會「殺錯人」。
特別注意數字 0 和 False!
如果你的資料裡包含數字 0,用 if x 會不小心把它當成垃圾丟掉。
# %%
scores = [100, 90, 0, None, 50] # 0 分也是分數,不能丟掉!
# 錯誤寫法:0 被當成 False 丟掉了
wrong = [x for x in scores if x]
# 結果: [100, 90, 50] <-- 0 不見了!
# 正確寫法:明確指定「只要不是 None」
correct = [x for x in scores if x is not None]
# 結果: [100, 90, 0, 50] <-- 0 保留了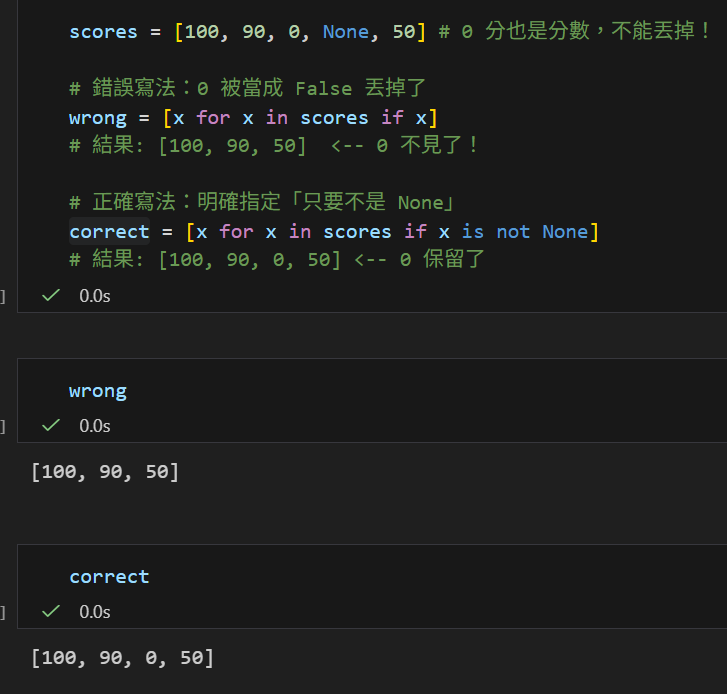
總結
filter:適合邏輯很單純,或者你已經有一個現成的函數可以當過濾器時使用。[x for x in list if x]:這是 Python 最推薦的寫法。它可讀性高、速度快,而且可以同時進行資料修改(例如轉小寫)。
以後看到這種寫法,就在腦中把它想成:[ (3.結果) for (1.來源) if (2.條件) ]
推薦hahow線上學習python: https://igrape.net/30afN
, dtype=float) ; print(data.shape); min0 = numpy.min(a,axis=0) ; min1 = numpy.min(a,axis=1) #2次沿軸1 ; numpy.average() ;array的軸向")
 判斷list中是否有True ; all(list) 判斷list中是否全為True ; any(pandas.Series)相當於any(pandas.Series.values) ; i in pandas.Series 卻相當於於i in pandas.Series.index")
 排序,參數key = lambda 匿名函式 ;物件導向 def __repr__(self): #原形畢露; def __str__(self): #給人閱讀")
: 如何使用命名捕獲組將字串整理為dict?match.groupdict() ; NAME: sensor-count STATUS: PASSED VALUE: 129 LL: 129 UL:")
 ; ax.xaxis.set_minor_locator(minor_locator)")


 ; plt.subplots_adjust( hspace=1 ) 調整子圖間的間距")
與numpy.poly1d()做多項式曲線擬和; matplotlib 如何變更legend圖例字型大小? plt.rc(“legend”, fontsize=16) ; ax.legend(loc = “best”, fontsize=16, handlelength=0.5, frameon = False)")

近期留言