import pandas as pd
# 創建成績表
scores = pd.DataFrame({
‘student_id’: [‘001’, ‘002’, ‘003’, ‘004’],
‘score’: [85, 76, 92, 80]
})
# 創建基本資料表
basic_info = pd.DataFrame({
‘student_id’: [‘001’, ‘002’, ‘003’, ‘004’],
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’, ‘David’],
‘gender’: [‘F’, ‘M’, ‘M’, ‘M’]
})
# 以 student_id 欄位為基準合併
merged_df = pd.merge(left=scores,
right=basic_info,
left_on=’student_id’,
right_on=’student_id’,
how=’inner’)
print(“scores:\n%r”%scores)
print(“\nbasic_info:\n%r”%basic_info)
print(“\nmerged_df:\n%r”%merged_df)
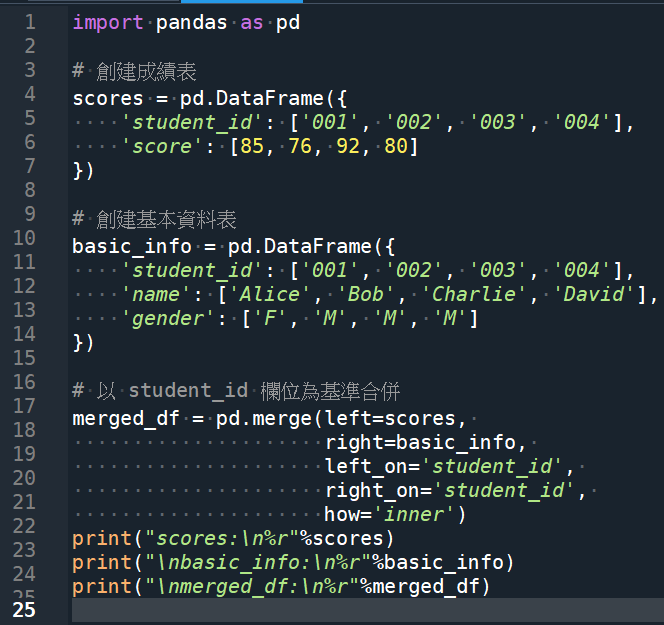
輸出結果:
這裡的 left_on 參數指的是左側 DataFrame 的
以 student_id 為基準的欄位名稱,
right_on 參數指的是右側 DataFrame 的
以 student_id 為基準的欄位名稱,
因為兩個 DataFrame 中的欄位名稱是一樣的,
所以也可以寫成:
merged_df = pd.merge(left=scores, right=basic_info, on=’student_id’, how=’inner’)
使用right_index=True
import pandas as pd
# 創建成績表
scores = pd.DataFrame({
‘student_id’: [‘001’, ‘002’, ‘003’, ‘004’],
‘score’: [85, 76, 92, 80]
})
# 創建基本資料表,並將 student_id 設定為索引
basic_info = pd.DataFrame({
‘name’: [‘Alice’, ‘Bob’, ‘Charlie’, ‘David’],
‘gender’: [‘F’, ‘M’, ‘M’, ‘M’]
}, index=[‘001’, ‘002’, ‘003’, ‘004’])
basic_info.index.name = ‘student_id’ #此行非必要
merged_df = pd.merge(left=scores,
right=basic_info,
left_on=’student_id’,
right_index=True,
how=’inner’)
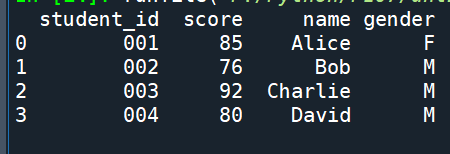
print(merged_df)
輸出結果:
推薦hahow線上學習python: https://igrape.net/30afN
pd.merge(
left,
right,
how=’inner’,
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=False,
suffixes=(‘_x’, ‘_y’),
copy=True,
indicator=False,
validate=None,
)
下面是各參數的說明:
- left: 要合併的左邊的 DataFrame。
- right: 要合併的右邊的 DataFrame。
- how: 合併的方式,可選值為 ‘left’, ‘right’, ‘outer’, ‘inner’,預設值為 ‘inner’。
- on: 用來合併的欄位名稱,必須存在於左右兩個 DataFrame 中。如果 left_index=True 或 right_index=True,則此參數無效。
- left_on: 用來合併的左邊的 DataFrame 的欄位名稱。如果 left_index=True,則此參數無效。
- right_on: 用來合併的右邊的 DataFrame 的欄位名稱。如果 right_index=True,則此參數無效。
- left_index: 是否以左邊的 DataFrame 的索引作為合併鍵。預設為 False。
- right_index: 是否以右邊的 DataFrame 的索引作為合併鍵。預設為 False。
- sort: 是否根據合併鍵排序。預設為 False。
- suffixes: 字符串元組,用於區分具有相同名稱的左邊和右邊 DataFrame 的重複列。預設為 (‘_x’, ‘_y’)。
- copy: 是否復製 DataFrame。如果設為 False,當左右兩個 DataFrame 共享記憶體時可能會改變原始 DataFrame。預設為 True。
- indicator: 將一個特殊的名為 _merge 的欄位添加到結果 DataFrame,顯示每行的合併方式。預設為 False。
- validate: 檢查合併的類型。可選值為 “one_to_one”、”one_to_many”、”many_to_one” 和 “many_to_many”。預設為 None,即不檢查。

 x%5!=0 (!= 不等於)")
反轉 .sort()排序 .remove(“指定元素”)移除 .pop(index)移除, 字串.replace(old,new) .lower()小寫 .upper()大寫 .title()首字大寫")


")

, dtype=float) ; print(data.shape); min0 = numpy.min(a,axis=0) ; min1 = numpy.min(a,axis=1) #2次沿軸1 ; numpy.average() ;array的軸向")
 ; os.makedirs() ; 有何差別?")



近期留言