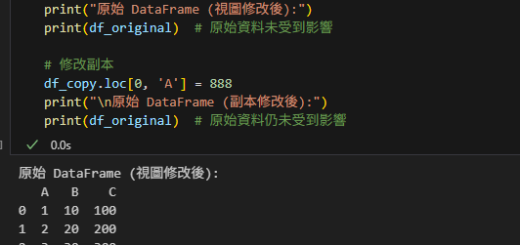
在下面的Python代碼示例中,我們將演示如何為一個數據列表中的每個字典添加一個共同的序列號字段。這種操作在數據處理中非常常見,尤其是當你需要為來自同一來源或具有相同屬性的數據集合添加標識信息時。
代碼解析:
1. 定義序列號和數據列表:
我們首先定義了一個序列號sn,它用於標識這批數據的來源或歸屬。
接著,我們創建了一個名為simple_data_list的列表,里面包含了兩個字典。每個字典代表一個傳感器的數據,包括傳感器的類型(type)、名稱(name)、讀數(reading)和單位(units)。
為數據列表中的每個字典添加序列號:
2. 使用列表推導式,我們遍歷simple_data_list中的每個字典,然後通過字典解包(**data)把字典中的鍵值對添加到一個新的字典中。
在這個新字典中,我們還添加了一個新的鍵值對,鍵是’SN’,值是變量sn的值。這樣,每個字典都會被附加上相同的序列號,從而將這些字典關聯到同一個序列號下。
3. 打印結果以驗證:
最後,我們打印出修改後的字典列表enriched_simple_data_list,以驗證每個字典中都成功添加了序列號。
code:
# 定义序列号和简化的数据列表
sn = 'SN1'
simple_data_list = [
{'type': 'thermal', 'name': 'sensorA', 'reading': '75.000', 'units': 'degrees C'},
{'type': 'pressure', 'name': 'sensorB', 'reading': '1.5', 'units': 'atm'}
]
# 为每个字典添加序列号,并创建一个新的包含序列号和原始数据的字典列表
enriched_simple_data_list = [{'SN': sn, **data} for data in simple_data_list]
# 打印结果以验证
print(enriched_simple_data_list)輸出結果:
![Python: 資料格式如 List[dict],如何快速將SN加入每一個dict中,以利Excel輸出?如何解包dict? **dict ; 將List[dict]的資料轉為pandas.DataFrame 長什麼樣子? - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2024/02/20240208093926_0.png)
推薦hahow線上學習python: https://igrape.net/30afN
 比較像實際行為; setdefault() vs defaultdict(list)")
 與 os.path.exists() 有何差別?")
)")
 搜尋元素位於list中的那一個index")
 as z: print(z.namelist()) ; z.infolist()")


 讀取csv檔案?若該檔案奇異列長度太短,如何用try:~except:~避免取直欄時出現IndexError: list index out of range?")
 ; spyder無法用滑鼠改變3D圖的視角該如何處理? %matplotlib qt")

近期留言