This method is most useful when you don’t know if your object is a Series or DataFrame, but you do know it has just a single column. In that case you can safely call squeeze to ensure you have a Series.

例如: 想要使用Series.str.split()
Series.str.contains()
只有Series才能做
但Series跟單欄的DataFrame
並不好分辨
就可以使用squeeze()
確認資料型態必為Series
(若Series只有一個資料,會壓縮成scalar)
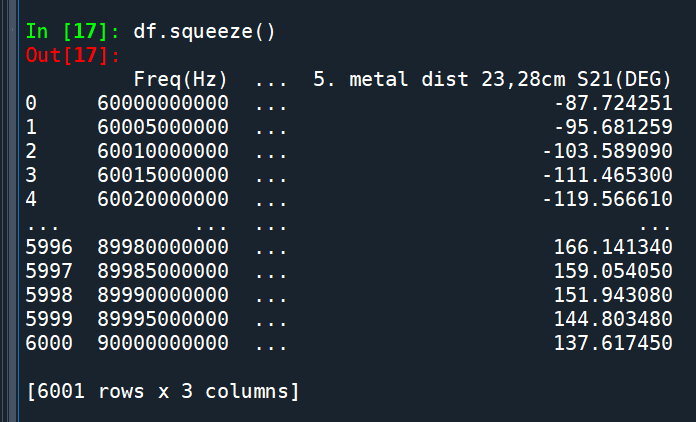
df [6001 rows x 3 columns]:
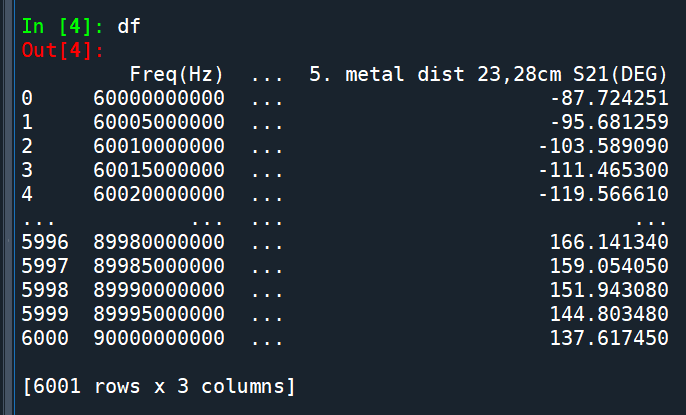
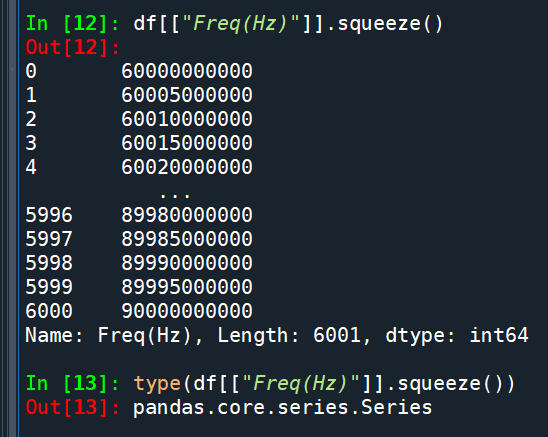
df[“Freq(Hz)”]
其實已經是Series:
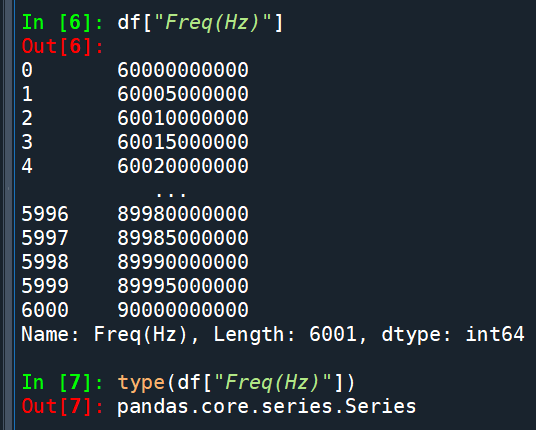
df[“Freq(Hz)”].squeeze()
對Series再壓縮一次
do nothing:
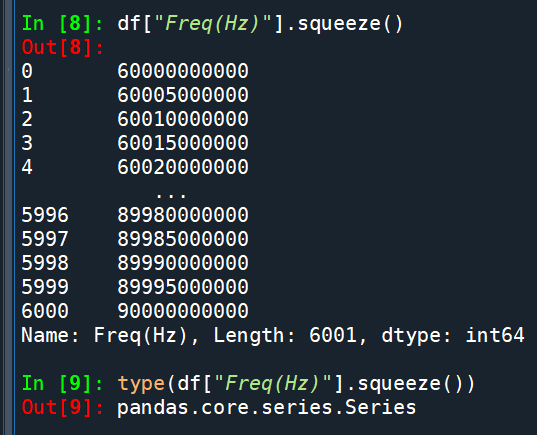
df[[“Freq(Hz)”]]
如果誤用[[ ]] (雙層方括弧)
(內層的[]是list的意思,
外層的[]則是定位的意思)
那會得到單欄的DataFrame:
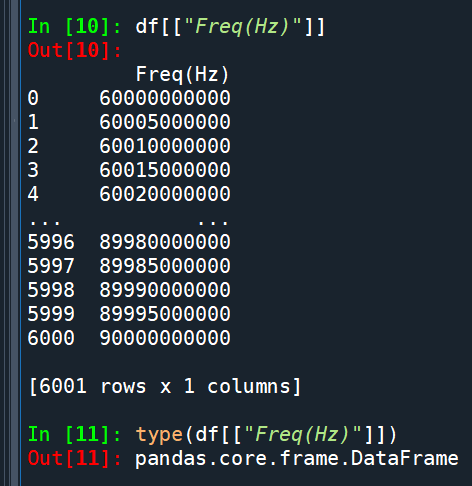
df[[“Freq(Hz)”]].squeeze()
會將單欄的DataFrame
壓縮成Series:
This method is most useful
when you don’t know if your object is a Series or DataFrame,
but you do know it has just a single column.
對於兩欄以上的DataFrame做壓縮
do nothing:
ser[ ser==60000000000 ]
(只有單一資料的Series):
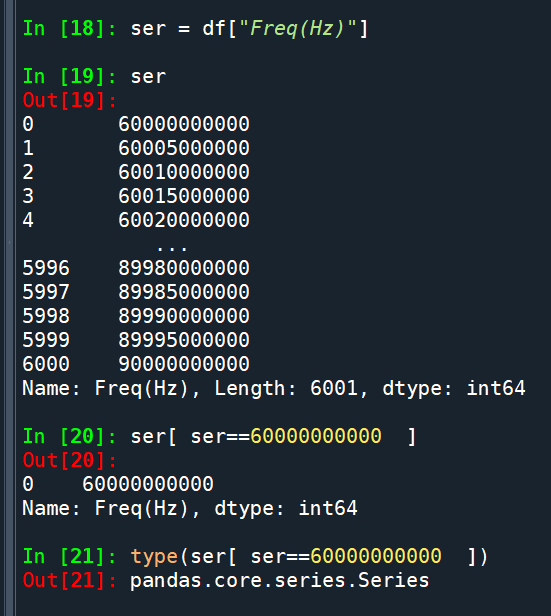
其實看60000000000
左邊還帶有index 0
也知道type是Series
但只有單一資料
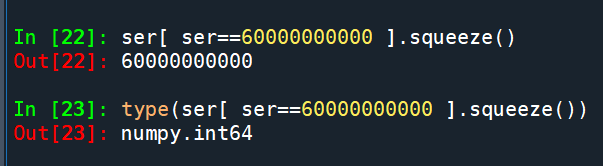
ser[ ser==60000000000 ].squeeze()
對只有單一資料的Series做壓縮
得到scalar:
推薦hahow線上學習python: https://igrape.net/30afN
df有兩欄,
第0欄為頻率,第1欄為Gain:
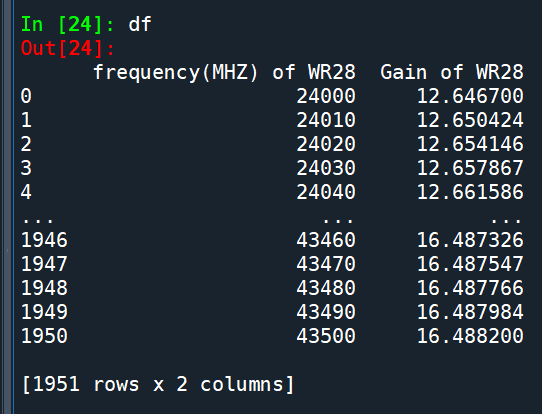
df_set_index = df.set_index(“frequency(MHZ) of WR28”)
df_set_index是單欄的DataFrame還是Series?
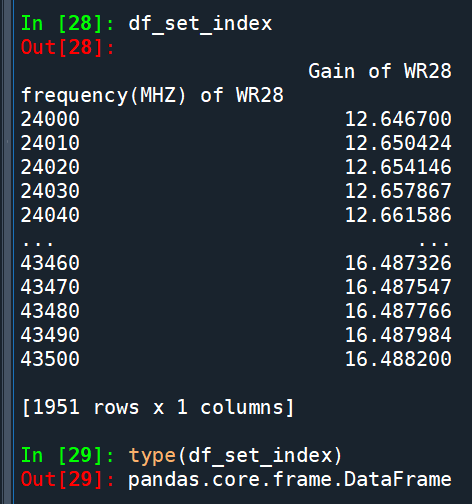
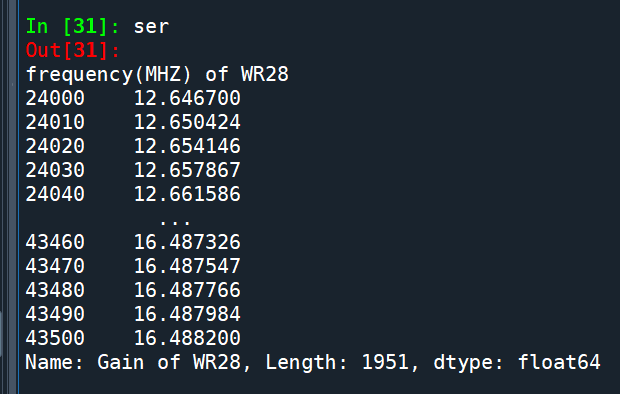
df_set_index是只有單欄的DataFrame
若需要其為Series型態
可以使用squeeze()
ser=df_set_index.squeeze()
推薦hahow線上學習python: https://igrape.net/30afN
![Python: 如何求整個 pandas.DataFrame 中的最大值? pandas.DataFrame .max().max() ; 如何求最大值的index, columns? numpy.where(condition, [x, y, ]/) ; condition為一 bool_mask](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/04/20230418154049_50.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何求整個 pandas.DataFrame 中的最大值? pandas.DataFrame .max().max() ; 如何求最大值的index, columns? numpy.where(condition, [x, y, ]/) ; condition為一 bool_mask")
 as zf")
 ; driver.get(url)")
,版面配置>行號>連續")
")

")
, dtype=float) ; print(data.shape); min0 = numpy.min(a,axis=0) ; min1 = numpy.min(a,axis=1) #2次沿軸1 ; numpy.average() ;array的軸向")



近期留言