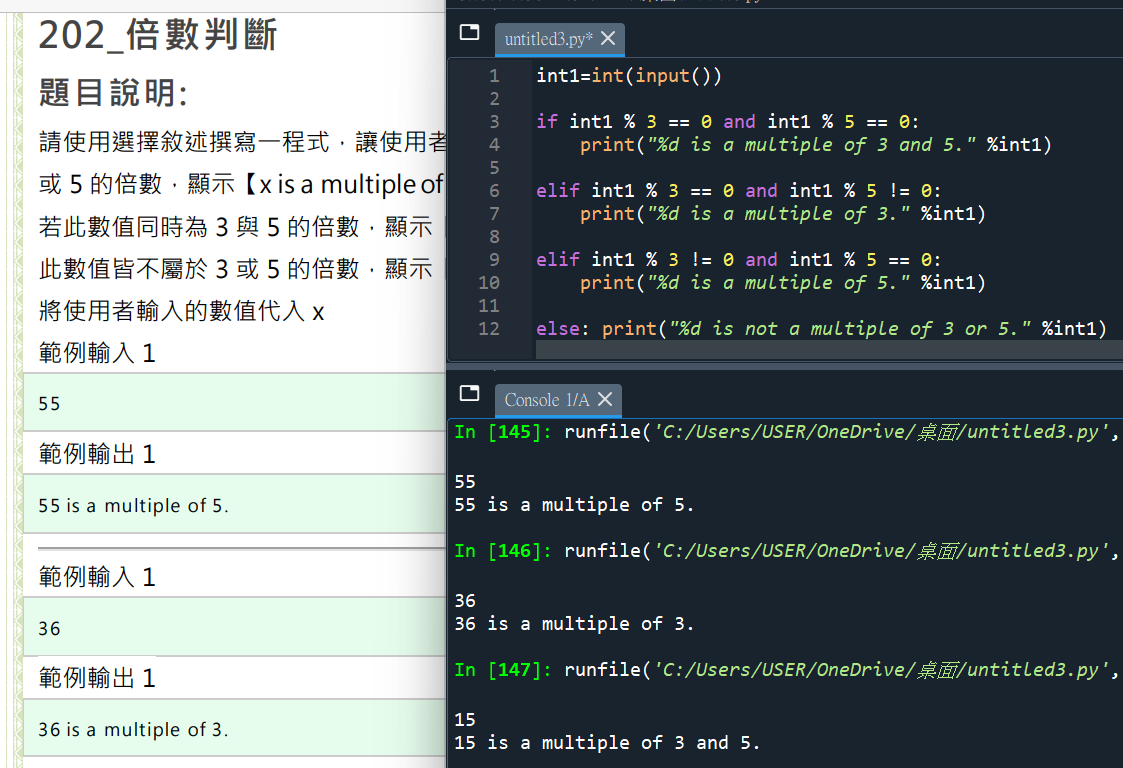
#Python TQC考題202_倍數判斷
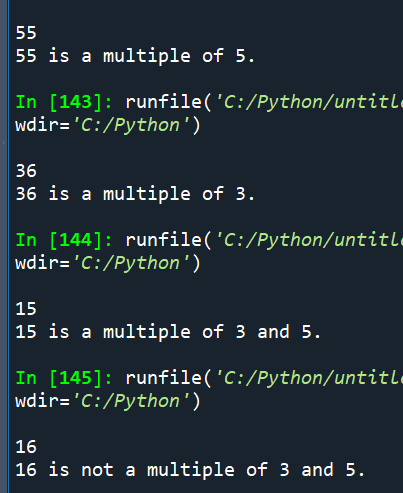
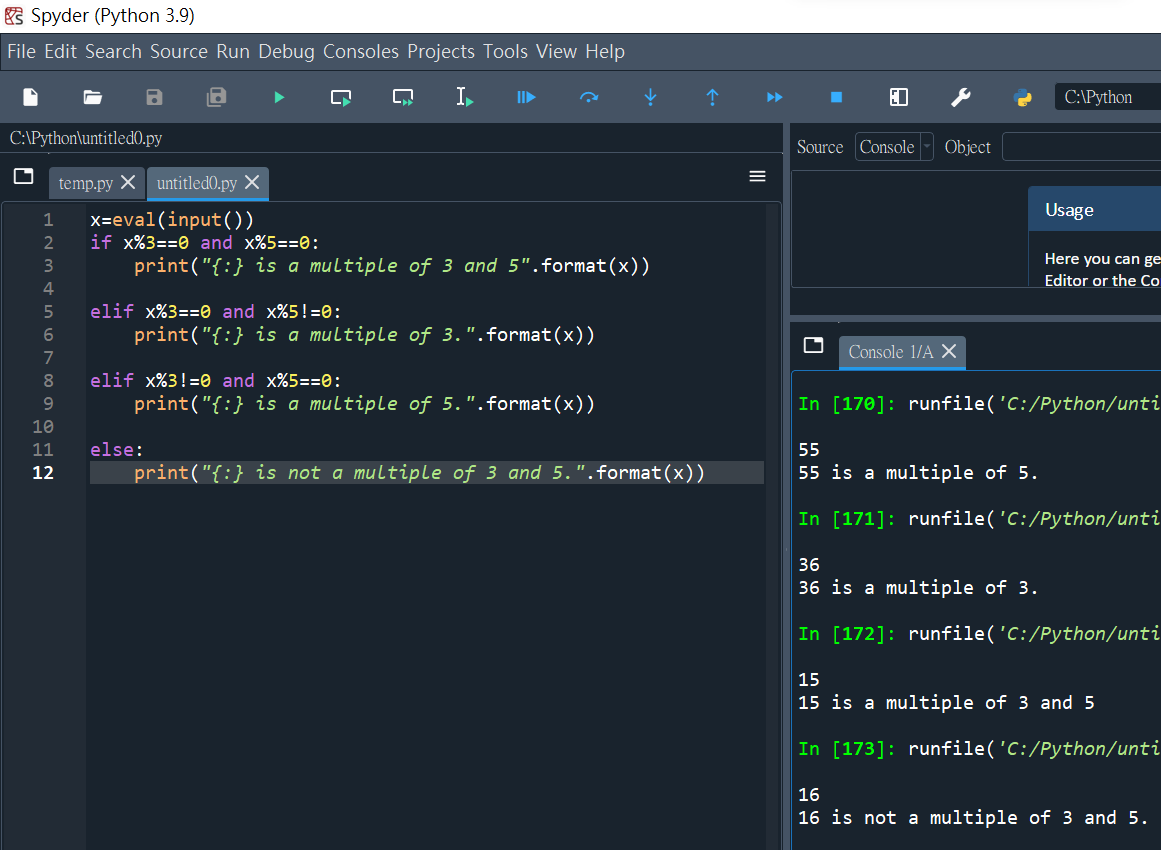
x=eval(input())
if x%3==0 and x%5==0:
print(“{} is a multiple of 3 and 5.”.format(x))
#沒有要設定格式, { }中的:可加可不加
#加了:也可正常執行
elif x%3==0 and x%5!=0:
print(“{} is a multiple of 3.”.format(x))
elif x%3!=0 and x%5==0:
print(“{} is a multiple of 5.”.format(x))
else:
print(“{} is not a multiple of 3 and 5.”.format(x))
# { }中有加:仍可正常執行:
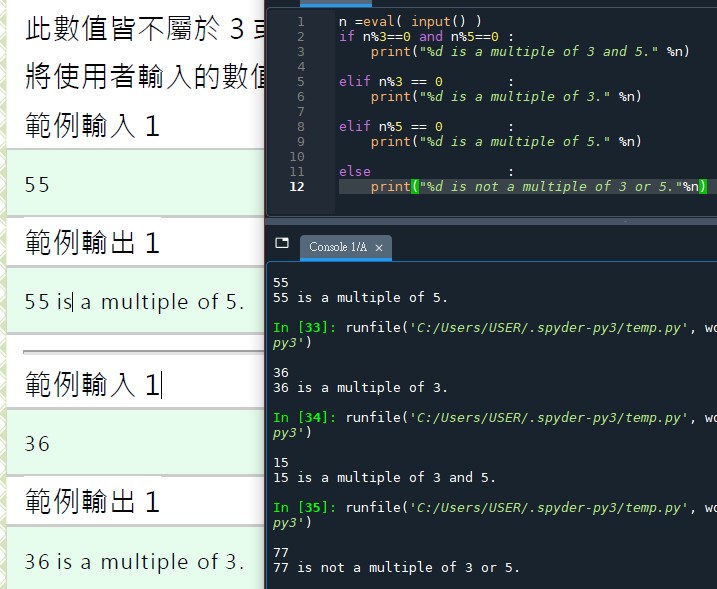
# n%3 == 0,後面再加 and n%5 != 0
#看似比較嚴謹,但沒加沒出錯
![Python: 如何對 pandas.DataFrame 兩欄位運算後,增加到最後一欄? df[‘sum_AB’] = df.apply(sum_ab, axis=1) ; lambda函式](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230314200417_4.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何對 pandas.DataFrame 兩欄位運算後,增加到最後一欄? df[‘sum_AB’] = df.apply(sum_ab, axis=1) ; lambda函式")

")
 實戰:教你如何讓程式碼「自我介紹」; func_name = sys._getframe().f_code.co_name ; inspect.currentframe().f_code.co_name")
 #全數字?、isalpha() #全字母?、isalnum() #全字母或數字?、islower() #全小寫? 和 isupper() #全大寫?")
 as z: print(z.namelist()) ; z.infolist()")
![Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/06/20250609143758_0_53821c.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Pandas GroupBy 的 size 陷阱:為什麼你的計數結果總是不對?如何計算重複次數? duplicates = df.duplicated( subset = [‘name’] )")
與.cget()的差別為何? #configuration ; entry_widget.get() ; label_widget.cget(“text”) ; label_widget = tk.Label( window, text = “Hello, World!”)")
 讀取逗點分隔檔並忽略空列,跳過某些列? dfRaw = pd.read_csv (fpath, skip_blank_lines = True, skiprows =6)")

近期留言