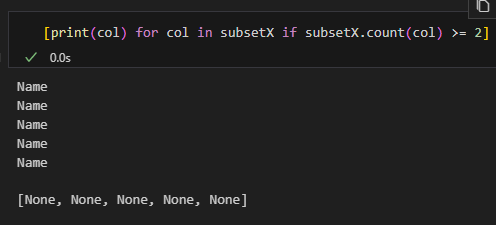
subsetX是一個有重複值的list (Name重複了5次):
['Name',
'Layer Name for DDR',
'Impedance (Ohms) 1 for DDR',
'IL (dB) 1 for DDR',
'Impedance (Ohms) 2 for DDR',
'IL (dB) 2 for DDR',
'Impedance (Ohms) 3 for DDR',
'IL (dB) 3 for DDR',
'Impedance (Ohms) 4 for DDR',
'IL (dB) 4 for DDR',
'Total Area (sq mils) for DDR',
'Line Width 1 (mils) for DDR',
'Length at Width 1 (mils) for DDR',
'Line Width 2 (mils) for DDR',
'Length at Width 2 (mils) for DDR',
'Line Width 3 (mils) for DDR',
'Length at Width 3 (mils) for DDR',
'Line Width 4 (mils) for DDR',
'Length at Width 4 (mils) for DDR',
'Name',
'Layer Name',
'Total Area (sq mils)',
'Line Width 1 (mils)',
'Length at Width 1 (mils)',
'Line Width 2 (mils)',
'Length at Width 2 (mils)',
'Line Width 3 (mils)',
'Length at Width 3 (mils)',
'Line Width 4 (mils)',
'Length at Width 4 (mils)',
'Line Width 5 (mils)',
'Length at Width 5 (mils)',
'Line Width 6 (mils)',
'Length at Width 6 (mils)',
'Line Width 7 (mils)',
'Length at Width 7 (mils)',
'Line Width 8 (mils)',
'Length at Width 8 (mils)',
'Name',
'Total Vias',
'Via Names',
'Via1 FHS(mils)',
'Via2 FHS(mils)',
'Name',
'Tab Number',
'Name',
'VIA Length',
'Via length 1 (mils)',
'Via length 2 (mils)',
'Board thickness',
'Via stub 1 (mils)',
'Via stub 2 (mils)']表達式解析:
[print(col) for col in subsetX if subsetX.count(col) >= 2]if 放在後面 (過濾條件)
當 if 條件放在列表推導式的後面時:
特點: 可能會跳過某些元素
功能: 它是一個過濾器,決定哪些元素會進入推導式
作用: 只有符合條件的元素才會被處理
[表達式 for 變量 in 可迭代對象 if 條件]例如上面的代碼只會對那些在 subsetX 中出現 2 次或更多的元素執行 print()
if 放在前面 (三元運算符)
當 if 條件放在列表推導式的前面時:
- 功能: 它是一個選擇器,決定對每個元素執行哪個表達式
- 作用: 所有元素都會被處理,但會根據條件執行不同的操作
- 特點: 必須搭配
else使用
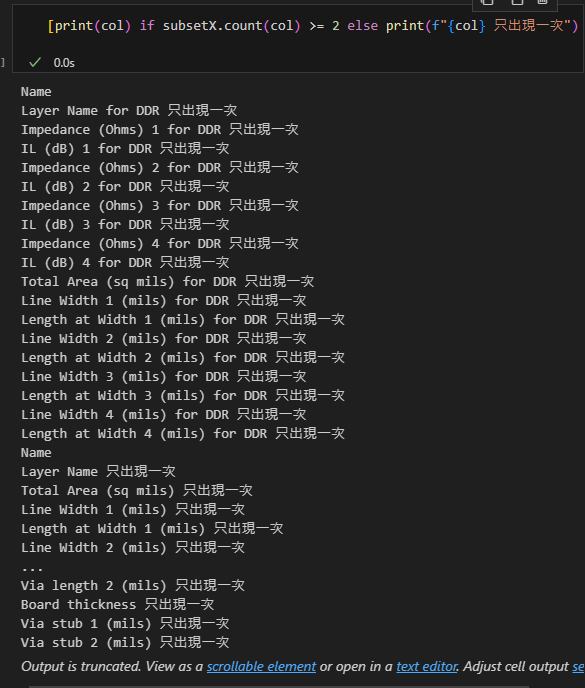
[表達式A if 條件 else 表達式B for 變量 in 可迭代對象]
[print(col) if subsetX.count(col) >= 2 else print(f"{col} 只出現一次") for col in subsetX]輸出結果:
比較:

實用建議
在這個特定情況下,列表推導式主要用於打印操作,會產生一個包含 None 值的無用列表。如果只是為了打印,用普通的 for 循環會更清晰:
for col in subsetX:
if subsetX.count(col) >= 2:
print(col)或者,使用 set 來避免重複打印:
for col in set(subsetX):
if subsetX.count(col) >= 2:
print(f"{col} appears {subsetX.count(col)} times")推薦hahow線上學習python: https://igrape.net/30afN

.resolve().parent")

 ; 那些參數可以設為None?")



![Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select(‘標籤名[屬性名1=”屬性值1″][屬性名2=”屬性值2″]’) ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2025/03/20250330190318_0_925655.jpg?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python爬蟲:BeautifulSoup的 .find_all() 與 .find() 與 .select(‘標籤名[屬性名1=”屬性值1″][屬性名2=”屬性值2″]’) ; from bs4 import BeautifulSoup ; Live Server(可以預覽HTML的VS Code套件)")
 ; result_broadcast = df.apply(func, axis=1, result_type=’broadcast’)")


![Python 進階實戰:深入 Word 核心,挖出那一坨 BLOB (含自省 Debug 技巧, BLOB= Binary Large Object) ; part = doc.part.rels[rid].target_part ; return part.blob if "ImagePart" in type(part).__name__ else None - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/01/20260126111046_0_cd8751-520x245.png)

近期留言