自己建立的csv檔案:
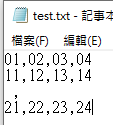
除了奇異的那一列
每一列都有四筆資料
要如何取出第四直欄?
如果直接取的話
因為奇異列的長度太短
會出現
IndexError: list index out of range
用try~except~語法
pass IndexError
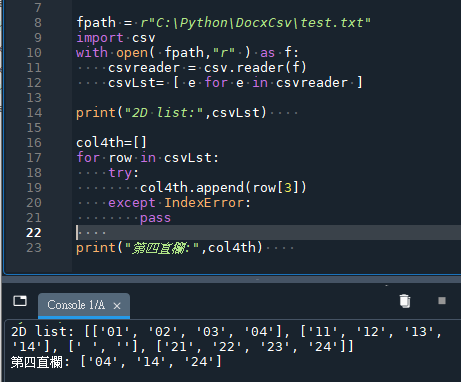
import csv
fpath = r”C:\Python\DocxCsv\test.txt”
with open(fpath, “r”) as f:
csvreader = csv.reader(f)
csvLst = [e for e in csvreader] #這一列要縮排
#沒縮排會出現 ValueError: I/O operation on closed file.
print(“2D list:”, csvLst)
#奇異列為一個空白跟一個空元素
#實際狀況奇異列為: [”] ,長度1,內容為空元素
col4th = []
for row in csvLst:
try:
col4th.append(row[3])
except IndexError:
pass
print(“第四直欄:”, col4th)
推薦hahow線上學習python: https://igrape.net/30afN
例外觸發程序:

捕捉例外狀況:

推薦hahow線上學習python: https://igrape.net/30afN


![Python如何讀取excel檔(.xlsx)?如何用欄標籤提取某一直行?df=pandas.read_excel() ; df[“欄標籤”]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221109163631_39.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python如何讀取excel檔(.xlsx)?如何用欄標籤提取某一直行?df=pandas.read_excel() ; df[“欄標籤”]")
 #全數字?、isalpha() #全字母?、isalnum() #全字母或數字?、islower() #全小寫? 和 isupper() #全大寫?")
 增加新的一欄? model = tensorflow.keras.models.Sequential() #均一化資料")

 正向先行 ; (?!pattern) 負向先行 ; (?<=pattern) 正向回顧 ; (?<!pattern) 負向回顧 ; (? 往後(右)看 ; (?< 往前(左)看 ; =必須符合 ; !不可符合")

![Python-docx 圖片提取完全指南:從 rId 到二進位資料的探險rid ; part = doc.part.rels[rid].target_part #return part.blob if “ImagePart” in type(part).__name__ else None](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260113135812_0_8fa645.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python-docx 圖片提取完全指南:從 rId 到二進位資料的探險rid ; part = doc.part.rels[rid].target_part #return part.blob if “ImagePart” in type(part).__name__ else None")


近期留言