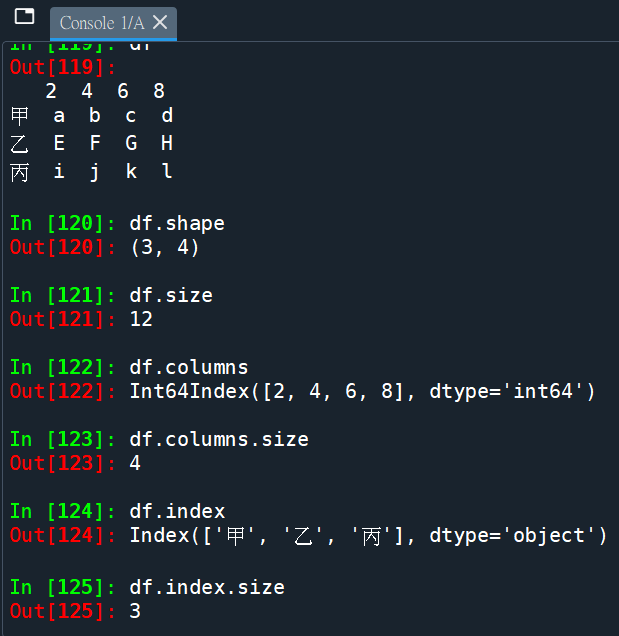
my_data=[
[“a”,”b”,”c”,”d”],
[“E”,”F”,”G”,”H”],
[“i”,”j”,”k”,”l”]
]
import pandas as pd
df = pd.DataFrame(my_data,
index=[“甲”,”乙”,”丙”],
columns=[2,4,6,8])
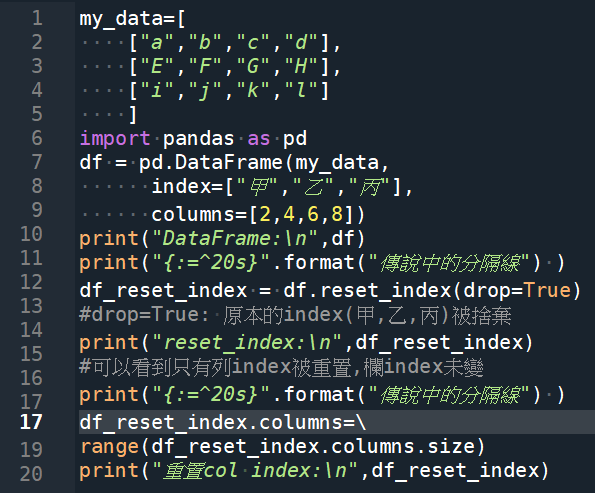
print(“DataFrame:\n”,df)
print(“{:=^20s}”.format(“傳說中的分隔線”) )
df_reset_index = df.reset_index(drop=True)
#drop=True: 原本的index(甲,乙,丙)被捨棄
print(“reset_index:\n”,df_reset_index)
#可以看到只有列index被重置,欄index未變
print(“{:=^20s}”.format(“傳說中的分隔線”) )
df_reset_index.columns=\
range(df_reset_index.columns.size)
“””
#.columns.size可替換為.shape[1]
#也就是说,reindex应该用作根据
已有的索引进行数据操作,
而不能用作创建新的索引。
“””
print(“重置col index:\n”,df_reset_index)
輸出結果:
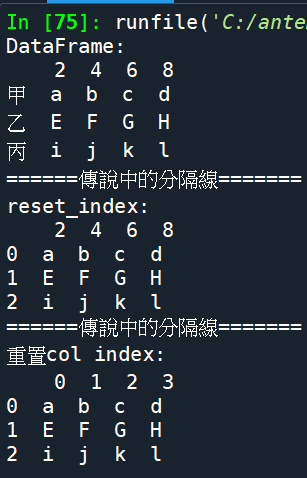
DataFrame的屬性:

DataFrame的屬性:
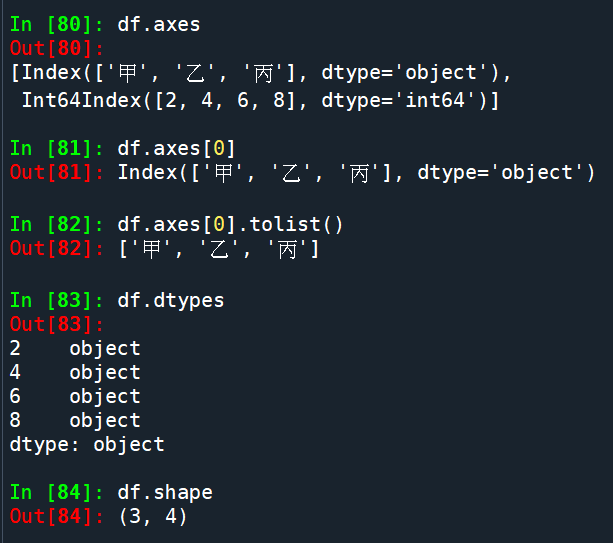
DataFrame的屬性:

DataFrame的屬性:
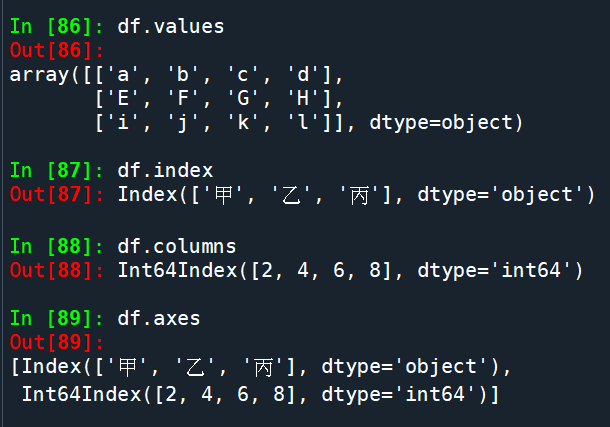
df.columns 與df.keys()同效果:

DataFrame的屬性:
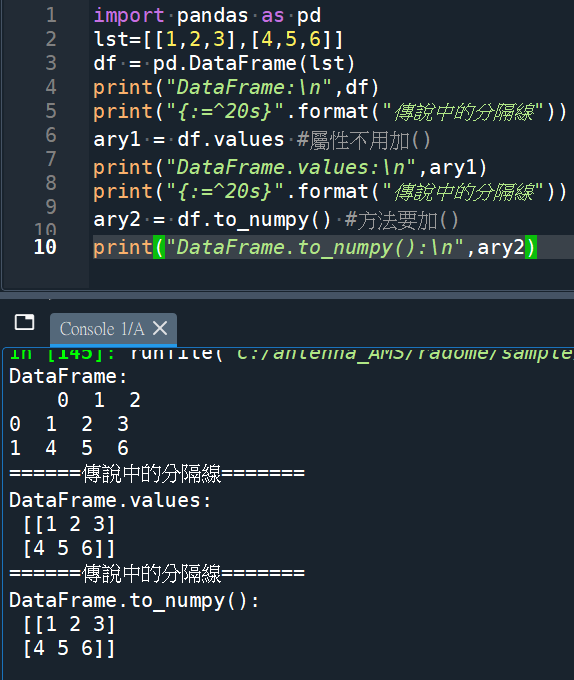
DataFrame轉成ndarray
屬性使用.values #屬性不用() .values 結尾有s
方法使用.to_numpy() #方法要()
官方建議使用 DataFrame.to_numpy() 代替.values


推薦hahow線上學習python: https://igrape.net/30afN
 as writer:")
 vs iterrows() ; for row in df.itertuples ( index=False, name=None)")
 判斷list中是否有True ; all(list) 判斷list中是否全為True ; any(pandas.Series)相當於any(pandas.Series.values) ; i in pandas.Series 卻相當於於i in pandas.Series.index")
 ; parser.add_argument(“–name”) ; args = parser.parse_args()")
 ; str1 = r.recognize_google( audio, language = “zh-TW”)")
 ; median_np = numpy .nanmedian(arr)")
 傳回沿軸最小值的index,參數不能用list,可用numpy.array(),把list轉為array")

")


近期留言