使用pandas.DataFrame.to_excel(r “路徑\檔名.xlsx”)
輸出的excel檔會含有0,1,2,3…的index跟欄標籤:
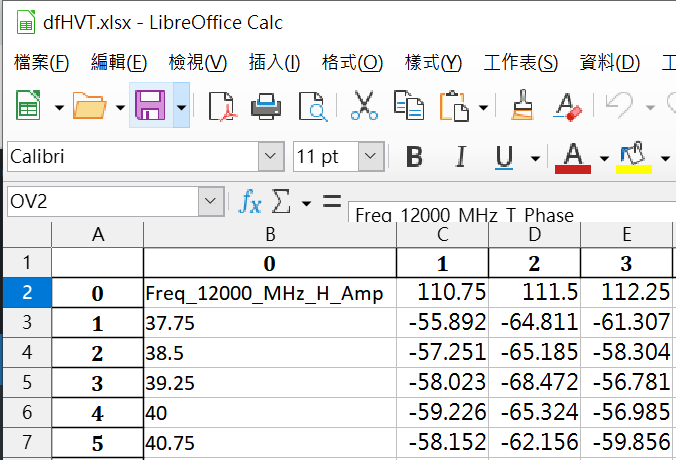
如果將該excel檔用read_excel() 讀進來後
dfHVT = pd.read_excel(r”C:\radome\base\dfHVT.xlsx”)
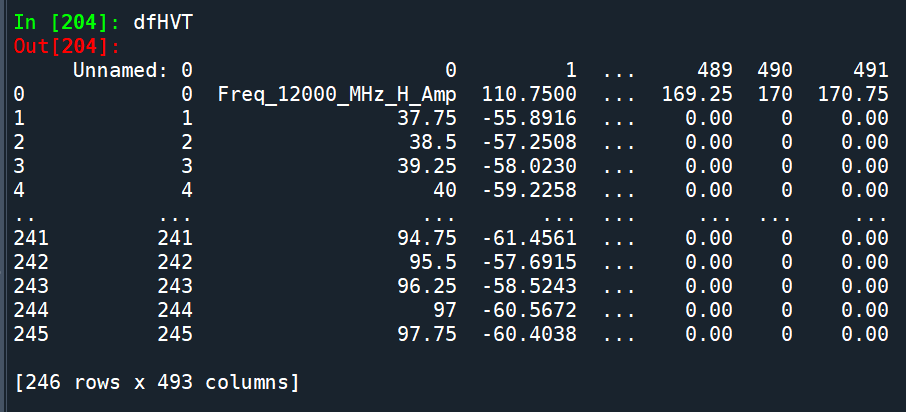
原本index的那一欄多了出來
欄標籤為: “Unnamed: 0”
如何去除該欄?
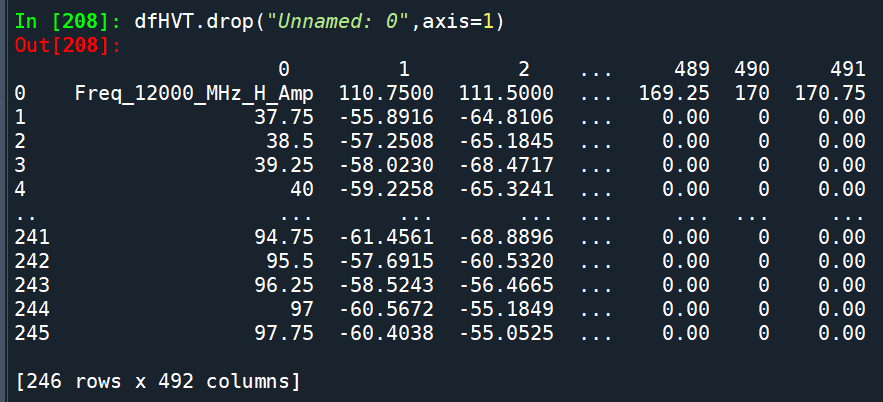
dfHVT1 = dfHVT.drop( “Unnamed: 0”, axis = 1)
該欄的欄標籤就是 “Unnamed: 0”
不要懷疑
axis = 1表示刪除直欄
axis = 0則會刪除橫列
推薦hahow線上學習python: https://igrape.net/30afN
: 如何使用命名捕獲組將字串整理為dict?match.groupdict() ; NAME: sensor-count STATUS: PASSED VALUE: 129 LL: 129 UL:")
, 判定係數 (metrics.r2_score), 皮爾森積差相關係數 (pearsonr) ; 以波士頓地區房價為例")
=”6668″(雙引號不能漏)")
![Python 打造高容錯搜尋引擎:BM25、Bigram 與difflib自動糾錯實戰; from rank_bm25 import BM25Okapi ; bm25 = BM25Okapi(corpus_tokens) #corpus_tokens: list[list[str]]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/02/20260209150527_0_a24c17.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 打造高容錯搜尋引擎:BM25、Bigram 與difflib自動糾錯實戰; from rank_bm25 import BM25Okapi ; bm25 = BM25Okapi(corpus_tokens) #corpus_tokens: list[list[str]]")
![Python: pandas.DataFrame串接; pandas.concat( [df1,df2] , axis=1, ignore_index=True) ; .append() 產生一個新的DataFrame; 插入欄 .insert() 改變原DataFrame](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/11/20221129145451_29.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame串接; pandas.concat( [df1,df2] , axis=1, ignore_index=True) ; .append() 產生一個新的DataFrame; 插入欄 .insert() 改變原DataFrame")


![「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2026/01/20260114094100_0_424ead.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "「Python 的兩條路」:一次搞懂 sys.path (找 .py) 與 os.environ[‘PATH’] (找 .exe) 的愛恨情仇")
 比對字串相似度並儲存結果")

近期留言