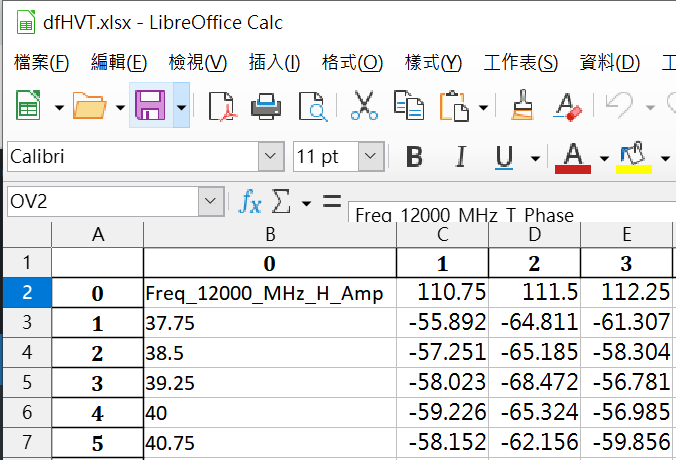
使用pandas.DataFrame.to_excel(r “路徑\檔名.xlsx”)
輸出的excel檔會含有0,1,2,3…的index跟欄標籤:
如果將該excel檔用read_excel() 讀進來後
dfHVT = pd.read_excel(r”C:\radome\base\dfHVT.xlsx”)
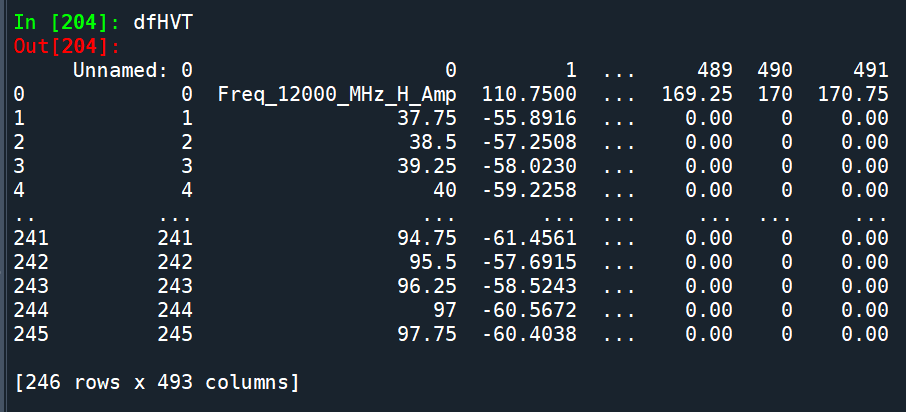
原本index的那一欄多了出來
欄標籤為: “Unnamed: 0”
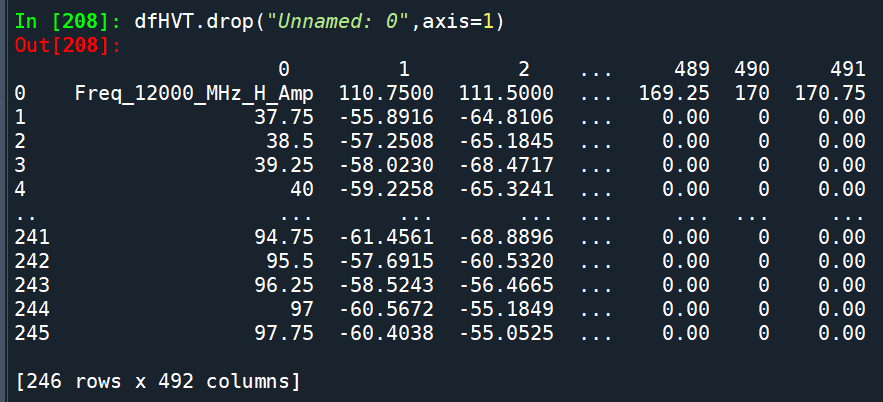
如何去除該欄?
dfHVT1 = dfHVT.drop( “Unnamed: 0”, axis = 1)
該欄的欄標籤就是 “Unnamed: 0”
不要懷疑
axis = 1表示刪除直欄
axis = 0則會刪除橫列
推薦hahow線上學習python: https://igrape.net/30afN
 ; .localtime() ; .tm_year ; .tm_mon ; .tm_mday ; .ctime() #current time ; .sleep() ;time.asctime() #as string ; time.strftime() #string format time")


 ? 如何搭配portable Chrome? from selenium.webdriver.common.by import By ; from selenium.webdriver.chrome.options import Options ; option = Options() ; option.binary_location = chrome_portable_path")



 as s: s.attr(rank=’same’) 如何使用U形排列,營造出node下方有label的效果?取代xlabel功能")

![Python:如何使用 PyMuPDF (import fitz ) 提取 PDF 文本區塊並存儲為 DataFrame ; text: List[ Tuple[float|str|int] ] = page.get_text(“blocks”)](https://savingking.com.tw/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)

近期留言