# Python 爬蟲入門:從 HTML 到 JSON 的快速定位法
當你在爬資料時,常見卡關點不是「怎麼抓到網頁」,
而是「HTML 太長太亂,不知道要找什麼」。
這篇用最小範例示範三件事:
1. 先判斷要抓 **原始 HTML** 還是 **JS 動態載入後的內容**
2. 用 BeautifulSoup 快速定位元素並抽取資料
3. 把「一小塊 DOM」整理成 **JSON**,讓 tag/屬性/文字更好看(也更好決定 selector)
—
## 1) 先搞清楚:你要的是「View Source」還是「Elements」
很多網站是 SPA / 前端框架頁面:
– **View Page Source(Ctrl+U)**:初始 HTML(可能只有空殼)
– **DevTools → Elements**:JS 跑完後的 DOM(你肉眼看到的內容在這裡)
– **DevTools → Network → Fetch/XHR**:前端實際呼叫的 API(常是 JSON)
**最佳策略:能抓 API JSON 就別硬 parse HTML**,更穩定也更快。
—
## 2) 取得 HTML(requests)
# pip install requests beautifulsoup4
import requests
url = "https://example.com"
# timeout=(connect_timeout, read_timeout)
# - connect_timeout:連線建立/握手最多等多久(例:10 秒連不上就放棄)
# - read_timeout:連上後「等下一段回應資料」最多等多久
# (例:30 秒沒資料就 ReadTimeout)
# - 若只寫 timeout=30:等同 timeout=(30, 30)(兩段都用同一個秒數)
resp = requests.get(url, timeout=(10, 30))
resp.raise_for_status()
html = resp.text> 注意:如果網站需要登入、或內容由 JS 動態載入,
`requests` 拿到的 HTML 可能不含你要的資料。
—
## 3) 解析 HTML(BeautifulSoup)
# pip install requests beautifulsoup4
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
# 例:抓 title
print(soup.title.get_text(strip=True))
# 例:抓所有連結
for a in soup.select("a[href]"):
print(a["href"], a.get_text(" ", strip=True))
# 補充:get_text(" ", strip=True)
# - 第一個參數 " " 是分隔符(separator):把不同文字節點用空格隔開,避免字黏在一起
# - strip=True:去掉每段文字前後多餘空白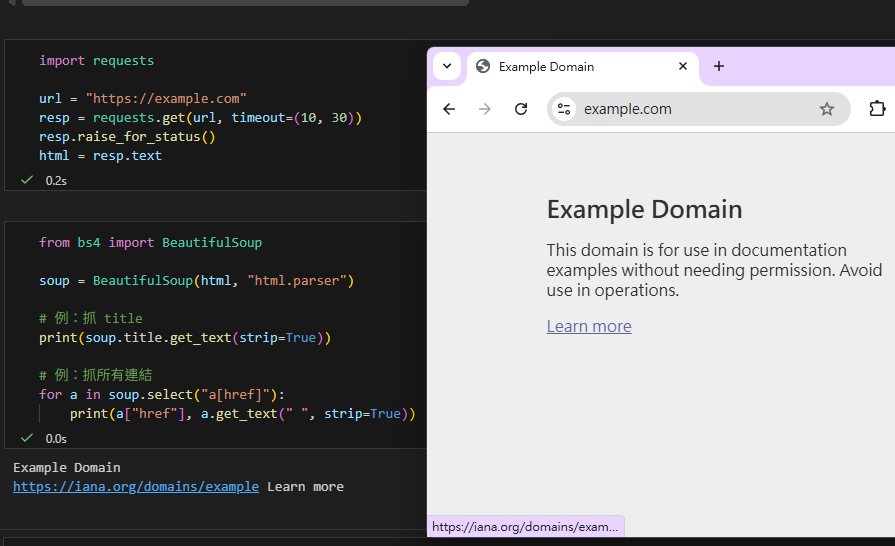
## 4) HTML 太亂?把「重點區塊」轉成 JSON 來觀察
這招的目的不是把整頁變 JSON,而是:
– 你先挑到「看起來像主內容」的節點(例如某個 card / product / article)
– 再把它的 tag/attrs/子節點資訊 dump 成 JSON
– 你會更容易看出:應該用哪個 `class` / `data-*` / 層級關係來寫 selector
### 範例:把節點摘要成 JSON
import json
from bs4 import BeautifulSoup
html = """
<div class='product' data-sku='W-001'>
<h1>Widget</h1>
<span class='price' data-currency='USD'>$19.99</span>
<ul class='spec'>
<li data-k='color'>red</li>
<li data-k='size'>M</li>
</ul>
</div>
"""
soup = BeautifulSoup(html, "html.parser")
node = soup.select_one("div.product")
# node.attrs 的型別是 bs4.element.AttributeDict(dict-like)
# - 讀取時可當作 dict 使用:node.attrs.get("data-sku")、node["data-sku"]
# - 轉成 dict(...) 通常是為了「做快照」與「方便 JSON 序列化/輸出」
view = {
"tag": node.name,
"attrs": dict(node.attrs),
"text": node.get_text(" ", strip=True),
# 只看第一層 children(recursive=False),避免資訊爆炸
# - node.find_all() 若不給 tag/屬性條件,代表「範圍內全部 tag 都抓」
# - recursive=False 代表只抓「直屬子節點」(不往更深層的孫節點找)
"children": [
{"tag": c.name, "attrs": dict(c.attrs),
"text": c.get_text(" ", strip=True)}
for c in node.find_all(recursive=False)
],
}
print(json.dumps(view, ensure_ascii=False, indent=2))你會得到清楚的輸出,例如:
– 主容器是 `div`,並且有屬性(attribute)例如 `class`、`data-sku`
– `class` / `data-sku` 是「屬性名」,`product` / `W-001` 是「屬性值」
– 注意:在 BeautifulSoup 裡
`class` 通常會以 list 呈現(因為 HTML 允許多個 class),
例如 `{“class”: [“product”]}`
– 價格在 `span.price[data-currency]`
– 規格在 `.spec li[data-k]`
接下來 selector 就很容易寫。

## 5) 從 HTML 直接抓 JSON(最常見:JSON-LD / 內嵌 JSON)
很多網站會把關鍵資料直接塞在 `<script>` 裡(這通常比 parse DOM 更穩)。
### 5.1 JSON-LD(SEO 結構化資料)
import json
from bs4 import BeautifulSoup
html = """
<script type="application/ld+json">
{"@context":"https://schema.org","@type":"Product","name":"Widget","sku":"W-001"}
</script>
"""
soup = BeautifulSoup(html, "html.parser")
ld = soup.select_one('script[type="application/ld+json"]')
data = json.loads(ld.string)
print(data["@type"], data.get("name"), data.get("sku"))
### 5.2 內嵌 JSON(SPA/SSR 常見)
import json
from bs4 import BeautifulSoup
html = """
<script id="__DATA__" type="application/json">
{"apiUrl":"/api/items","user":{"id":123,"name":"Ada"}}
</script>
"""
soup = BeautifulSoup(html, "html.parser")
raw = soup.select_one('script#__DATA__[type="application/json"]').string
embedded = json.loads(raw)
print(embedded["apiUrl"], embedded["user"]["name"])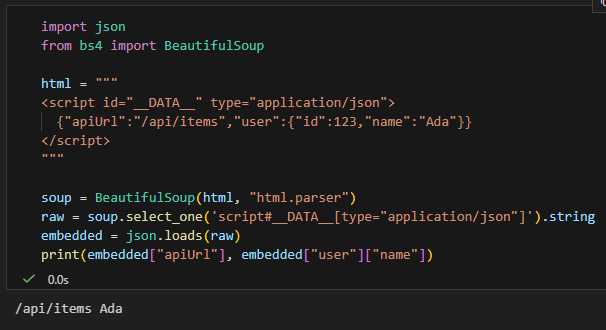
## 6) 小結:什麼時候用「JSON」幫助你爬蟲?
– **你不知道要怎麼寫 selector**:把「一小塊 DOM」dump 成 JSON → 快速看出關鍵 attrs
– **網站本來就藏 JSON**:優先抓 `application/ld+json` / `application/json` / `__NEXT_DATA__`
– **網站由 API 驅動**:去 Network 找 XHR → 直接打 JSON API(最穩)
—
## 參考:快速安裝依賴
pip install requests beautifulsoup4> 補充:`bs4` 是你在程式裡 `from bs4 import BeautifulSoup` 的模組名;用 pip 安裝時請裝 `beautifulsoup4`(而不是 `bs4`)。
>
> 想要解析更快/更穩也可以再裝解析器:`pip install lxml`,並把 parser 改成 `BeautifulSoup(html, “lxml”)`。
推薦hahow線上學習python: https://igrape.net/30afN



![Python: pandas.DataFrame (df) 的取值: df [單一字串] 或df [list_of_strings] 選取一個或多個columns; df [切片] 或 df [bool_Series] 選取多個rows #bool_Series長度同rows, index也需要同df.index ,可以使用.equals() 確認: df.index.equals(mask.index)](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2025/04/20250420212553_0_6fb2c3.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame (df) 的取值: df [單一字串] 或df [list_of_strings] 選取一個或多個columns; df [切片] 或 df [bool_Series] 選取多個rows #bool_Series長度同rows, index也需要同df.index ,可以使用.equals() 確認: df.index.equals(mask.index)")

 內聯修飾符 vs re.I 全域標記,打造無情的「激進截斷」割草機! `(?i)`、`flags=re.I`、`(?i:…)` 的差別")
與副本(Copy) : 避免資料操作錯誤的指南; 如何處理SettingWithCopyWarning ?")
的Button?一按就刪除掉Label + Entry + Button ; trash_icon = tk.PhotoImage( file = trash_icon_path)")

![Python Pathlib 實戰:優雅地篩選多種圖片檔案; images = [f for f in p.glob("*") if f.suffix.lower() in img_extensions] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2026/01/20260128111659_0_736612-520x245.png)

近期留言