## 1. 先認識 Excel 的結構
先把 Excel 想成三層:
1. `workbook`:整本 Excel 檔
2. `worksheet`:其中一頁(例如 `raw_lines`)
3. `cell`:頁面中的單一格
補充:`openpyxl` 的 row/column 是
**1-based**(從 1 開始,不是 0)。
– `A1` = `row=1, column=1`
– `B1` = `row=1, column=2`
– `A2` = `row=2, column=1`
常見錯誤是把 pandas/Python 的 0-based 習慣帶進來,
導致寫到錯誤位置。
口語比喻:
– workbook = 一本筆記本
– worksheet = 某一頁
– cell = 該頁的一個格子
為什麼這個觀念重要:
1. 你在程式裡通常先拿到 workbook(或 writer)
2. 再指定要操作哪一張 worksheet
3. 最後才是逐 row / 逐 cell 寫資料
—
## 2. 為什麼在這個專案用 openpyxl
你現在的流程是:
1. 逐頁讀 PDF
2. 逐 line / block 產生 record
3. 立刻寫進 Excel
這種「邊產生邊寫」模式,openpyxl 很適合,
因為可以直接用 `worksheet.cell(…)` 寫單格資料,
不需要先把整批資料組成 DataFrame。
相對地,pandas 通常是:
1. 先把資料收集成 list / DataFrame
2. 再一次 `to_excel(…)`
所以在你的 ver10 架構裡,兩者分工是合理的:
– openpyxl:高頻、即時、逐列寫入
– pandas:表格清洗、批次輸出、DataFrame 運算
—
## 3. openpyxl 核心用法(你已經在用)
### 2.1 取得 worksheet
你在 `pd.ExcelWriter(…, engine=”openpyxl”)` 中,先用
`sheet_name=”raw_lines”` 建立/寫入該工作表,
再透過:
# 先寫入同名工作表(sheet_name="raw_lines")
# 這行會把 COLUMNS 寫進第 1 列(header),所以資料列要從第 2 列開始。
pd.DataFrame(columns=COLUMNS).to_excel(
writer,
sheet_name="raw_lines",
index=False,
)
# 再從 writer.sheets 取回同一張 worksheet
raw_lines_ws = writer.sheets["raw_lines"]拿到 openpyxl 的 worksheet 物件。
補充:這裡沒有寫 `import openpyxl` 是正常的。
1. `pandas` 看到 `engine=”openpyxl”` 時,會在內部載入 openpyxl
2. 你透過 `writer.sheets[…]` 取得的是 openpyxl worksheet 物件
3. 只有在你要「直接使用 openpyxl API」時,才需要顯式 `import openpyxl`
例如這種情況就要顯式 import:
from openpyxl import load_workbook
wb = load_workbook("demo.xlsx")
ws = wb["raw_lines"]### 2.2 寫單一儲存格
worksheet.cell(row=next_write_row, column=col_index, value=value)特點:
– `row`、`column` 都是 1-based
– 可逐格寫,不需 DataFrame
– 適合 generator 流程
– 變數建議命名為 `next_write_row`(比 `next_row` 更精確)
### 2.3 用欄位順序寫一整列
建議先用「概念版」理解,再看「工程版」。
概念版(最好懂):
for record in records: # 逐 row
for col_index, name in enumerate(COLUMNS, start=1): # row 內逐 cell
ws.cell(row=row_no, column=col_index, value=record.get(name))
row_no += 1工程版(最好維護):
def append_row_to_sheet(ws, columns, record, row_no):
for col_index, column_name in enumerate(columns, start=1):
ws.cell(
row=row_no,
column=col_index,
value=to_excel_cell_value(record.get(column_name)),
)
return row_no + 1工程版本質和概念版相同,只是把「row 內逐 cell」抽成 helper,方便重用與集中維護。
—
## 4. 最小可用範例(概念版 + 工程版)
### 3.1 概念版(直接雙層 for)
import pandas as pd
COLUMNS = ["page", "line_no", "text"]
path = r"D:\Temp\demo.xlsx"
with pd.ExcelWriter(path, engine="openpyxl") as writer:
pd.DataFrame(columns=COLUMNS).to_excel(writer, sheet_name="raw_lines", index=False)
ws = writer.sheets["raw_lines"]
records = [
{"page": 1, "line_no": 1, "text": "Hello"},
{"page": 1, "line_no": 2, "text": "World"},
]
row_no = 2 # 第 1 列已是 header,資料從第 2 列開始
for record in records: # 逐 row
for col_index, name in enumerate(COLUMNS, start=1): # row 內逐 cell
ws.cell(row=row_no, column=col_index, value=record.get(name))
row_no += 1
print(f"Excel 已輸出:{path}")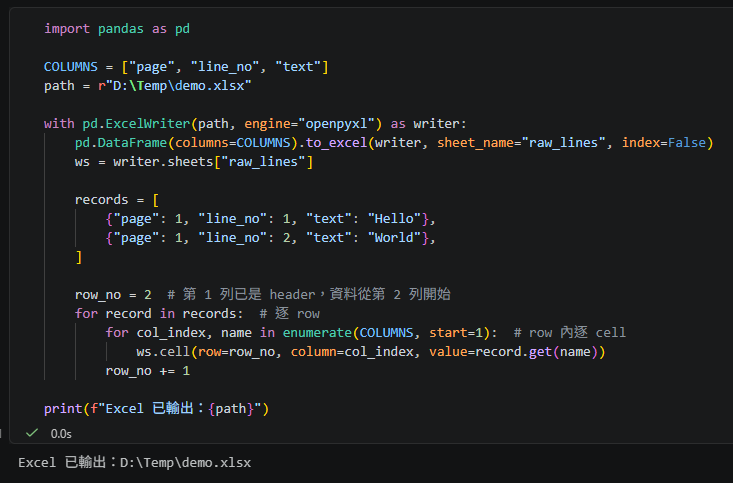
Excel 已輸出:D:\Temp\demo.xlsx

### 3.2 工程版(抽小函數)
import pandas as pd
COLUMNS = ["page", "line_no", "text"]
path = r"D:\Temp\demo.xlsx"
def append_row_to_sheet(ws, columns, record, row_no):
for col_index, name in enumerate(columns, start=1):
ws.cell(row=row_no, column=col_index, value=record.get(name))
return row_no + 1
with pd.ExcelWriter(path, engine="openpyxl") as writer:
# 先寫 header
pd.DataFrame(columns=COLUMNS).to_excel(writer, sheet_name="raw_lines", index=False)
ws = writer.sheets["raw_lines"]
# 模擬 generator 逐 row 產生
records = [
{"page": 1, "line_no": 1, "text": "Hello"},
{"page": 1, "line_no": 2, "text": "World"},
]
row_no = 2 # 第 1 列已是 header,資料從第 2 列開始
for record in records:
row_no = append_row_to_sheet(ws, COLUMNS, record, row_no)
print(f"Excel 已輸出:{path}")—
## 5. 什麼情況用 pandas 反而更好
如果你有以下需求,pandas 會更省事:
1. 要做大量彙總、groupby、pivot
2. 一次性輸出完整表格
3. 表格來源本來就是 DataFrame
例如你現在的 `tables_index`、
`tables_all` 部分就很適合 pandas 批次寫。
—
## 6. openpyxl 在串流寫入時的注意事項
### 5.1 列號要自己管理
已經做對了:
– header 在第 1 列
– `next_write_row` 從 2 開始
– 每寫一列後 `+1`
### 5.2 值轉換要集中處理
目前的 `to_excel_cell_value()` 很重要,特別是:
– 避免 `=` 開頭變公式
– 將 NA 轉成空值
這能避免 Excel 顯示和安全問題。
### 5.3 避免在內層做重計算
逐筆寫入時,內層迴圈要保持輕量。像目前這樣:
– 欄位順序固定
– value 取值直接
– 輕量型態轉換
## 7. 這份程式的最佳實踐總結
1. `pd.ExcelWriter(engine=”openpyxl”)` 建立工作簿與 sheet header
2. `writer.sheets[…]` 取到 worksheet
3. 用 `append_row_to_sheet()` 做逐筆串流寫入
4. `next_write_row`(或 `row_no`)明確管理 1-based row index
5. 表格型資料(DataFrame 友善)仍交給 pandas 批次寫
這是很穩健的混合模式。
—
## 8. 一句話決策規則
– 資料是「一筆一筆即時產生」:優先 openpyxl
– 資料是「已經成批且需要分析」:優先 pandas
– 專案:混用是最佳解
推薦hahow線上學習python: https://igrape.net/30afN
 ; ax.xaxis.set_minor_locator(minor_locator)")
")
, list(n)*m #有m個元素n, ndarray.tolist()可以將array轉為list")
![Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/09/20220923222039_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 自定義函數計算計程車車資(先typing,再用預設值), 巢狀字典以及typing.Union[ ], assert 斷言")
:使用 ignore_index=True 合併 DataFrame 的奧秘 #效果同 reset_index( drop=True )")
 字符串編碼與轉換,ord()函數求得chr的ASCII碼,struct.pack()")
? 為什麼 np.nan == np.nan 返回 False? numpy.isnan() ; pandas.isna() ; pandas.isnull() ; np.isnan() 只能處理數值型資料(np.nan) ; pd.isna() , pd.isnull() 除了np.nan以外,還可以處理None, pd.DataFrame, pd.Series")
; typing : np.ndarray")




近期留言