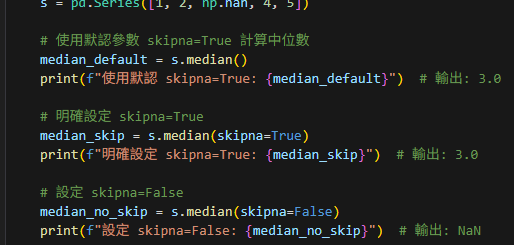
import pandas as pd
data = {‘id’: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
‘name’: [‘John’, ‘Anna’, ‘John’, ‘Anna’,
‘John’, ‘Anna’, ‘John’, ‘Anna’,
‘John’, ‘Anna’]}
df = pd.DataFrame(data)
duplicates = df.duplicated(subset=[‘name’])
counts = df[duplicates].groupby([‘name’]).size().reset_index(name=’count’)
print(counts)
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230316131103_65.png)
df:
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230316131246_13.png)
duplicates = df.duplicated(subset=[‘name’])
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230316131641_17.png)
duplicates 為一個bool Series
透過呼叫 df.duplicated(subset=['name']) 來產生的。
其中subset 參數指定了要檢查是否有重複值的欄位,
這裡是 name 欄位。
可以用來切片
只保留對應到True的元素
counts = df[duplicates].groupby([‘name’]).size().reset_index(name=’count’)
一步一步做分解動作
df[duplicates]:
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230316132030_85.png)
df[duplicates] 會篩選出 df 中
所有被標示為重複的紀錄
只保留對應到True(重複)的元素
注意最左邊的index,已經沒有0,1
df[duplicates].groupby([‘name’]).size()
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230316133109_31.png)
呼叫 groupby 方法,
以 name 欄位為分組依據(name變成index了),
並呼叫 size 方法計算每個分組的大小,
也就是重複出現的次數。
其type為Series:
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230316151507_14.png)
df[duplicates].groupby([‘name’]).size().reset_index(name=’count’)
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230316133443_71.png)
呼叫 reset_index 方法,
將 name 欄位轉換為普通欄位,
並將計算結果命名為 count。
最終產生的 counts
groupby操作的結果是一個Series,
其中包含數量值,
而組的名稱(在這種情況下,是 ‘name’ 列中的值)則作為索引。
通過調用 .reset_index(name=’count’),
你將這個Series轉換回一個DataFrame,
‘name’ 索引變成DataFrame的一個列,
而計數值則成為另一個名為 ‘count’ 的列。
在這種情況下,’count’ 列明顯包含計數值,
因為它是通過在groupby對象上調用 size() 方法創建的,
該方法計算每個組的出現次數。
groupby() :
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230316141426_82.png)
就算資料是DataFrame,
有”fruit” “price”兩欄
經過groupby(“fruit”).size()
index就是”fruit”, values為重複次數
必然是只有一欄資料的Series
.reset_index(name=”count”)
當然只會為唯一一欄命名
.reset_index(name=”count”)
.to_frame(name=”count”).reset_index()
同效果
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230317083859_100.png)
.to_frame(name=”count”) .reset_index()
去掉結尾的.reset_index()
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230317084205_91.png)
to_frame() 方法将当前 Series 转换为一个 DataFrame,
新 DataFrame 只有一 column,
并可以通过 name 参数指定该column的名称。
groupby() 可以對兩欄作用:
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby(['name']) .size() .reset_index(name='count') - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230317130219_79.png)
推薦hahow線上學習python: https://igrape.net/30afN
 ; json的保留字:null, true, false(區分大小寫,全小寫), null(非”null”,非Null)自動轉譯為None, true(非”true”,非True)自動轉譯為True(bool), false(非”false”,非False)自動轉譯為False(bool);colab如何掛載雲端硬碟? from google.colab import drive ; json檔的decode與encode? json.load() ; json.loads() ; json.dump() ; json.dumps() #s代表string的意思,有s的指令,參數需使用str type")
![Python TQC考題404 數字反轉判斷,n_rev=n[::-1], list1.reverse()](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/04/20220825152414_97.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題404 數字反轉判斷,n_rev=n[::-1], list1.reverse()")
 ; table = Table(child, doc)")
)")
![Python TQC考題910 學生基本資料, print(line.decode(“utf-8”)), if line.decode(“utf-8″).split()[2] ==”0”: female += 1](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2022/05/20220514163621_72.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python TQC考題910 學生基本資料, print(line.decode(“utf-8”)), if line.decode(“utf-8″).split()[2] ==”0”: female += 1")


![Python: List[ pandas.Series ] 轉DataFrame技巧:正確理解row和column的關係,同 concat( List[ pandas.Series ], axis=1 ).T](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/04/20250422150133_0_1cfa94.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: List[ pandas.Series ] 轉DataFrame技巧:正確理解row和column的關係,同 concat( List[ pandas.Series ], axis=1 ).T")


近期留言