#Python TQC考題210_三角形判斷
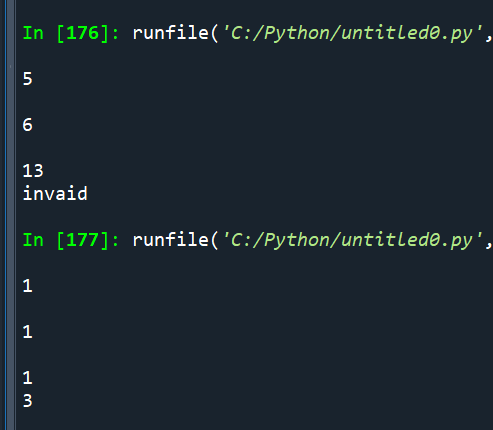
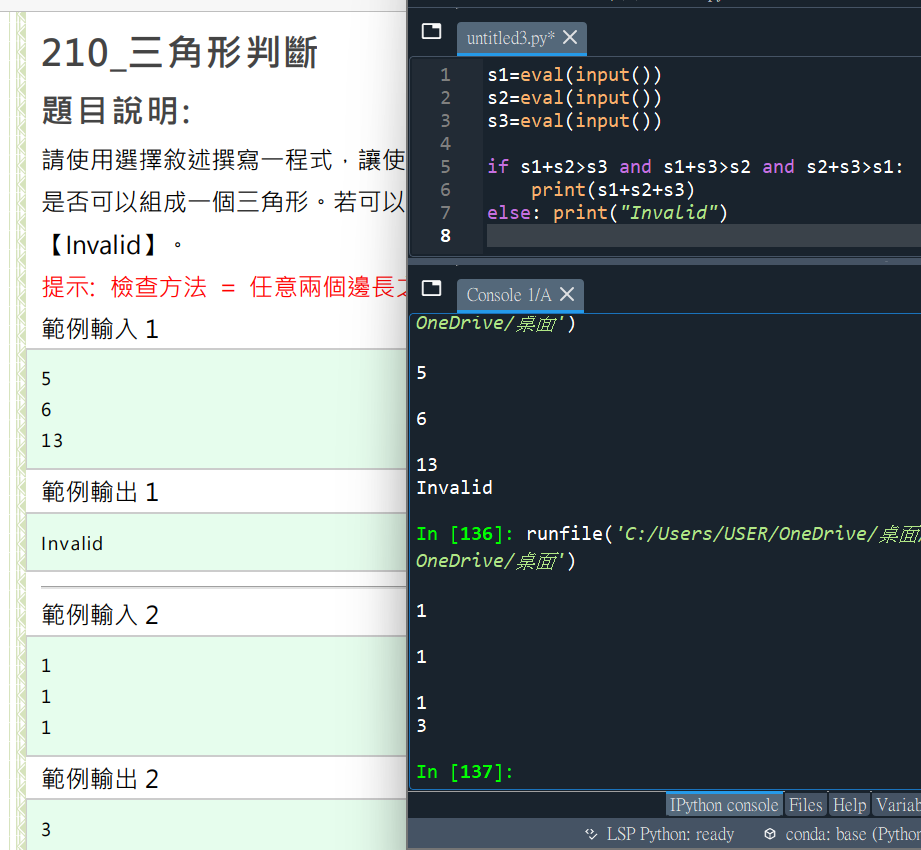
s1 = eval(input())
s2 = eval(input())
s3 = eval(input())
if s1+s2<s3: print(“invaid”)
elif s1+s3<s2:print(“invalid”)
elif s2+s3<s1:print(“invalid”)
else: print(s1+s2+s3)
Spyder執行結果:
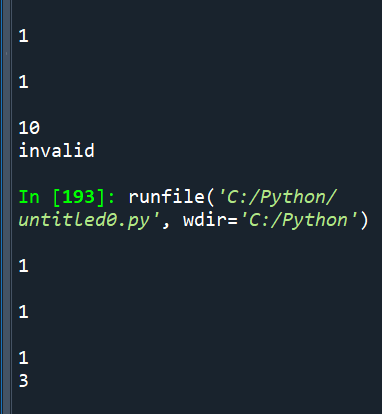
第二種寫法:
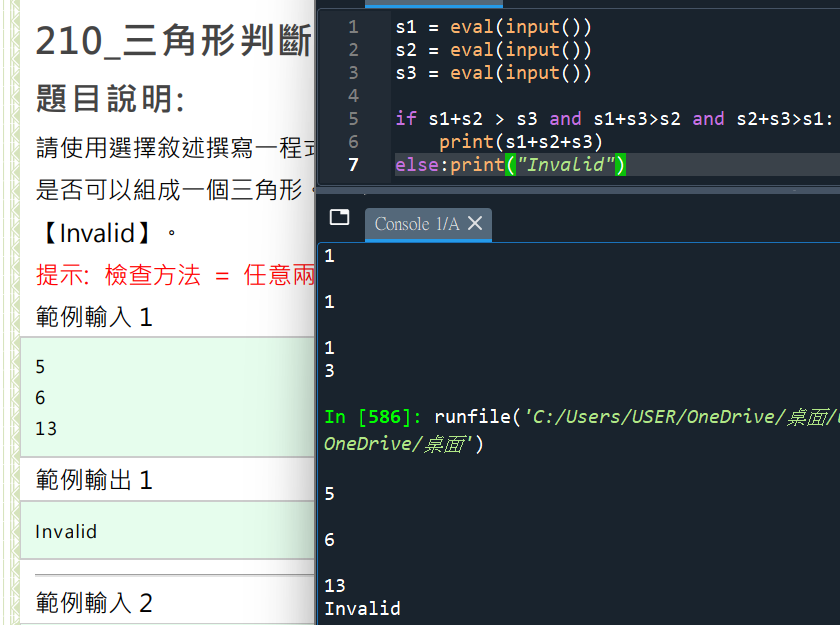
s1=eval(input())
s2=eval(input())
s3=eval(input())
if s1+s2>s3 and s1+s3>s2 and s2+s3>s1:
print(s1+s2+s3)
else:
print(“invalid”)
執行結果:
![Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby([‘name’]) .size() .reset_index(name=’count’)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230316131103_65.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame 如何找出重複值並計算重複次數? counts = df[duplicates] .groupby([‘name’]) .size() .reset_index(name=’count’)")
![Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis]](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/03/20230313184351_57.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis]")
")
")
 ,19歲奧運跆拳銅牌美少女羅嘉翎的國光獎金,應該一次領500萬?還是終身月領2.4萬?Excel財務函數PMT, RATE, NPER, PV, FV")
 ; pickle.loads(binary_data)")

反轉 .sort()排序 .remove(“指定元素”)移除 .pop(index)移除, 字串.replace(old,new) .lower()小寫 .upper()大寫 .title()首字大寫")
 方法說明,計算唯一值的數量,與 len( pandas.Series.unique() ) 同效果")

近期留言