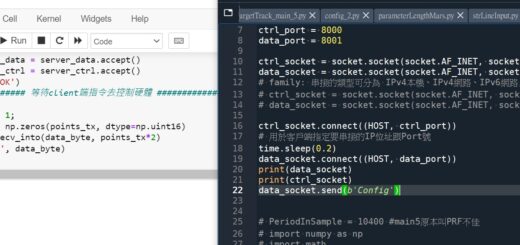
import numpy
a = numpy.array([[1,2,3,4],[5,6,7,8],[9,8,7,6]])
print(“2D Array: \n”,a)
print(“提取2D array的一部分: \n”,a[1:,2:])
“””
a[1:,2:]
1: , 2:
:之後,沒有指定終止index,
表示含最後一個元素都算
若有指定終止index
終止index的元素不算
“””
![Python提取2D array的一部份資料; import numpy; a[1: , 2:] ; a[1:-1 , 2:-1] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/09/20220906112909_96.png)
以下有指定終止元素的index
(-1是最後一個元素的index)
提取就不含終止元素:
![Python提取2D array的一部份資料; import numpy; a[1: , 2:] ; a[1:-1 , 2:-1] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/09/20220906122145_65.png)
row有指定終止元素的index
col無指定終止元素的index:
![Python提取2D array的一部份資料; import numpy; a[1: , 2:] ; a[1:-1 , 2:-1] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/09/20220906122441_97.png)
list原本就是這樣指定範圍
list[startIdx:endIdx:step]
startIdx未指定則從0開始
endIdx未指定則到最後一個元素(含)
step未指定則為1
現在2D Array一樣意思
[ [list1] , [list2] ]
/100: .0f})”) ; lambda匿名函数 ; 前綴 f “{變數or運算式: .0f}” 格式化字串")
")

 or(|) xor(^) not")
![Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f”.//{ qn(‘a:blip’) }” ) ; .get( qn(“r:embed”) ) #獲取 屬性名 ‘r:embed’ 的 屬性值(如: ‘rId4’) ; lxml.etree._Element.xpath( “//a:blip/@r:embed”, namespaces = NS) #/@r:embed = 獲取 屬性名 ‘r:embed’ 的 屬性值(如: ‘rId4’),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用”//a:blip/@r:embed” ,可直接獲取屬性值(List[str]如: [‘rId4’, ‘rId5’]) ; 如何對docx真實移除圖片瘦身?](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2025/11/20251119130848_0_3fbf6b.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 讀取 DOCX 圖片關聯:qn+find/findall 與 XPath 的實戰對照 from lxml import etree ; from docx.oxml.ns import qn; lxml.etree._Element.findall( f”.//{ qn(‘a:blip’) }” ) ; .get( qn(“r:embed”) ) #獲取 屬性名 ‘r:embed’ 的 屬性值(如: ‘rId4’) ; lxml.etree._Element.xpath( “//a:blip/@r:embed”, namespaces = NS) #/@r:embed = 獲取 屬性名 ‘r:embed’ 的 屬性值(如: ‘rId4’),使用.findall() 要先.findall()獲取List[_Element],再迴圈_Element.get()獲取屬性值, .xpath() 第一個參數path 使用”//a:blip/@r:embed” ,可直接獲取屬性值(List[str]如: [‘rId4’, ‘rId5’]) ; 如何對docx真實移除圖片瘦身?")
 或 ary1 @ ary2 或 numpy.dot (ary1, ary2)")

![Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2023/02/20230216183536_29.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib繪製出的圖表如何插入背景圖? img = plt.imread(‘background_image.png’) ; ax.imshow(img, extent=[0, 10, -1.2, 1.2], aspect=’auto’, alpha=0.5)")
 與 os.path.exists() 有何差別?")


近期留言