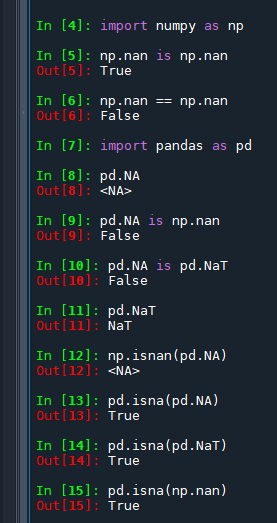
np.isnan() 無法正確處理 pd.NA,這是因為 pd.NA 是 pandas 庫專門為了處理缺失數據而設計的新類型,而 np.isnan() 是 NumPy 提供的函數,主要用於檢測浮點數中的 NaN 值。這兩個庫雖然緊密相關,但它們處理缺失值的方式存在差異。
NumPy 的 np.isnan()
np.isnan() 是一個函數,設計用來檢查浮點數是否為 NaN(Not a Number)。
當 np.isnan() 接收到不是浮點數的輸入(例如 pandas 的 pd.NA),它的行為可能不符合預期。在嘗試處理 pd.NA 時,np.isnan() 並不拋出錯誤,而是返回 pd.NA 作為輸出,這反映了 pandas 對 NumPy 函數的一種兼容性擴展,使得 pandas 的缺失值標記能在不確定的情況下保持其類型。
pandas 的 pd.isna()
pd.isna() 是 pandas 提供的函數,用於更廣泛地檢測各種類型的缺失值,包括 np.nan、None、pd.NA 以及 pd.NaT。
pd.isna() 能夠處理包括 pandas 自身的缺失值標記 pd.NA 在內的多種數據類型,這使得它在處理 pandas 對象時特別有用。
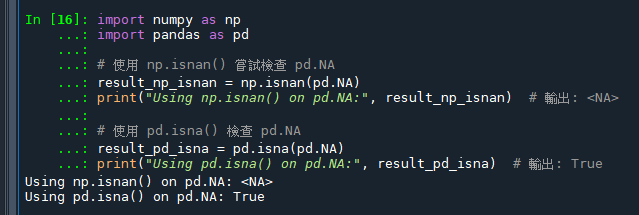
當處理包含 pandas 特有缺失值標記的數據時,推薦使用 pd.isna() 而不是 np.isnan()。這樣可以確保所有類型的缺失值都能被正確識別和處理。這種方法更適合 pandas 的數據結構和類型處理方式,而 np.isnan() 更適用於處理純 NumPy 數組中的浮點數缺失值。
當您使用 pandas 從 Excel 文件讀取數據時,默認情況下,pandas 會將缺失值轉換為 np.nan,特別是在處理典型的數值數據時。這主要是因為 np.nan 是一個相對較舊的標準,廣泛用於表示浮點數中的缺失值。然而,隨著 pandas 的發展,引入了更通用的缺失值標記 pd.NA,它旨在處理除浮點數之外的其他數據類型的缺失值,如整數、布爾值和字符串。
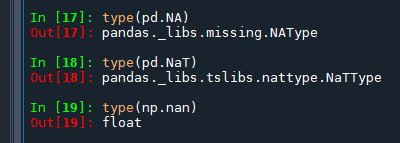
確定缺失值類型的方法
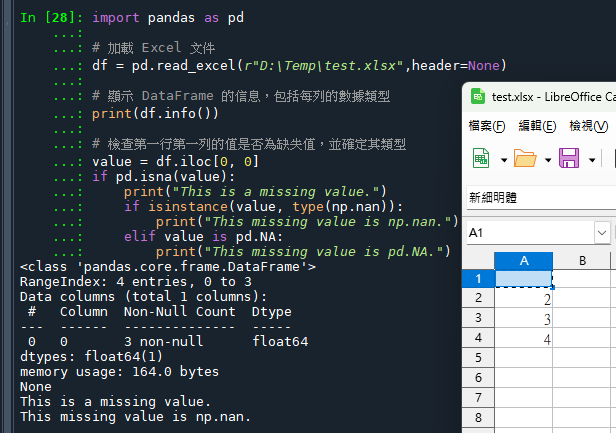
要確定在從 Excel 讀取之後 DataFrame 中的缺失值類型,您可以使用以下方法:
檢查數據類型:查看 DataFrame 的數據類型可能會給出一些線索。如果列的數據類型是 float,那麽缺失值很可能是 np.nan。如果列的數據類型是 pandas 的擴展類型(如 ‘Int64’(注意是大寫的 I),這是 pandas 的可空整數類型),那麽缺失值可能是 pd.NA。
直接檢查值:使用 pd.isna() 函數檢查某個具體值是否為缺失值。pd.isna() 能同時識別 np.nan 和 pd.NA。
示例
下面的代碼示例展示了如何導入一個 Excel 文件,並檢查 DataFrame 中的缺失值類型:
轉換為 pd.NA
如果您希望統一使用 pd.NA 來處理缺失值(特別是當您的數據中包含整數、布爾值或對象類型時),可以在讀取 Excel 文件時或之後轉換 DataFrame 的缺失值。使用 convert_dtypes() 方法可以自動將 DataFrame 轉換為使用 pandas 的可空數據類型,並將缺失值設置為 pd.NA:
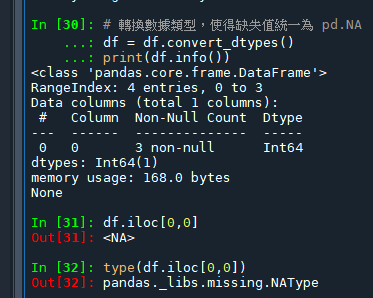
這樣,您可以確保 DataFrame 中使用的是最新的、兼容不同數據類型的缺失值表示方法。這對於維護數據的一致性和後續處理特別重要。
推薦hahow線上學習python: https://igrape.net/30afN

 如何分離詞性? jieba.posseg.cut() #pos: Part Of Speech (POS,詞性) #seg (segment, 切分)")
")
from openai import AsyncAzureOpenAI")

")
![Python: pandas.DataFrame的串接 pandas.concat() #concatenate 連接, 如何重新排列columns 順序? df[[“甲”, “乙”, “丙”]] ; df.reindex( columns = [“甲”, “乙”, “丙”] )](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20241120092030_0_98dff3.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: pandas.DataFrame的串接 pandas.concat() #concatenate 連接, 如何重新排列columns 順序? df[[“甲”, “乙”, “丙”]] ; df.reindex( columns = [“甲”, “乙”, “丙”] )")
 vs 深拷貝(deep copy),什麼時候需要用深拷貝? import copy ; b = copy.deepcopy(a)")
的函式.rfind() .replace() 切片與串接; 如何尋找直欄中,含有特定關鍵字的列數? pandas.Series.str.contains(“Hz”) ;如何將Series中的內容去掉首末的空格並小寫? pandas.Series .str.strip() .str.lower() #需要兩次.str")

近期留言