Word長篇文件編輯,TQC考題404旅遊景點
鼠標移到紅色字體
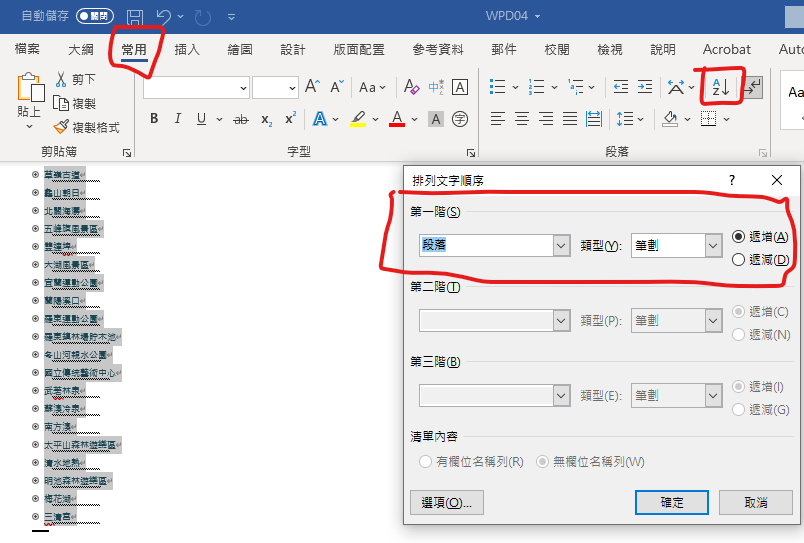
選取格式設定類似的所有文字:
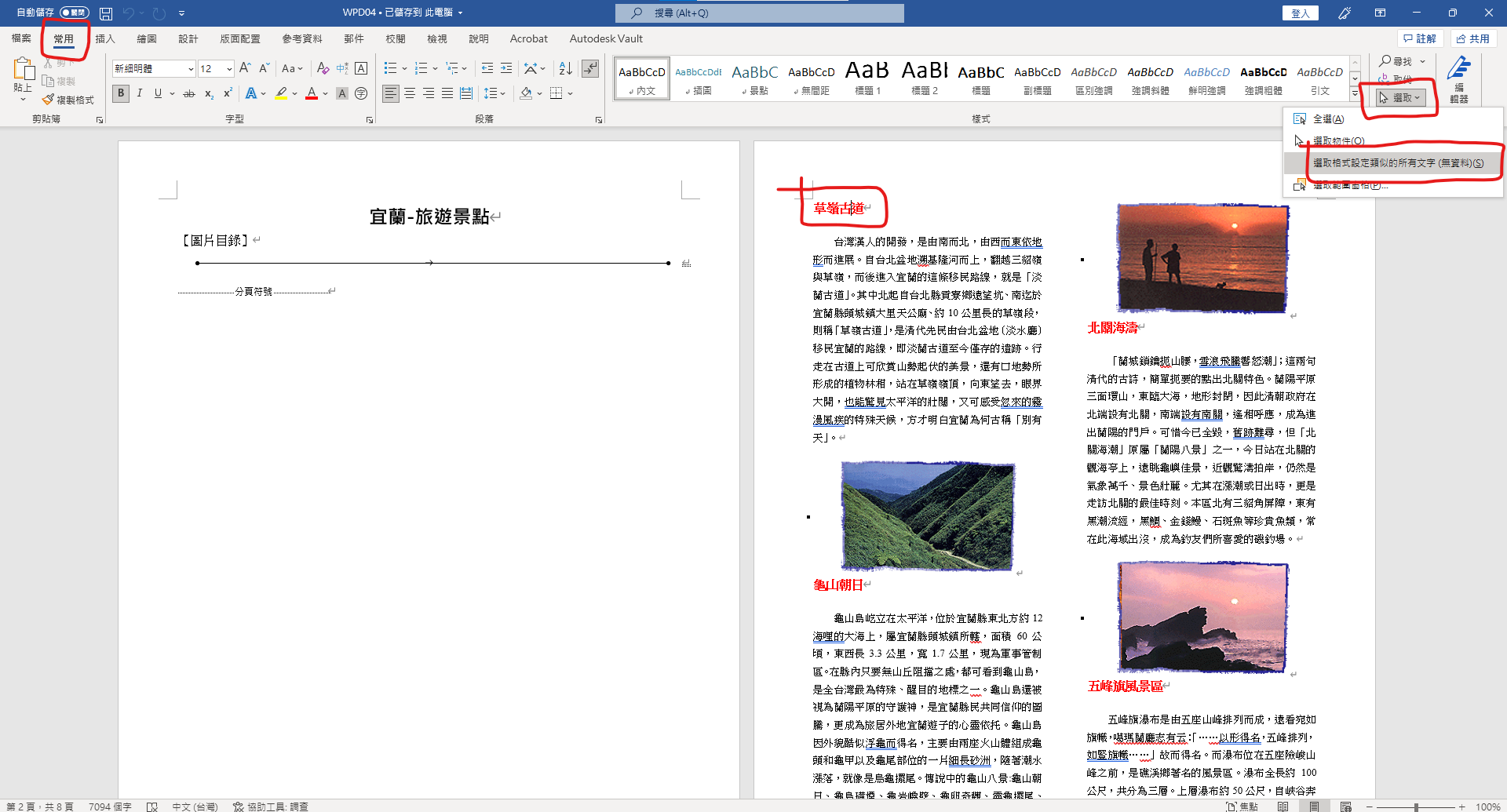
套用景點樣式(左鍵)
並修改(右鍵)
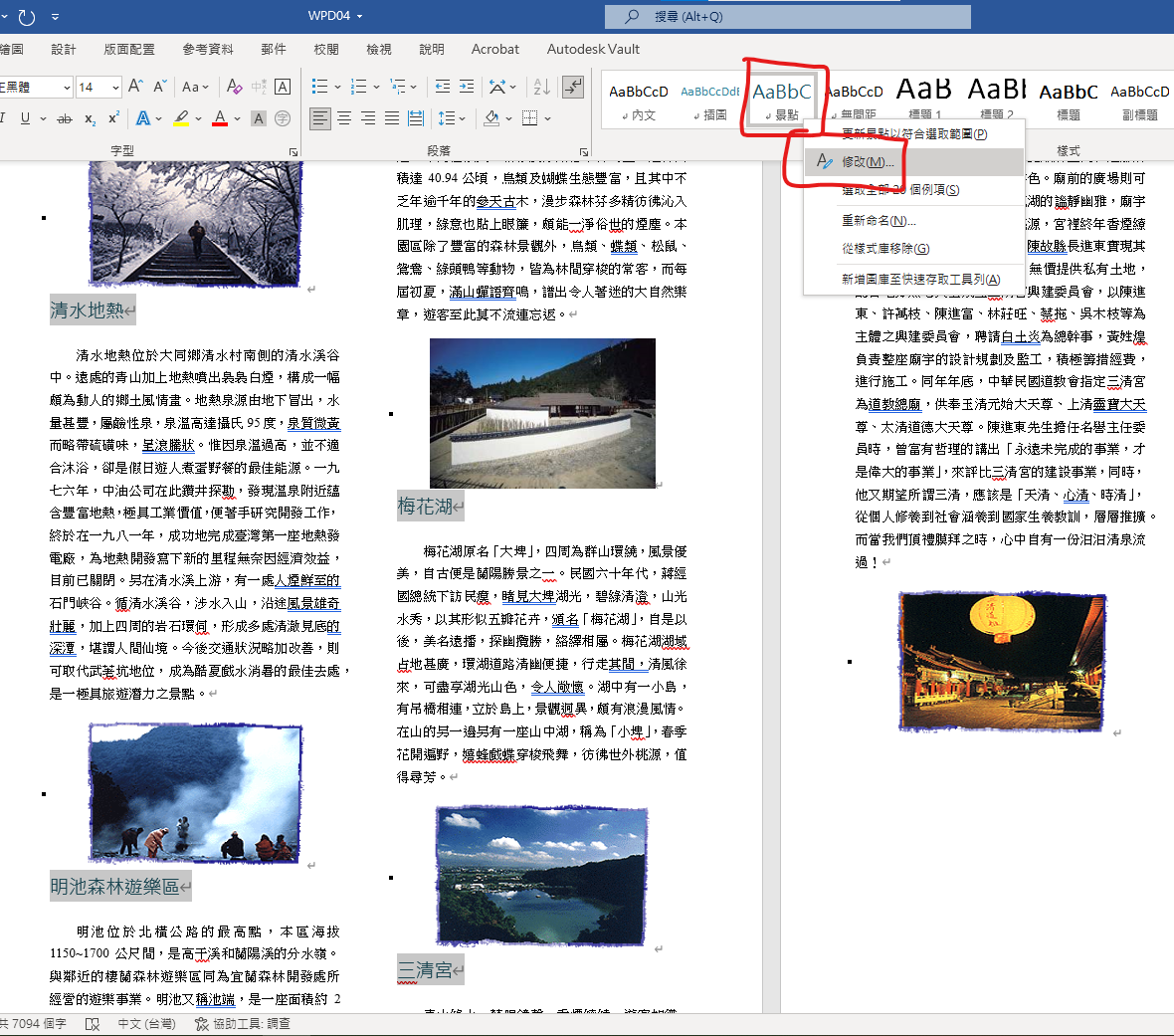
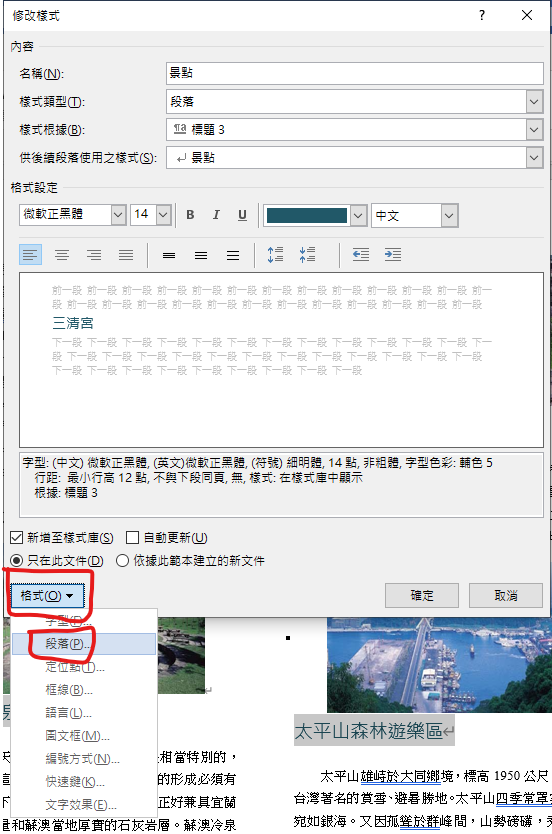
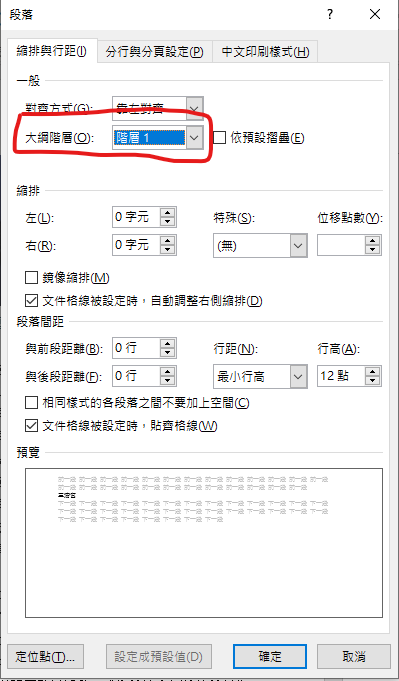
設為: 階層1
檢視 > 大綱模式
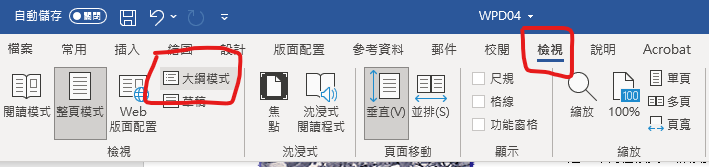
只顯示階層1
取消選取再
重選一次
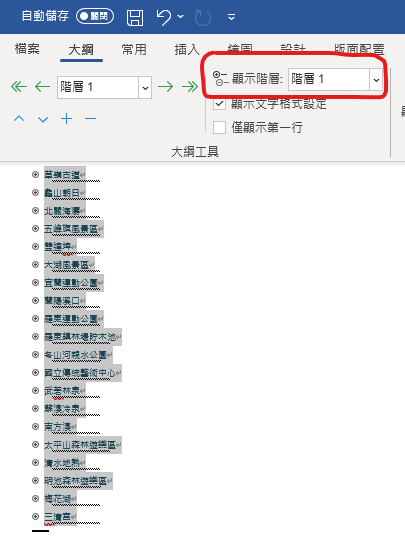
常用>排序 :
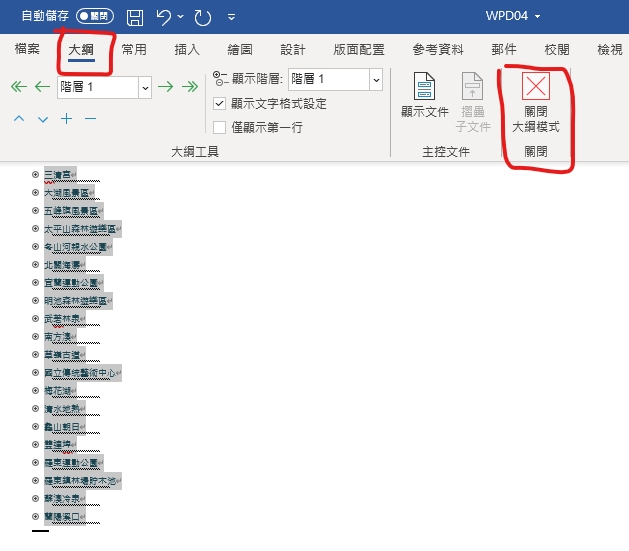
關閉大綱模式
選取到圖片
右鍵 > 插入標號
新增標籤: 照片
補一個全形的冒號 :(Ctrl + shift + : )
項目之下
鼠標移到照片1:
之後
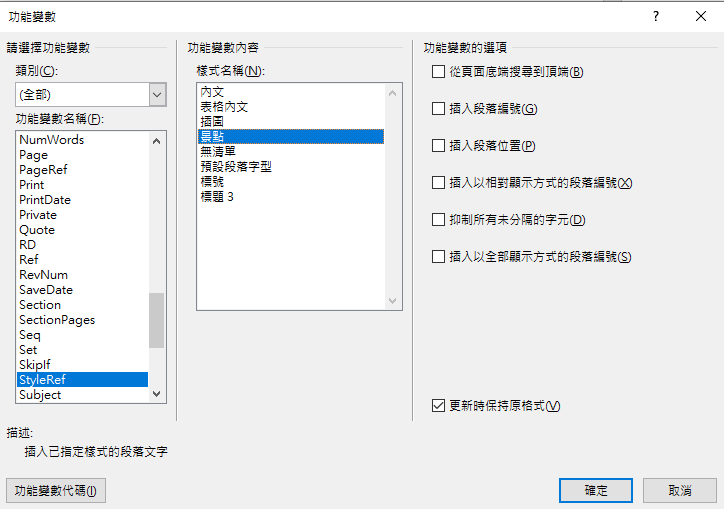
插入 > 快速組件 > 功能變數
StyleRef > 景點
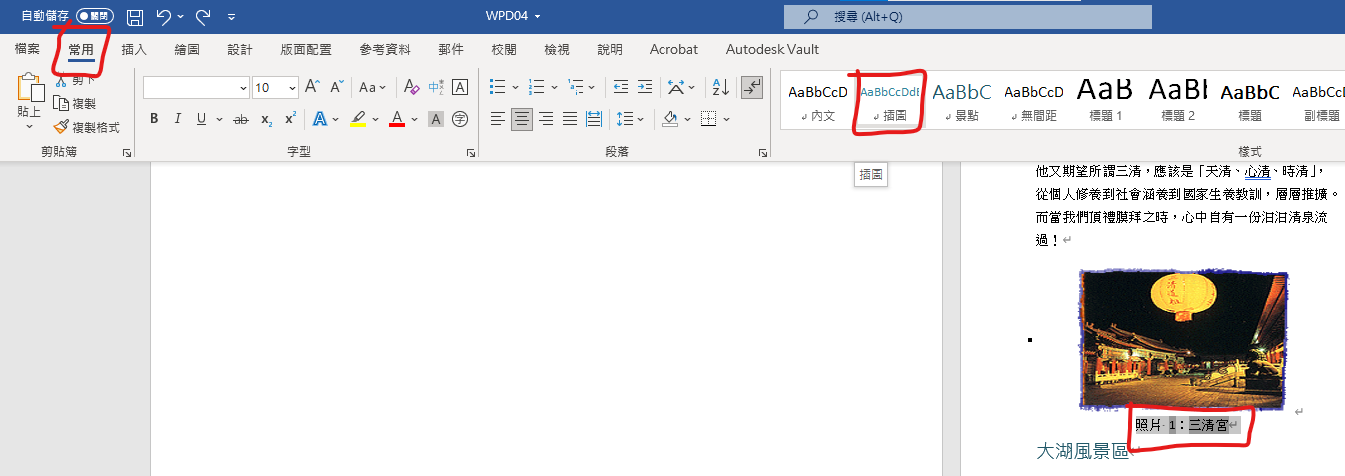
照片下方出現
照片1: 三清宮

滑鼠選取
照片1: 三清宮
套用插圖樣式(跟圖片樣式相同)
Alt+滑鼠左鍵選
照片1: 三清宮 (不選到段落符號)
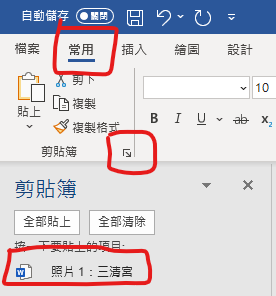
複製
可以打開剪貼簿,確認複製成功:
鼠標放在三清宮之後
Ctrl + H (尋找取代)
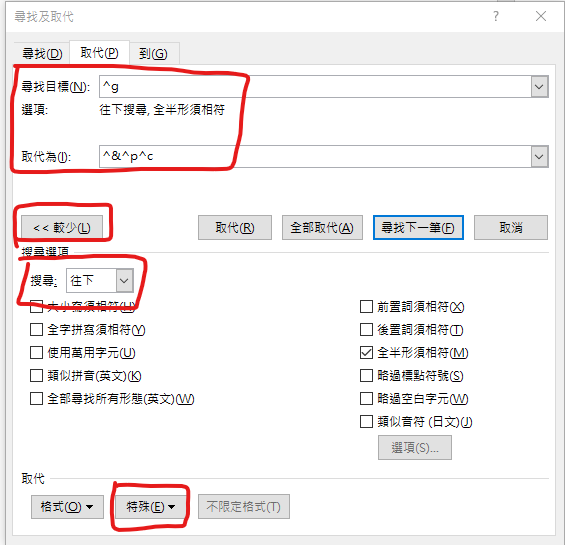
搜尋: 往下(三清宮才不會重複)
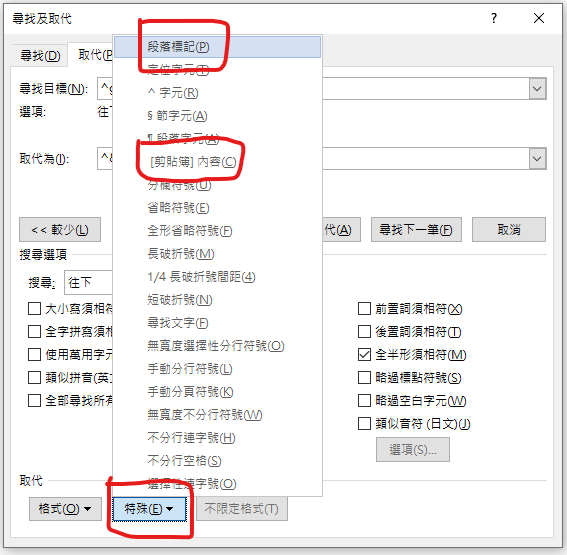
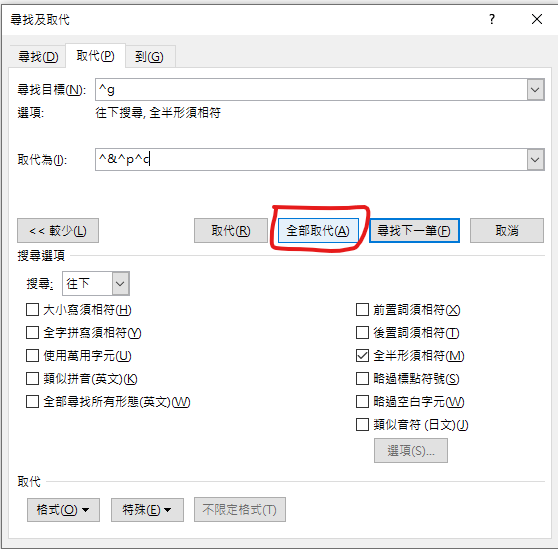
尋找目標: ^g
是從特殊 > 圖形
取代為:
^& (自行輸入,叫word停頓一下,
搜尋到的圖片會被保留)
^p (特殊 > 段落標記)
^c (特殊>剪貼簿內容)
全部取代:
搜尋到0的話,點是 (重新搜尋)
搜尋到19的話,點否(不重新搜尋)
Ctrl + A 全選
F9 更新
題目說
第一頁:無頁碼
鼠標一定要移到第一頁
第一頁不同
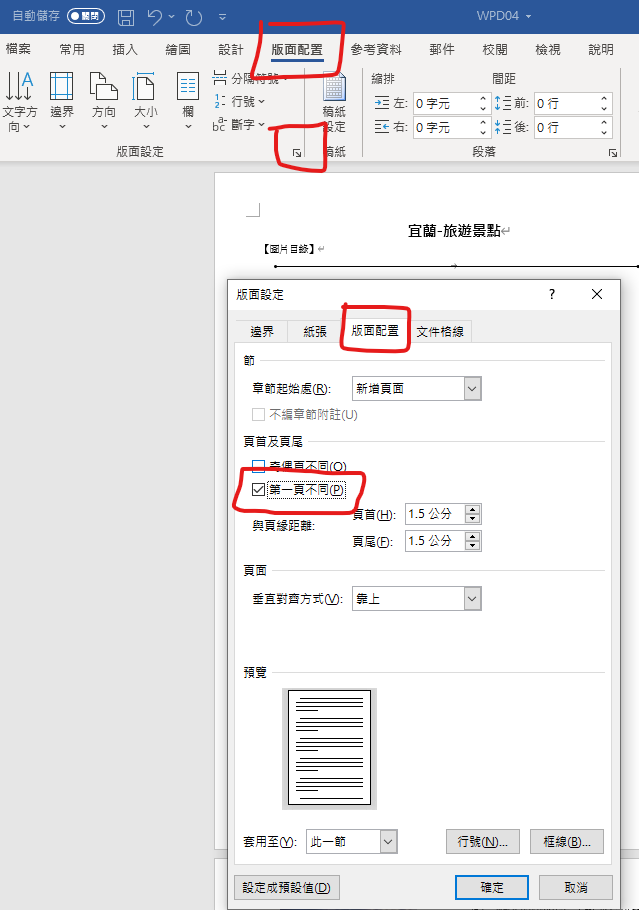
在第二頁的頁尾點兩下
進入頁首及頁尾模式
頁碼>目前位置>馬賽克
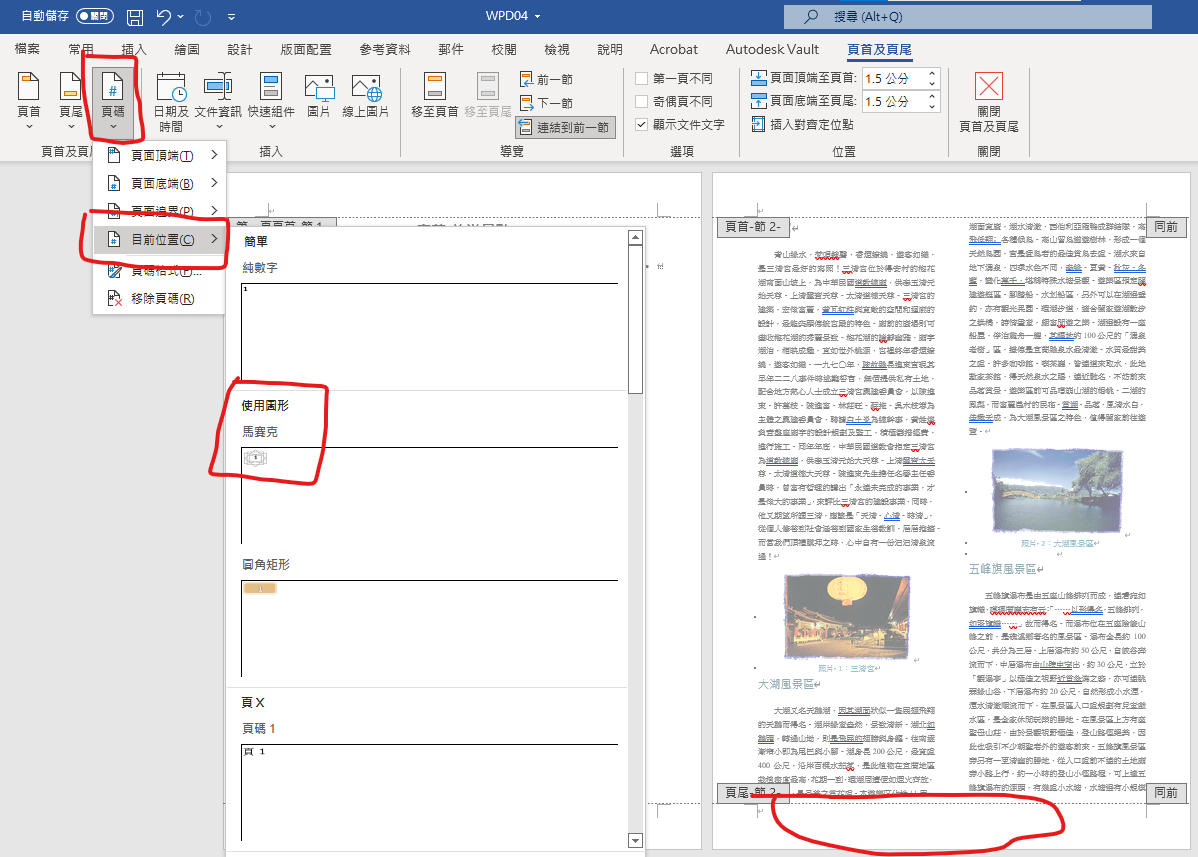
常用 > 置中
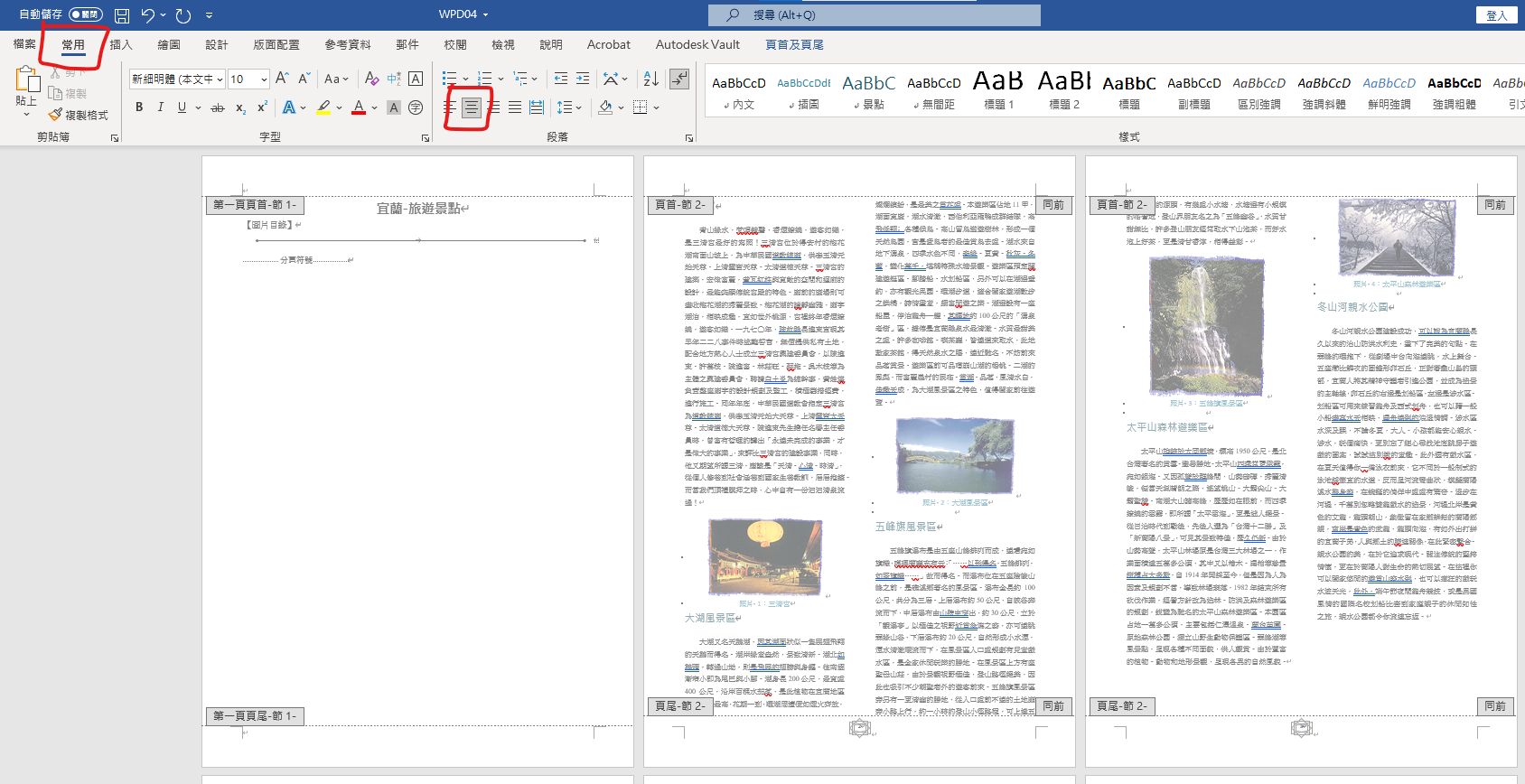
在第一頁點兩下
離開頁首頁尾模式
鼠標移到
第一頁水平線右側段落標記前
參考資料>插入圖表目錄
第4步: 標題標籤:照片
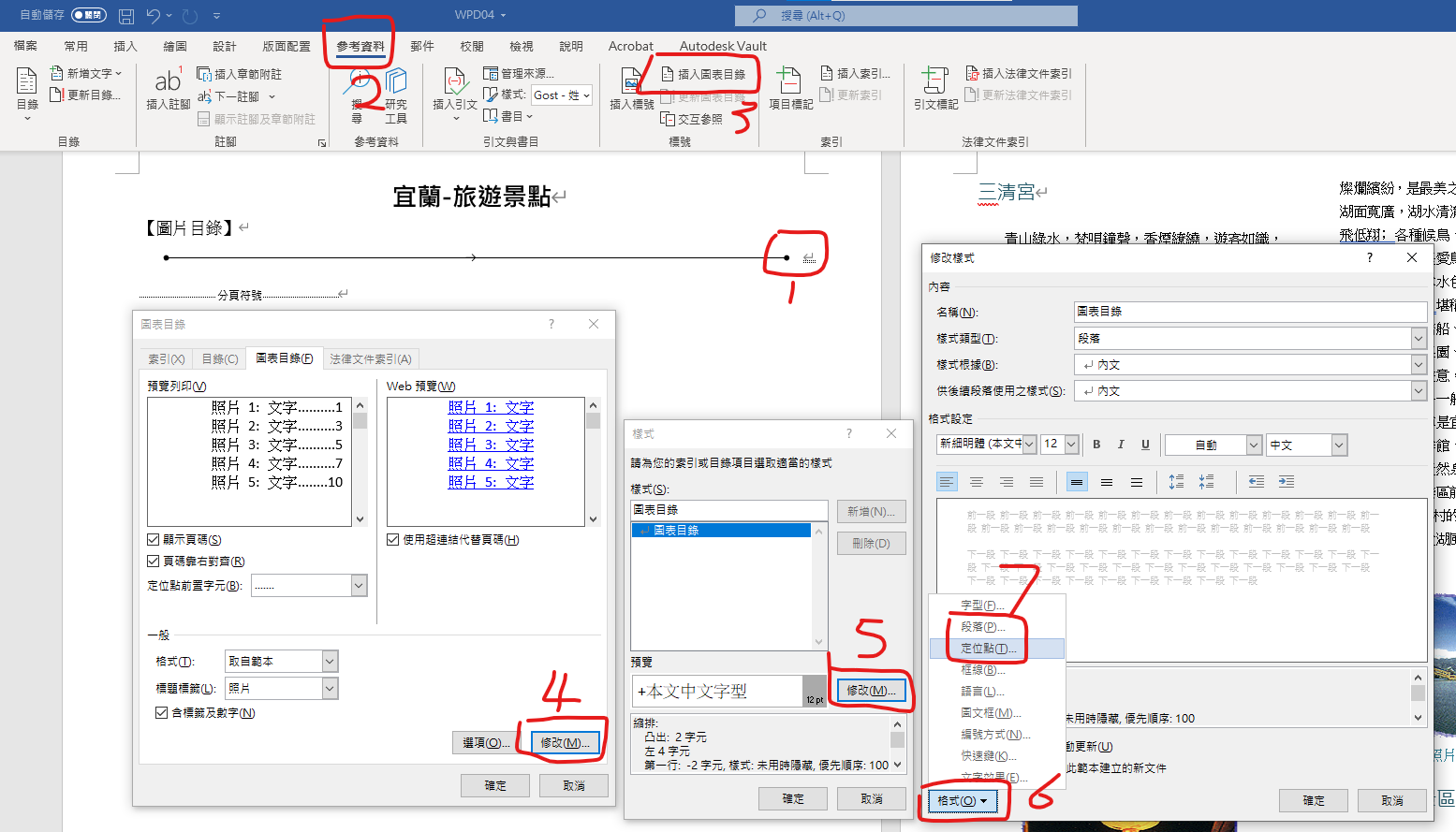
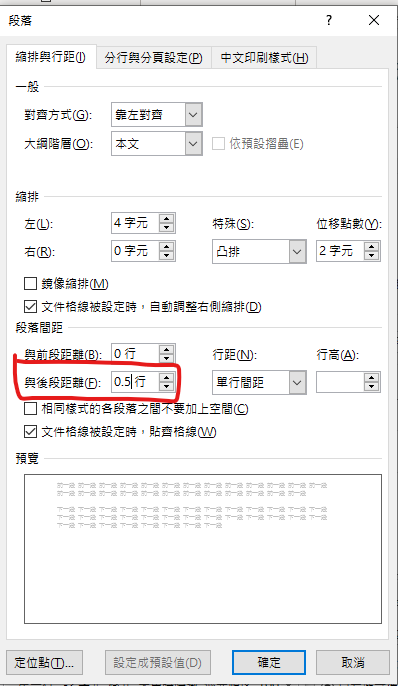
段落
與後段距離0.5行
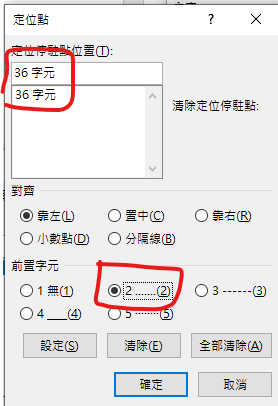
定位點
36字元
前置字元2
連按好幾個確定
最後結果:

F12另存新檔
WPA04.docx
本次評分題號:WORD 2016 第 404 題
評分日期:2022/3/18 下午 05:25:13
第1題:設定正確,得12分
第2題:設定正確,得3分
第3-A題:設定正確,得2分
第3-B題:設定正確,得3分
本題原始配分:20,實得總分為20
本次評分題號:WORD 2016 第 404 題
評分日期:2022/3/19 上午 10:40:27
第1題:設定正確,得12分
第2題:設定正確,得3分
第3-A題:設定正確,得2分
第3-B題:設定正確,得3分
本題原始配分:20,實得總分為20
 vs 深拷貝(deep copy),什麼時候需要用深拷貝? import copy ; b = copy.deepcopy(a)")
的參數axis=0 / 1 vs index / columns ; 如何drop DataFrame的rows / columns ?")

 ; self.process_button.pack(fill=’both’, expand=True) ; 物件導向避免使用全域變數")
 正向先行 ; (?!pattern) 負向先行 ; (?<=pattern) 正向回顧 ; (?<!pattern) 負向回顧 ; (? 往後(右)看 ; (?< 往前(左)看 ; =必須符合 ; !不可符合")
 ; 如何將資料夾中的多個csv檔求平均?")

 ; 如何處理unicode?")


近期留言