code:
# -*- coding: utf-8 -*-
"""
Created on Mon Nov 20 14:30:55 2023
@author: SavingKing
"""
sample_dict = {
"name": "Alice",
"age": 30,
"city": "Wonderland"
}
import json
# 直接将字典序列化到文件
with open("output_with_dump.json", "w") as file:
json.dump(sample_dict, file, indent=4)
# 先将字典序列化为字符串,然后写入文件
json_str = json.dumps(sample_dict, indent=4)
with open("output_with_dumps.json", "w") as file:
file.write(json_str)code & 輸出結果:
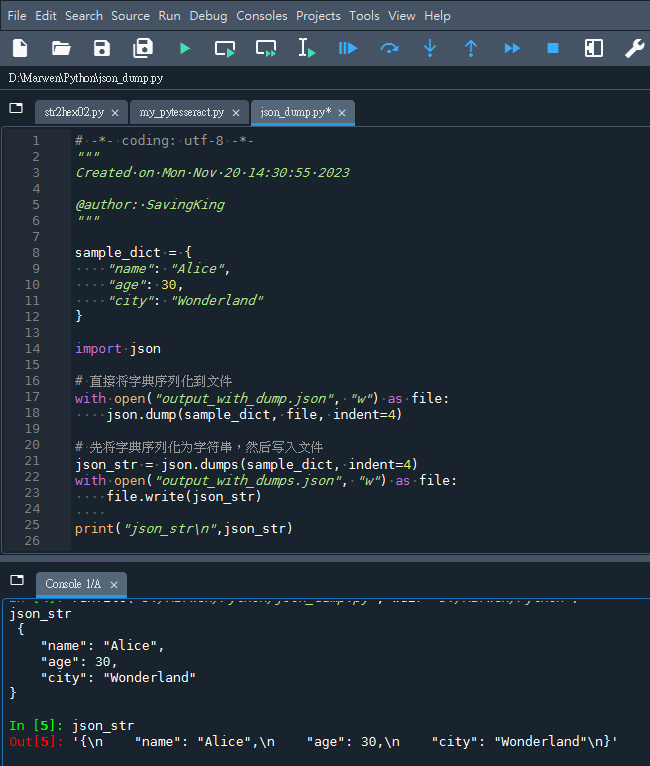
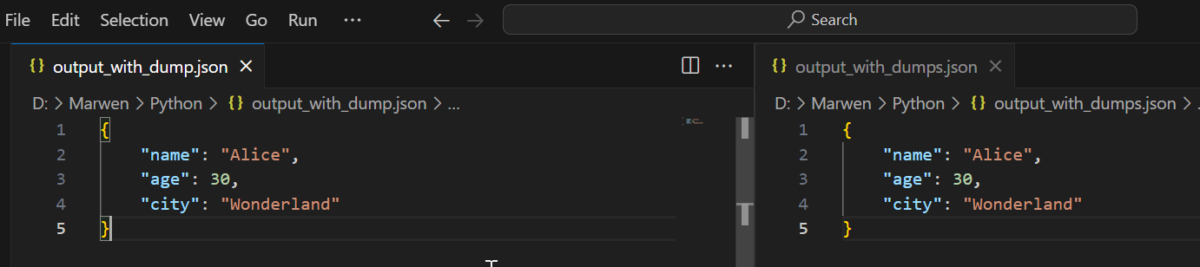
两个文件 output_with_dump.json 和 output_with_dumps.json 将包含相同的JSON内容,但是生成这些文件的过程不同。json.dump() 是一步到位的方法,直接将对象写入文件;而json.dumps() 则是一个两步的过程,先创建字符串,然后将其写入文件。在结果上,两者是等效的:
推薦hahow線上學習python: https://igrape.net/30afN



; dict(key)提取dict內的元素; importlib.reload(); np.zeros(); np.array()")
![Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc=’upper left’, bbox_to_anchor=(6/10, 3/5)](https://i0.wp.com/savingking.com.tw/wp-content/uploads/2023/05/20230502163945_79.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc=’upper left’, bbox_to_anchor=(6/10, 3/5)")
")
 ]*>.*?底下插入一個圖檔.*?</w:p>’, flags = re.DOTALL) ; new_xml, n = pattern.subn(”, xml, count=1)' title='Python正則替換:全面掌握 re.sub 與 re.subn 的差異與實戰 #substitute(替換); . 預設匹配「除\n以外的任意單一字元」; pattern = re.compile(r'<w:p[^>]*>.*?底下插入一個圖檔.*?</w:p>’, flags = re.DOTALL) ; new_xml, n = pattern.subn(”, xml, count=1)' loading='lazy' width=350 height=233 />
]*>.*?底下插入一個圖檔.*?</w:p>’, flags = re.DOTALL) ; new_xml, n = pattern.subn(”, xml, count=1)' title='Python正則替換:全面掌握 re.sub 與 re.subn 的差異與實戰 #substitute(替換); . 預設匹配「除\n以外的任意單一字元」; pattern = re.compile(r'<w:p[^>]*>.*?底下插入一個圖檔.*?</w:p>’, flags = re.DOTALL) ; new_xml, n = pattern.subn(”, xml, count=1)' loading='lazy' width=350 height=233 /> 內聯修飾符 vs re.I 全域標記,打造無情的「激進截斷」割草機! `(?i)`、`flags=re.I`、`(?i:…)` 的差別")



近期留言