csv檔請參考前篇:
用 is np.nan 做判斷式
本篇改用isna()重做
DataFrame.drop(labels=None, *, axis=0,
index=None, columns=None,
level=None, inplace=False, errors=’raise’)
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/12/20221206184635_4.png)
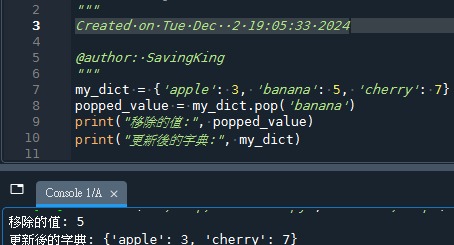
fpath = r”C:\antenna_AMS\21046\emt2csv\01\01test.csv”
import pandas as pd
df_raw = pd.read_csv(fpath,header=None)
boolLst= list( pd.isna( df_raw[0] ) )
print(boolLst)
boolLst1 =pd.isna( df_raw[0] ).tolist()
print(boolLst1) #5,8列同效
#df_raw[0]只要一個[],若使用[[]],
#外觀一樣但型態會變成DataFrame
#tolist()會失敗,list()也會變成[0]
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/12/20221206190216_50.png)
#df_raw[0]: 14列,第4,9列為NaN
nanIdx = []
for i in range(len(boolLst)):
if boolLst[i] == True: nanIdx.append(i)
print(“NaN index:”,nanIdx)
df_drop0 = df_raw.drop(nanIdx,axis=0)
#df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True)
#reset_index(drop=True) ,
#可以重置index,並將原index刪除
print(df_drop0)
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/12/20221206185348_86.png)
輸出結果:
![Python: pandas.DataFrame如何移除所有空白列?pandas.isna( df_raw[0] ).tolist() ; df_drop0 = df_raw.drop(nanIdx,axis=0).reset_index(drop=True) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/12/20221206185455_72.png)
推薦hahow線上學習python: https://igrape.net/30afN

![Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2026/04/20260430085117_0_0beced.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 正規表達式教學:看懂 re.split()、\W|_ 與 flags=re.ASCII # \w代表 word character ~ [A-Za-z0-9_]")
,類別(Class), 物件(Object), 屬性(Attribute)=變數, 方法(Method)=函式, 建構式(Constructor) def __init__(self,x,y): 計算計程車車資, assert 斷言, 全域變數與區域變數")
![Python Logging 完全指南:從基礎到實戰應用; import logging ; logging.basicConfig(level=logging.INFO, handlers=[ logging.StreamHandler(), logging.FileHandler(‘app.log’, mode=’a’, encoding=’utf-8′)] ) ; inspect.currentframe().f_code.co_name #動態取得funcName](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2025/10/20251021155823_0_c16012.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python Logging 完全指南:從基礎到實戰應用; import logging ; logging.basicConfig(level=logging.INFO, handlers=[ logging.StreamHandler(), logging.FileHandler(‘app.log’, mode=’a’, encoding=’utf-8′)] ) ; inspect.currentframe().f_code.co_name #動態取得funcName")
: stack() ; unstack() #可用idxmax()求最大值的index/columns ; groupby().mean().reset_index() ; pivot() ; pivot_table( aggfunc = np.mean ) ; set_index() ; pivot_table = groupby + pivot #pivot_table() 有aggfunc參數,所以索引組合可以重複,pivot則無此參數,若有重複的索引組合,需要先用groupby().mean()")


 或 ary1 @ ary2 或 numpy.dot (ary1, ary2)")
 ; Visual Studio Code(VScode)為什麼會出現錯誤 module ‘csv’ has no attribute ‘reader’ ?")
![Python: pandas.read_excel(r"路徑檔名.副檔名", header = None), 自動加上0,1...的欄標籤, DataFrame如何取某一直欄或橫列? 如何用 .iloc[bool_list] 取出判斷式為真的那一列? bool_list = list( df[0] == 0 ) ; bool_list = list(df[0].isin([0])) ; DataFrame如何顯示完整的資料? pandas.set_option ( "display.max_rows", None) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/11/20221128164005_44-520x245.png)

近期留言