- order順序:
name = "Alice"
age = 25
formatted_string = "My name is {}, and I'm {} years old.".format(name, age)
print(formatted_string)輸出:
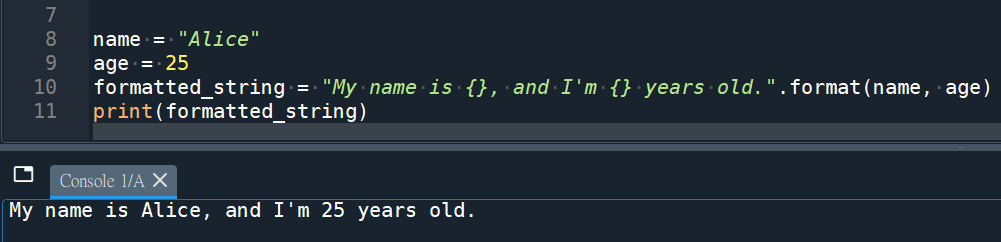
在格式化字符串中使用占位符 {},按照传递给.format()方法的参数顺序依次替换占位符。
- keyword關鍵字
name = "Bob"
age = 30
formatted_string = "My name is {name}, and I'm {age} years old.".format(name=name, age=age)
print(formatted_string)輸出:
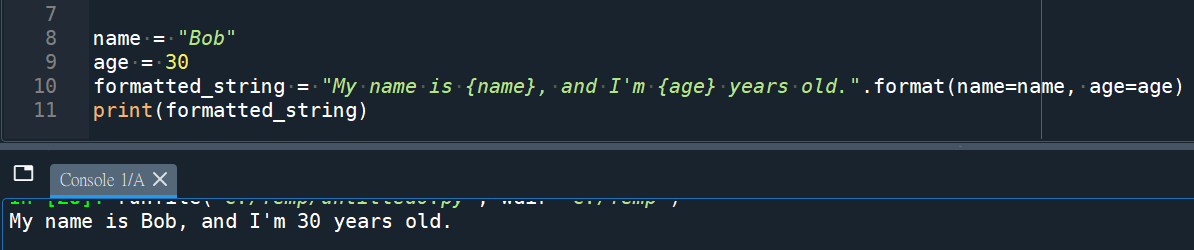
在格式化字符串中使用命名的占位符 {name} 和 {age},并使用关键字参数 name=name 和 age=age 来指定要替换的值。
.format(name=name, age=age)
使用關鍵字不要忘記
name=name, age=age
(賦值給關鍵字)
順序不需要
3. index 索引方法
name = "Charlie"
age = 35
formatted_string = "My name is {0}, and I'm {1} years old.".format(name, age)
print(formatted_string)輸出:

推薦hahow線上學習python: https://igrape.net/30afN
使用順序
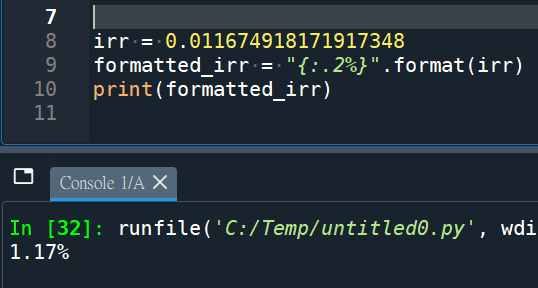
:.2%表示将数值格式化为百分比形式,并保留两位小数。
使用關鍵字:
前綴f:
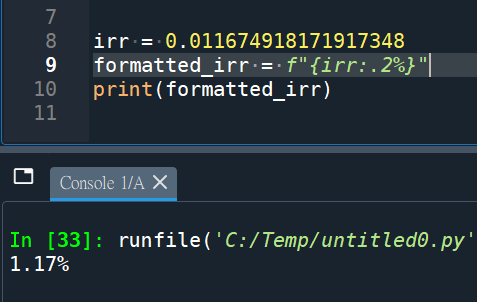
推薦hahow線上學習python: https://igrape.net/30afN
 ; from sklearn.tree import DecisionTreeClassifier ; tree = DecisionTreeClassifier(criterion = “gini”) #criterion = “entropy” #criterion: 標準,準則")
 ; cc.convert(“不仅内存不够,而且服务器挂了”)")
 ; plt.subplots_adjust( hspace=1 ) 調整子圖間的間距")

 : from openai import OpenAI ; client = OpenAI (api_key = api_key) ; response = client .audio .speech .create( model= “tts-1-hd”, input= text_content, response_format= “mp3”)")
函式切片出兩個 pandas.Series 重複的元素? ser_bool = 長的Series.isin (短的Series); numpy.bool_ ; WR75 WR42 WR28頻段為何?")




近期留言