import numpy as np
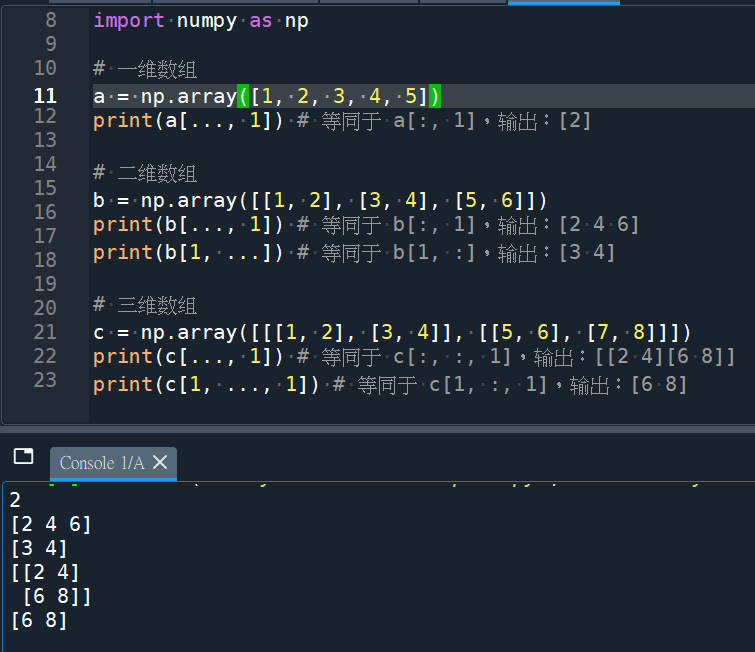
# 一维数组
a = np.array([1, 2, 3, 4, 5])
print(a[..., 1]) # 等同于 a[1],输出:2
# 二维数组
b = np.array([[1, 2], [3, 4], [5, 6]])
print(b[..., 1]) # 等同于 b[:, 1],输出:[2 4 6]
print(b[1, ...]) # 等同于 b[1, :],输出:[3 4]
# 三维数组
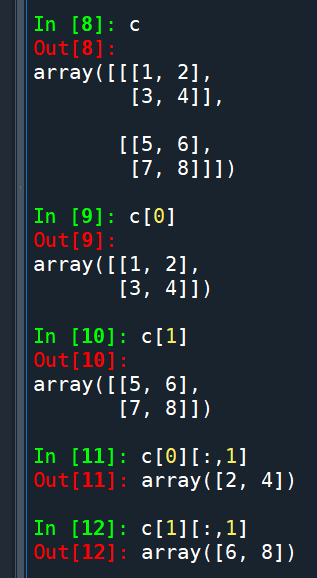
c = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print(c[..., 1]) # 等同于 c[:, :, 1],输出:[[2 4][6 8]]
print(c[1, ..., 1]) # 等同于 c[1, :, 1],输出:[6 8]
print(c[…, 1]) # 等同于 c[:, :, 1],输出:[[2 4][6 8]]:
推薦hahow線上學習python: https://igrape.net/30afN

位置? ax.legend( bbox_to_anchor = (1, 1), borderaxespad=0)")
 ; cc.convert(“不仅内存不够,而且服务器挂了”)")



 一次求得計數(count), 均值(mean), 標準差(std), max, min, 中位數, 1/4位數, 3/4位數")
 vs 非貪婪 (Lazy) ; .* vs .*?")
,列高不同之下拉設定")
![Python: 如何使用numpy.newaxis 增加資料的維度? y = x[:, np.newaxis] - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/03/20230313184351_57-483x245.png)


近期留言