點此或下圖可以連結FB討論串
以下為富邦人壽
富貴長紅(PAA)分紅終身壽險(台幣躉繳)的建議書:
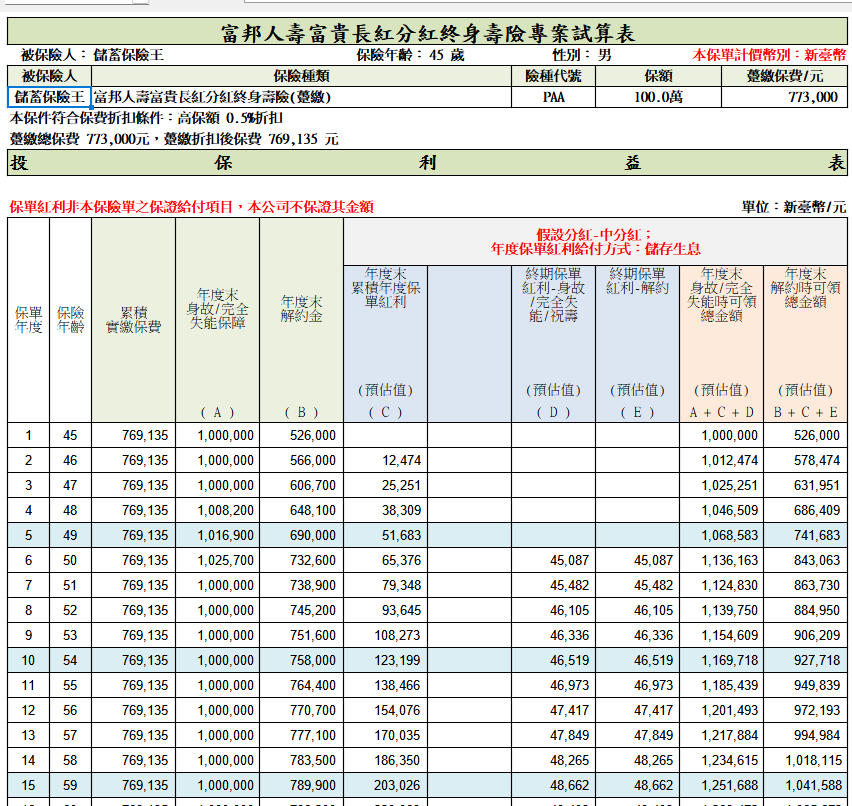
計算IRR的Python code置於文末
輸出的xlsx:
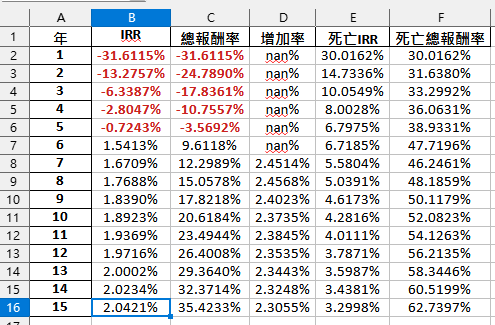
不討論富邦的分紅達成率如何了
先假設達成率100%
(有可能高估了富邦的能力)
五年內解約皆為負報酬
6年IRR 1.54%
13年IRR 2%
15年IRR 2.04%
幾乎沒有提升
參考儲蓄保險王
常用的一些數位銀行
一銀iLeo: https://lihi2.com/kswBm/blog
12萬以內享有活存利率2%
華銀SnY: https://lihi1.com/KComt/blog
10萬以內享有活存利率2.3%
遠銀Bankee: https://lihi1.com/dt1yL/blog
5萬以內享有活存利率2.6%
以低標的一銀iLeo 2%來看
富貴長紅12年IRR都輸活存
以華銀SnY 2.3%來看
富貴長紅15年IRR都輸活存
以儲蓄險的角度來看
可說完全不及格
15年都無法勝活存
8.7分不能再高了
(滿分為1000分)
如果看完這種8.7分的IRR
您仍因為死亡IRR最高30%
而願意購買
儲蓄保險王絕對不會攔阻你
請在此谷歌表單留下聯繫資料:
https://forms.gle/6hPmWBUVyvS9GDxH9
請保經朋友幫你服務,
並感謝你的大方
本文不論解約還是死亡IRR
都算得清清楚楚,
依據金管會的標準
這涉及不當行銷
商品應該要下架
麻煩金管會趕快將這張
富邦的分紅保單下架
歡迎檢舉到金管會
#金管會吃屎!
也歡迎富邦業務員來打臉,
富邦那張儲蓄型保單
IRR可以超越5%?
才不像版主所述
張張都很弱
貼出建議書,
本站將代為免費廣告
保誠多重宇宙: 香港保單
保誠 雋富多元貨幣計劃IRR分析
同樣叫做保誠人壽
香港保誠有IRR超過5%的實力
台灣保誠愛美鑫IRR才4%
因金管會把國人當成次等公民
便以分紅公式太複雜的奇怪理由
強迫下架,
成為僅開賣16天的短命保單
之後若有新商品,
必然IRR更低
才符合金管會的心意
台灣與香港猶如多重宇宙
保誠愛美鑫下架同時
霉體妓者還大讚富邦分紅公式簡單清楚:
相較富邦人壽,在外幣分紅終身壽險保單條款附件的「分紅公式」就明白列出;年度保單紅利是利差加上死差的紅利,調整為可分配金額後再乘上分配給要保人的比例,終期保單紅利則是以資產額份為基礎,各項計算參數講得相對清楚。
這不是不當行銷的話
什麼才是不當行銷?
分紅公式是消費者關心的嗎?
我只關心分紅達成率能不能100%
IRR多少?
我管分紅怎麼算的幹嘛?
富邦分紅保單15年IRR仍輸活存
才是需要關注的重點吧?
看完這種8.7分的IRR
本來也是一笑置之
連文章都懶得寫
不過據說計算保單的IRR
涉及不當行銷
商品需要下架
現在要以踢爆黑心貨的角度
計算所有台灣黑心保單的IRR
直至官方建議書列出IRR
或者黑心商品都下架光為止
這種8.7分的黑心商品
請大家千萬不要上當
建議參考海外保單
金管會有本事就叫
香港保誠或忠意保險下架啊!
#金管會吃屎!
#香港保誠雋富多元貨幣計劃: https://lihi2.com/LVlHg/blog
#忠意保險跨越創富保2(五年期繳): https://lihi2.com/iQTrf/blog
#忠意保險跨越創富保2(二年期繳): https://lihi2.com/qvFk6/blog
推薦hahow線上學習python: https://igrape.net/30afN
Python code:
# -*- coding: utf-8 -*-
"""
Created on Tue May 23 18:57:45 2023
@author: SavingKing
03:
j,k合為同一個迴圈(死亡IRR),且使用enumerate
df使用"年"當index,以免cash_value,death_insurance
資料的年度不一致,還可以正確合併
04:
修正未滿期時的總報酬率計算錯誤
05:
模組化,刪除已經註解的保誠資料,__file__擷取當前py檔路徑
輸出的xlsx檔名,可以跟py檔 主檔名相同
05_1:
原始資料為xlsx檔,看不到列數,無法正確skiprows, skipfooter
"""
import numpy_financial as npf
import numpy as np
import pandas as pd
import os
# =============================================================================
# folder = r"P:\Python\financial\富邦\PAA-富貴長紅"
# basename = "PAA-富貴長紅專案試算表V1.4-1120825-保經代_45歲男.xlsx"
# fpath = os.path.join( folder, basename)
# dfRaw = pd.read_excel(fpath,sheet_name="列印頁",skiprows=16)
# =============================================================================
# =============================================================================
# survival_insurance:list=[109, 326, 651, 1085, 1627,
# 2277, 3075, 3873, 4671, 5469,
# 6267, 7065, 7863, 8661, 9459,
# 10257, 11055, 11853, 12651, 13449]
# =============================================================================
#若無還本金設計:
survival_insurance:list=[0]*15
ary_survival_insurance = np.array(survival_insurance)
cash_value:list=[526000, 578474, 631951, 686409, 741683,
843063, 863730, 884950, 906209, 927718,
949839, 972193, 994984,1018115, 1041588]
# 78695, 81076, 83524, 86052, 88651]
ary_cash_value = np.array(cash_value)
cash_value = list( ary_cash_value + ary_survival_insurance)
# cash_value:list=[5244+109, 12125+326, 19265+651, 26726+1085, 34475+1627,
# 56483+2277, 59969+3075, 61913+3873, 63889+4671, 65840+5469,
# 67809+6267, 69854+7065, 71968+7863, 74147+8661, 76387+9459,
# 78695+10257, 81076+11055, 83524+11853, 86052+12651, 88651+13449]
##上述寫法,cash_value加一次,death_insurance又要再加一次,因此使用np.array
#富邦人壽美年紅旺PPC #1~20年末解約金(上),死亡保額(下)
death_insurance:list=[1000000, 1012474, 1025251, 1046509, 1068583,
1136163, 1124830, 1139750, 1154609, 1169718,
1185439, 1201493, 1217884, 1234615, 1251688]
# 100742,103147,105618,108168,110790]
ary_death_insurance = np.array(death_insurance)
death_insurance = list(ary_death_insurance + ary_survival_insurance)
capital_protection = 6 #6年末保本
discount = (0)/100
# 2% 花旗,星展,華南
# 樂天10萬回饋2500(2.5%)
# 遠銀百萬保費3.5%
pay:float = -769135* (1-discount) #-60570 #-59358.6
n_years = 1
def get_increasing_rate(capital_protection=capital_protection,
cash_value=cash_value,fmt_str=True):
increasing_rate = [np.nan]*capital_protection
#從保本才開始算解約金增加率
for i in range(capital_protection, len(cash_value)):
increase = cash_value[i]/cash_value[i-1]-1
increasing_rate.append(increase)
if fmt_str == True:
increasing_rate = [f"{ele:.4%}" for ele in increasing_rate]
return increasing_rate #list
increasing_rate = \
get_increasing_rate(capital_protection=capital_protection,
cash_value=cash_value)
def get_lisIRR_totReturn(pay=pay, discount=discount,
n_years=n_years,
cash_value=cash_value, start=1,
fmt_str=True):
lisIRR = []
totReturn = []
for i, value in enumerate(cash_value, start-1):
if i < n_years: #i=0,1,2
lis_pay=[pay]*(i+1)
cash_flow = lis_pay+[value]
tot = sum(cash_flow)/abs(sum( lis_pay ) )
else:
lis_pay=[pay]*n_years
lis0 = [0]*(i-n_years+1)
cash_flow = lis_pay+lis0+[value]
tot = sum(cash_flow)/abs(sum( lis_pay ))
print(f"第{i+1:02d}年末cashflow:",cash_flow)
irr = npf.irr(cash_flow)
lisIRR.append(irr)
totReturn.append(tot)
if fmt_str == True:
lisIRR = [f"{ele:.4%}" for ele in lisIRR]
totReturn = [f"{ele:.4%}" for ele in totReturn]
return lisIRR,totReturn #list
#return的縮排不要在for迴圈之內,不然lisIRR只會有一個元素
lisIRR,totReturn = get_lisIRR_totReturn(pay=pay,discount=discount,
n_years=n_years,
cash_value=cash_value,start=1)
# print("lisIRR:",lisIRR)
lisIRR_death,totReturn_death = \
get_lisIRR_totReturn(pay=pay,discount=discount,
n_years=n_years,
cash_value=death_insurance,start=1)
# =============================================================================
##lisIRR_death 要重複使用function get_lisIRR_totReturn
# lisIRR_death = []
# for i, value in enumerate(death_insurance, 0):
# if i < n_years: #i=0,1,2
# cash_flow = [pay]*(i+1)+[death_insurance[i]]
# else:
# lis0 = [0]*(i-n_years+1)
# cash_flow = [pay]*n_years+lis0+[value]
# print(f"第{i+1:02d}年末死亡cashflow:",cash_flow)
# irr = npf.irr(cash_flow)
# lisIRR_death.append(irr)
#
#
# for m,irr in enumerate(lisIRR_death,1):
# print(f"第{m:02d}年末({m+40}歲)死亡IRR:\t{irr:.4%}")
# =============================================================================
# lisIRR_death = [f"{irr:.4%}" for irr in lisIRR_death]
dic={"死亡IRR":lisIRR_death ,"死亡總報酬率":totReturn_death,
"年": list(range(1,len(death_insurance)+1))}
dfIRR_death = pd.DataFrame(dic).set_index("年")
#以"年"當index,以免cash_value跟death_insurance資料不一致
#這樣合併資料還可以正確
# lisIRR = [f"{irr:.4%}" for irr in lisIRR]
# totReturn = [f"{ele:.4%}" for ele in totReturn]
# increasing_rate = [f"{ele:.4%}" for ele in increasing_rate]
# lisIRR_death = [f"{ele:.4%}" for ele in lisIRR_death]
# lisIRRx2 = [f"{irr:.4%}" for irr in lisIRRx2]
dic = {
"年" : list(range(1, len(cash_value)+1)),
"IRR" : lisIRR,
"總報酬率" : totReturn,
"增加率" : increasing_rate,
}
df = pd.DataFrame(dic).set_index("年")
df_concat = pd.concat([df,dfIRR_death],axis=1)
print("\n",df_concat)
cwd = os.getcwd()
exFolder = os.path.join(cwd,"export")
if not os.path.exists(exFolder):
os.makedirs(exFolder)
# 獲取當前腳本的文件路徑
current_script_path = __file__
#'p:\\python\\financial\\富邦\\pfa-美富紅運30歲6年\\irr_05_富邦人壽美富紅運外幣分紅終身壽險6年.py'
# 提取主檔名
#main_filename = os.path.basename(current_script_path).split('.')[0]
main_filename = os.path.splitext(os.path.basename(current_script_path))[0]
"""
os.path.basename(current_script_path)
Out[21]: 'irr_05_富邦人壽美富紅運外幣分紅終身壽險6年.py'
os.path.splitext(os.path.basename(current_script_path))
Out[20]: ('irr_05_富邦人壽美富紅運外幣分紅終身壽險6年', '.py')
"""
# 打印主檔名
print("\npy主檔名:", main_filename)
xlsx_path = "\\".join( [exFolder,f"{main_filename}.xlsx"] )
df_concat.to_excel(xlsx_path)
print(f"\nxlsx檔已經輸出到:\n{xlsx_path}")
推薦hahow線上學習python: https://igrape.net/30afN
_150717更新")


")
")
_161101")
")
")



近期留言