import re
# 示例字符串,前面故意多四個空白
string = " Hello, world! This is a sample string."
# 示例模式
pattern = r"\b\w{5}\b" # 匹配长度为5的单词
# 使用 re.match()
match_obj = re.match(pattern, string)
if match_obj:
print("Match found:", match_obj.group())
else:
print("No match")
# 使用 re.search()
search_obj = re.search(pattern, string)
if search_obj:
print("First match found:", search_obj.group())
else:
print("No match")
# 使用 re.findall()
matches = re.findall(pattern, string)
if matches:
print("All matches found:", matches)
else:
print("No matches")code:
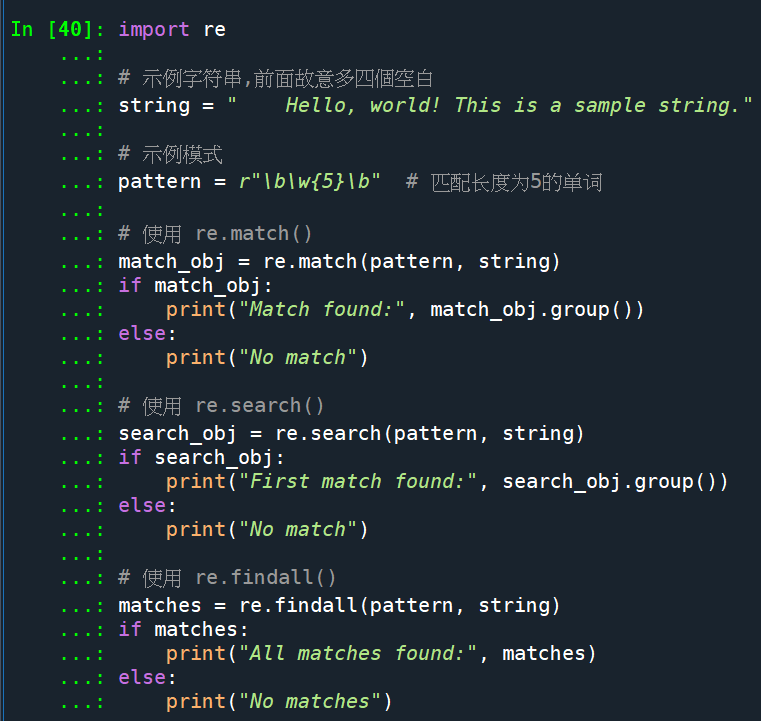
輸出結果:
re.match() 没有匹配到结果,因为它只尝试从字符串的起始位置进行匹配,而模式 r”\b\w{5}\b” 的首个匹配单词 “Hello” 不在字符串的起始位置。
re.search() 匹配到了第一个满足条件的单词 “Hello”,因为它会在整个字符串中搜索并返回第一个匹配结果。
re.findall() 匹配到了所有长度为5的单词,即 “Hello”、”world”。它会返回一个包含所有匹配结果的列表。
这个示例展示了 re.match()、re.search() 和 re.findall() 的不同之处。根据您的需求,您可以选择适当的方法来进行正则表达式的匹配和搜索。
请注意,示例中使用的模式 r”\b\w{5}\b” 是一个简单的示例模式,用于匹配长度为5的单词。您可以根据自己的需求修改模式。
\b 是一个正则表达式的元字符,表示单词边界。它匹配一个单词的开始或结束位置,即一个单词与非单词字符之间的位置。
具体来说,\b 在以下情况下会匹配:
单词的起始位置
单词的结束位置
单词字符与非单词字符之间的位置
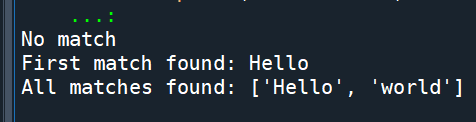
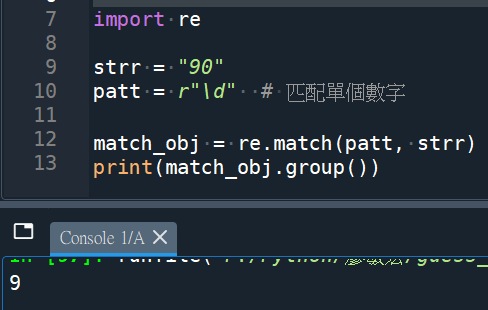
re.fullmatch(patt, strr)
#要fullmatch 0-9的數字,90不match
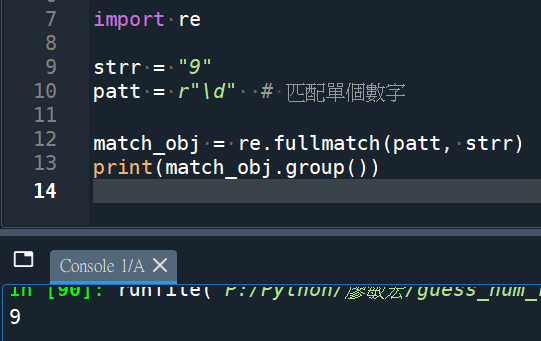
AttributeError: ‘NoneType’ object has no attribute ‘group’
# 90不完整匹配,match_obj 是None,
# None.group()會報錯
match_obj = re.match(patt, strr)
#使用match 會return 9:
推薦hahow線上學習python: https://igrape.net/30afN
‘語意關聯性評分:9分’
如何將以上字串的9分離出來?
1) 三兄弟怎麼選
re.match: 只從字串開頭匹配(像隱含了 ^)
re.search: 掃描整串,找到第一個符合就回傳(最常用)
re.fullmatch: 必須整串都符合(最嚴)
小聯想:match(短、嚴)→ 開頭;search(長、廣)→ 全域掃描;fullmatch → 全串一致
LLM 可能多餘前綴/換行→ 用 re.search 較穩。
2) 正則基本招
原始字串 r”…”:避免跳脫地獄(\s、\d 等不需再多一層跳脫)
常見類別
\d 數字,\s 空白(含空格/Tab/換行/全形空白),\w 英數底線
錨點與旗標
^ 開頭、$ 結尾;re.MULTILINE 讓它們作用於每行
re.IGNORECASE (re.I)、re.DOTALL (re.S,讓 . 吃到換行)、re.VERBOSE (re.X)
群組
捕獲群組 (…)、非捕獲群組 (?:…)、命名群組 (?P…)
3) 貪婪與非貪婪
.* 是貪婪,.? 是非貪婪 解析固定格式時盡量避開「大範圍 .」,用具體模式(如 \d+(?:.\d+)?)
4) 你的實際需求:抓「語意關聯性評分:X分」
建議主模式(支援半形/全形冒號、可有空白、可有小數):
pattern = r”語意關聯性評分[::]\s(\d+(?:.\d+)?)\s分” 說明:
[::]:半形或全形冒號
\s:可選空白 (\d+(?:.\d+)?):整數或小數,捕獲為 group(1) \s分:可能有空白再接「分」
使用 re.search(允許前後雜訊):
m = re.search(pattern, text)
score = float(m.group(1)) if m else None
5) 更耐操的容錯策略
次要備援:只要有「數字+分」就抓
fallback = r”(\d+(?:.\d+)?)\s*分”
範圍限制:把分數夾在 1~10 之間
讓模型更聽話:提示「務必只輸出:語意關聯性評分:X分」,並將 temperature=0
簡潔函式(回傳 float 或 None,不混型別):
先主模式 → 再 fallback → 檢查 1..10 → 失敗回 None
記錄原始 content 方便診斷
範例:
import re
def parse_score(text: str) -> float | None:
main = re.search(r”語意關聯性評分[::]\s(\d+(?:.\d+)?)\s分”, text)
if main: val = float(main.group(1))
return max(1.0, min(10.0, val))
fb = re.search(r”(\d+(?:.\d+)?)\s*分”, text)
if fb:
val = float(fb.group(1))
return max(1.0, min(10.0, val))
return None
實務建議:
只需要整數就改成 (\d+);要小數才用 (?:.\d+)?
小數點要寫\.(前面多一個反斜線\),
別用 .(. 代表「任意字元」)
若要容許逗號或全形點:(?:[.,.]\d+)?
6) 常見坑
沒用 r”…” 導致跳脫錯亂
用 re.match 解析被加了前言的回覆 → 直接失敗
用 . 捕太多,或忘了 . 導致誤匹配
以為 \s 只含空格,實際還包含換行與全形空白
這套就能讓你穩定地從 LLM 輸出抽出分數,遇到浮動格式也能平穩退場。
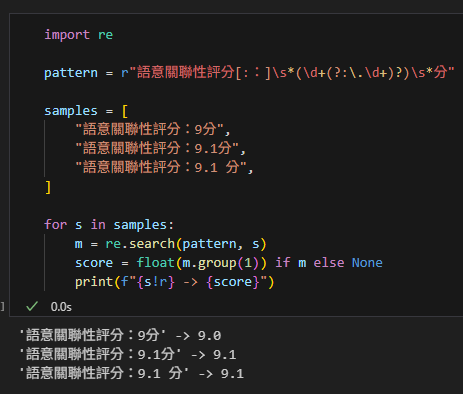
import re
pattern = r"語意關聯性評分[::]\s*(\d+(?:\.\d+)?)\s*分"
samples = [
"語意關聯性評分:9分",
"語意關聯性評分:9.1分",
"語意關聯性評分:9.1 分",
]
for s in samples:
m = re.search(pattern, s)
score = float(m.group(1)) if m else None
print(f"{s!r} -> {score}")輸出:
(\d+(?:\.\d+)?) 中的 (?:\.\d+)?:
這裡有兩個「?」但功能不同:
- (?: … ) 裡面的「?:」是「非捕獲群組」的語法記號,不是量詞。它只代表「分組但不產生 group 編號」。
- 末尾的「)?」這個「?」才是量詞,表示「整個群組可有可無(0 或 1 次)」。
所以 (?:\.\d+)? 的意思是:
- 非捕獲群組 (?:\.\d+):一個「小數點 + 至少一位數字」
- 後面的 ?:讓這整段小數部分變成可選(0 或 1 個)
等價寫法(用捕獲群組也行):
- (\.\d+)? 也是「小數部分可選」
推薦hahow線上學習python: https://igrape.net/30afN
)")
 ; os.path.dirname( os.path.abspath( __file__ ))")

![Word短篇文件編輯,TQC考題110:重點摘要與評量, \[(*)\] 萬用字元,格式>醒目提示*2次=非醒目提示](https://i2.wp.com/savingking.com.tw/wp-content/uploads/2022/03/20220322172253_75.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Word短篇文件編輯,TQC考題110:重點摘要與評量, \[(*)\] 萬用字元,格式>醒目提示*2次=非醒目提示")


")
 增加新的一欄? model = tensorflow.keras.models.Sequential() #均一化資料")
, candidates, n=1, cutoff=0.6)")


近期留言