import pandas as pd
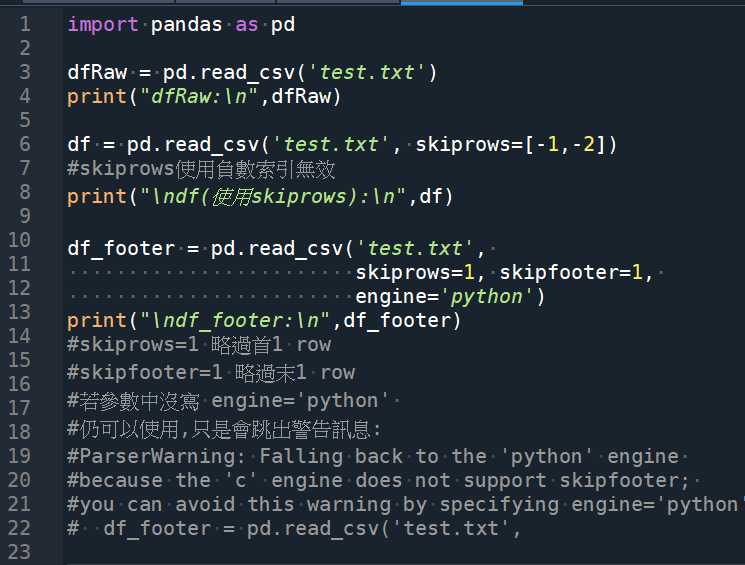
dfRaw = pd.read_csv(‘test.txt’)
print(“dfRaw:\n”,dfRaw)
df = pd.read_csv(‘test.txt’, skiprows=[-1,-2])
#skiprows使用負數索引無效
print(“\ndf(使用skiprows):\n”,df)
df_footer = pd.read_csv(‘test.txt’,
skiprows=1, skipfooter=1,
engine=’python’)
print(“\ndf_footer:\n”,df_footer)
“””
#skiprows=1 略過首1 row
#skipfooter=1 略過末1 row
#若參數中沒寫 engine=’python’
#仍可以使用,只是會跳出警告訊息:
#ParserWarning: Falling back to the ‘python’ engine
#because the ‘c’ engine does not support skipfooter;
#you can avoid this warning by specifying engine=’python’.
# df_footer = pd.read_csv(‘test.txt’,
engine='python'是因为默认情况下
Pandas使用的是C引擎解析CSV文件,
而skipfooter参数需要使用Python引擎才能生效。
“Footer” 可以翻譯為 “頁腳”,通常指網頁底部的區域,
包含版權聲明、聯絡資訊、隱私政策等相關資訊。”””
輸出結果:

0-indexed 是指从0开始编号,而不是从1开始编号。在 Python 中,许多数据类型都是从0开始编号的,比如列表、字符串、元组等等。因此,当我们使用pandas中的skiprows参数时,需要将要跳过的行数按照行号从0开始进行指定。
推薦hahow線上學習python: https://igrape.net/30afN


 as file: for line in file: for w in line.split()")
 ; os.path.dirname( os.path.abspath( __file__ ))")
垂直位置教學: rank=’sink’ ; rank=’source’ ; rank=’same’ ; 為子圖的屬性,在node中設定無效 ; 不可與g.attr(newrank=’true’) #子圖同高度 一起使用; with g.subgraph() as s: s.attr(rank=’sink’) # 設置子圖為sink ; s.node(‘Logo’, ‘Company Logo’)")

 vs iterrows() ; for row in df.itertuples ( index=False, name=None)")
; dict(key)提取dict內的元素; importlib.reload(); np.zeros(); np.array()")
![Python 表達式中的魔法:用海象運算子讓斷詞程式碼更乾淨 [w_clean for w in words if (w_clean:=w.lower().strip()) and w_clean not in STOPWORDS]](https://i1.wp.com/savingking.com.tw/wp-content/uploads/2026/02/20260210083748_0_a7d9bf.png?quality=90&zoom=2&ssl=1&resize=350%2C233 "Python 表達式中的魔法:用海象運算子讓斷詞程式碼更乾淨 [w_clean for w in words if (w_clean:=w.lower().strip()) and w_clean not in STOPWORDS]")
![Python struct.pack() 將整數轉換為bytes ; while list: str1=list[0] ; 中間內容; list=[1:] #切片 ,遍歷list中的每一個元素,跟for i in list 類似 ; timeit() #計時 - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2022/10/20221012095050_42-520x245.png)

近期留言