Python相關網址 by 儲蓄保險王 · 2022-10-15 https://www.python-excel.org https://www.xlwings.org/ 相關文章Python: 如何用seaborn (sns) 套件繪製具有多個子圖的折線圖? sns.relplot(data=tips, x=’total_bill’, y=’tip’, hue=’sex’, col=’day’, row=’time’, facet_kws={‘margin_titles’: True}, height=3, aspect=1.2).set_axis_labels(‘Total Bill’, ‘Tip’)Python: 三個不同長度 pandas.DataFrame 的資料如何繪製在同一張散佈圖?WORD合併列印:TQC考題506,薪資明細表,切換功能變數代碼(shift +F9),Skip Record IfPython 現代化路徑管理:用 pathlib 一行搞定 os.mkdir 與 os.makedirs; log_dir.mkdir(parents=True, exist_ok=True)word:合併列印無框行動(Circles.Life):台灣龍頭電信線路466吃到飽(不限速,不綁約,免預繳),吃不完還給你,月租最低只要166,養門號都划算;輸入推薦碼 L672PMU5 就送連續6個月帳單折抵$100,等同$450上網吃到飽6個月;無框出任務:有機會獲得100元帳單減免Python 非監督式機器學習: 關聯規則; 使用 mlxtend ; 購物欄分析 ; from mlxtend.preprocessing import TransactionEncoderPython: 如何進行測試流程的黑名單過濾Word圖文編輯,TQC考題310:福袋,滑鼠右鍵>格式化圖案,格式>圖案樣式 展開>最右邊圖示 版面配置與內容>左,右,上,下 邊界
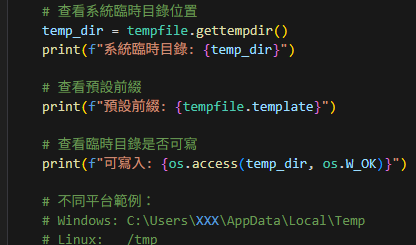
0 Python tempfile 模組完全指南:安全管理臨時檔案的最佳實踐; import tempfile ; tempfile.gettempdir() ; tempfile.template ; os.access(temp_dir, os.W_OK) ; with tempfile.NamedTemporaryFile() as tmp: tmp_path = tmp.name #有檔名的臨時檔案 ; with tempfile.TemporaryDirectory() as tmpdir #臨時資料夾 ; with tempfile.TemporaryFile() as tmp #無檔名的臨時檔案 2025-11-19
0 Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc=’upper left’, bbox_to_anchor=(6/10, 3/5) 2023-05-01

 套件繪製具有多個子圖的折線圖? sns.relplot(data=tips, x=’total_bill’, y=’tip’, hue=’sex’, col=’day’, row=’time’, facet_kws={‘margin_titles’: True}, height=3, aspect=1.2).set_axis_labels(‘Total Bill’, ‘Tip’)")

,Skip Record If")
")

:台灣龍頭電信線路466吃到飽(不限速,不綁約,免預繳),吃不完還給你,月租最低只要166,養門號都划算;輸入推薦碼 L672PMU5 就送連續6個月帳單折抵$100,等同$450上網吃到飽6個月;無框出任務:有機會獲得100元帳單減免")



![Python: matplotlib如何控制legend的位置? ax.legend(handles=[patch], loc='upper left', bbox_to_anchor=(6/10, 3/5) - 儲蓄保險王](https://savingking.com.tw/wp-content/uploads/2023/05/20230502163945_79-520x245.png)
近期留言